|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
FTS5 это SQLite виртуальный модуль таблицы,
который предоставляет
полнотекстовую функциональность поиска приложениям базы данных.
В их самой элементарной форме полнотекстовые поисковые системы позволяют
пользователю эффективно искать большое количество документов для
подмножества, которые содержат один или несколько случаев критерия поиска.
Функциональность поиска, предоставленная пользователям Всемирной паутины
Google является, среди прочего,
полнотекстовой поисковой системой, поскольку это позволяет пользователям
искать все документы в сети, которые содержат, например, термин "fts5". Чтобы использовать FTS5, пользователь составляет виртуальную таблицу FTS5
с одной или более колонками. Например: Ошибка добавить типы, ограничения или декларации
PRIMARY KEY в
CREATE VIRTUAL TABLE при создании таблицы FTS5.
После того как создана, таблица FTS5 может быть наполнена, используя
INSERT, UPDATE
или DELETE, как любая другая таблица.
Как у любой другой таблицы без декларации PRIMARY KEY, у таблицы FTS5 есть
неявное поле INTEGER PRIMARY KEY с именем rowid. Не показано в примере выше то, что есть также
опции,
которые могут быть предоставлены FTS5 как часть CREATE VIRTUAL TABLE,
чтобы формировать различные аспекты новой таблицы. Они могут использоваться,
чтобы изменить путь, которым таблица FTS5 извлекает термины
из документов и запросов, чтобы создать дополнительные индексы на диске,
чтобы ускорить запросы префикса или составить таблицу FTS5, которая действует
как индекс на содержании, сохраненном в другом месте. После того, как наполнена, есть три способа выполнить полнотекстовый
запрос для содержания таблицы FTS5: Используя MATCH или =, выражение налево от оператора MATCH обычно название
таблицы FTS5 (исключение:
определяя вертикальный фильтр).
Выражение справа должно быть текстовым значением, определяющим термин, чтобы
искать. Для табличного синтаксиса функций термин, чтобы искать определяется
как первый аргумент таблицы. Например: По умолчанию полнотекстовые поиски FTS5 независимы от регистра.
Как любой другой SQL-запрос, который не содержит пункт ORDER BY, пример выше
вернет результаты в произвольном порядке. Для сортировки уместностью
ORDER BY может быть добавлен к полнотекстовому запросу следующим образом: А также значения столбцов и rowid соответствующей
строки, применение может использовать
вспомогательные функции FTS5,
чтобы восстановить дополнительную информацию относительно подобранной
строки. Например, вспомогательная функция может использоваться, чтобы
восстановить копию значения столбца для подобранной
строки со всеми случаями подобранного термина, окруженного HTML-тэгом
<b></b>. Вспомогательные функции вызваны таким же образом, как
SQLite скалярные функции,
за исключением того, что название таблицы FTS5 определяется как
первый аргумент. Например: Описание доступных вспомогательных функций и больше деталей относительно
конфигурации специальной колонки "rank" есть
здесь.
Свои вспомогательные функции
могут также быть осуществлены на C и зарегистрированы в FTS5, так же,
как функции SQL могут быть зарегистрированы в ядре SQLite. А также ища все строки, которые содержат термин, FTS5 позволяет
пользователю искать строки, которые содержат: Такой расширенный поиск требуют, обеспечивая более сложную строку запроса
FTS5 как текст справа от оператора MATCH (или =, или как первый аргумент
табличного синтаксиса функций). Полный синтаксис запроса
описан здесь. С version 3.9.0 (2015-10-14) FTS5
включен как часть SQLite объединения.
Используя одну из двух autoconf систем сборки, FTS5 позволен, определив
опцию "--enable-fts5" скрипта configure. FTS5 в настоящее время отключается
по умолчанию для скрипта configure исходного дерева
и позволен по умолчанию для скрипта configure объединения,
но эти умолчания могли бы измениться в будущем. Или, если sqlite3.c собран, используя некоторую другую систему сборки,
приняв меры, чтобы символ препроцессора SQLITE_ENABLE_FTS5 был определен. Альтернативно, FTS5 может быть построен как загружаемое расширение. Канонический исходный код FTS5 состоит из серии *.c и других файлов в
каталоге "ext/fts5" исходного дерева SQLite. Процесс сборки уменьшает это
всего до двух файлов, "fts5.c" и "fts5.h", которые могут использоваться,
чтобы построить загружаемое расширение SQLite. Код в "fts5.c" может тогда быть собран в загружаемое расширение или
статически связан, как описано здесь.
Есть две определенные точки входа, обе из которых делают то же самое: Другой файл, "fts5.h", не требуется, чтобы собирать
расширение FTS5. Это используется запросами, которые осуществляют
свои токенизаторы FTS5
или вспомогательные функции. Следующий блок содержит резюме синтаксиса запроса FTS в форме BNF.
Подробное объяснение следует. В выражении FTS последовательность может быть определена одним
из двух способов: Представляя ее в двойных кавычках ("). В последовательности
любые вложенные знаки двойной кавычки можно экранировать через
SQL-стиль: добавив второй символ двойной кавычки. Как термин FTS5, который не является "AND", "OR" или "NOT"
(чувствительный к регистру). Термин FTS5 это последовательность из одного
или более последовательных символов, которые являются одним из: Каждая последовательность в запросе fts5 разобрана ("размечена")
токенизатором
и представлена списком из ноля или больше символов.
Например, токенизатор по умолчанию размечает последовательность "alpha
beta gamma" на три разных токена "alpha", "beta" и "gamma" в этом порядке. Запросы FTS составлены из фраз. Фраза это
список из одного или более символов. Символы от каждой последовательности в
запросе составляют единственную фразу.
Две фразы могут быть связаны в единственную большую фразу, используя оператор
"+". Например, предположим, что токенизатор используемого модуля
размечает вход "one.two.three" к трем отдельным символам.
Следующие четыре запроса все определяют ту же самую фразу: Фраза соответствует документу, если документ содержит по крайней мере одну
подпоследовательность символов, которая соответствует последовательности
символов, которые составляют фразу. Если символ "*" следует за последовательностью в выражении FTS,
то заключительный символ, извлеченный из последовательности, отмечен как
символ префикса. Как вы могли бы ожидать, символ префикса
соответствует любому символу документа.
Например, первые два запроса в следующем блоке будут соответствовать любому
документу, который содержит символ "one" немедленно сопровождаемый символом
"two" и затем любым символом, который начинается с "thr". Заключительный запрос в блоке выше может не работать как ожидалось.
Поскольку символ "*" в двойных кавычках, он будет передан к
токенизатор, который будет, вероятно, отказываться от него (или возможно, в
зависимости от определенного токенизатора, включать его как часть
заключительного символа) вместо того, чтобы признать его
специальным символом FTS.
Если символ "^" немедленно появляется перед фразой, которая не
является частью запроса NEAR, то та фраза только соответствует документу,
только если начинается в первом символе в колонке. Символ "^" может быть
объединен с вертикальным фильтром
, но не может быть вставлен в середину фразы. Две или больше фразы могут быть сгруппированы в группу NEAR.
Группа NEAR определяется символическим "NEAR" (чувствительным к
регистру) сопровождаемым символом открывающей скобки, сопровождаемым двумя
или больше разделенными пробелами фразами, произвольно сопровождаемые запятой
и числовым параметром N, сопровождаемым круглой
закрывающей скобкой. Например: Если N не задан, по умолчанию это 10. Группа NEAR
соответствует документу, если документ содержит по крайней мере один
блок символов, которые: Например: Единственная фраза или группа NEAR могут быть ограничены совпавшим текстом
в рамках указанной колонки таблицы FTS, указав префикс
с именем столбца, сопровождаемым символом двоеточия. Или рядом колонок,
тогда префиксом будет список имен столбцов, разделенных пробелами, в
фигурных скобках, сопровождаемые символом двоеточия. Имена столбцов могут
быть определены, используя любую из двух форм, описанных для
последовательностей выше. В отличие от последовательностей, которые
являются частью фраз, имена столбцов не передаются токенизатору.
Имена столбцов нечувствительные к регистру обычным способом SQLite
верхний/lнижний регистры поняты только для знаков диапазона ASCII. Если спецификации вертикального фильтра предшествует символ "-",
это интерпретируется как список колонок, которым
не соответствовать. Например: Технические требования вертикального фильтра могут также быть применены к
произвольным выражениям, приложенным в скобках. В этом случае вертикальный
фильтр относится ко всем фразам в выражении. Вложенные операции по
вертикальному фильтру могут только далее ограничить подмножество подобранных
колонок, они не могут использоваться, чтобы повторно позволить уже
отфильтрованные колонки. Например: Наконец, вертикальный фильтр для отдельного столбца может быть определен
при помощи имени столбца как LHS в операторе MATCH (вместо обычного
имени таблицы). Например: Фразы и группы NEAR могут быть сгруппированы в выражения, используя
операторы boolean. В порядке предшествования, от самого высокого
приоритета к самому низкому это: Скобка может использоваться в выражениях группы, чтобы изменить
порядок операторов обычными способами. Например: Фразы и группы NEAR могут также быть связаны неявными операциями AND
. Для простоты их не показывают в грамматике BNF выше. По существу любая
последовательность фраз или групп NEAR (включая ограниченных соответствием
указанным колонкам) разделена только пробелами и
обработана, как будто была неявная операция AND
между каждой парой групп NEAR или фраз. Неявные операции AND
никогда не вставляются после или прежде скобок.
Неявная группа операций AND более приоритетна, чем все другие операторы,
включая NOT, например: Каждый аргумент, определенный как часть "CREATE VIRTUAL TABLE ... USING
fts5 ...", является декларацией колонки или параметром конфигурации.
Декларация колонки состоит из отделенных пробелами одного или
нескольких слов FTS5 или строковых литералов, указанных любым способом,
приемлемым для SQLite. Первая последовательность в декларации колонки это имя столбца.
Ошибка попытаться назвать столбец таблицы fts5 "rowid", "rank"
или назначить колонке то же самое имя, как используется самой таблицей.
Это не поддерживается. Каждая последующая последовательность в декларации колонки это
опция, которая изменяет поведение той колонки.
Опции независимы от регистра. В отличие от ядра SQLite, FTS5 полагает,
что непризнанные опции столбца это ошибки.
В настоящее время единственным признанным выбором является
"UNINDEXED". Параметр конфигурации состоит из слов FTS5, имени параметра,
сопровождаемого символом "=", и значением.
Значение выбора определяется, используя строковый литерал, указанный любым
способом, приемлемым для ядра SQLite. Например: В настоящее время есть следующие параметры конфигурации: Содержание колонок, квалифицированных с опцией столбца UNINDEXED, не
добавляется к индексу FTS. Это означает, что в целях запросов MATCH и
вспомогательных функций FTS5
колонка не содержит совпадающих символов. Например, чтобы избежать добавлять содержание поля "uuid" в индекс FTS: По умолчанию FTS5 поддерживает единственный индекс, делающий запись
местоположения каждого символического случая в наборе документов.
Это означает, что запрос для полных символов быстр,
поскольку требует единственного поиска, но запрос
для символа префикса может быть медленным, поскольку требует просмотра
диапазона. Например, чтобы запросить для символа префикса "abc*"
требуется просмотр диапазона всех символов, больше или равных "abc",
но меньше "abd". Индекс префикса это отдельный индекс, который делает запись местоположения
всех случаев символов префикса определенной длины в знаках, используемых,
чтобы ускорить запросы для символов префикса. Например, оптимизация запроса
для символа префикса "abc*" требует индекса трехсимвольных префиксов. Чтобы добавить индексы префикса к таблице FTS5, опция "prefix"
установлена в единственное положительное целое число или в текстовое
значение, содержащее отделенный пробелами список из одного или более
положительных целочисленных значений.
Индекс префикса создается для каждого определенного целого числа.
Если больше, чем один выбор "prefix" определяется как часть единственного
CREATE VIRTUAL TABLE, применяются все. Опция CREATE VIRTUAL TABLE "tokenize"
используется, чтобы формировать определенный токенизатор, используемый
таблицей FTS5. Аргумент выбора должен быть текстовым литералом SQL.
Текст аргумента самостоятельно рассматривают как серию слов, разделенных
пробелами. Первым из них является название токенизатора, чтобы использовать.
Вторые и последующие элементы списка, если они существуют, являются
аргументами, переданными токенизатору. В отличие от имен столбцов, литералы SQL предназначенные токенизатору,
должны быть указаны, используя знаки одинарной кавычки. Например: FTS5 показывает три встроенных модуля токенизаторов,
описанные в последующих секциях: Также возможно создать свои токенизаторы для FTS5. API для того, чтобы
сделать это, приведено здесь. Токенизатор unicode классифицирует все unicode-знаки как
"separator" или "token". По умолчанию все пробелы и символы пунктуации, как
определено Unicode 6.1, считают сепараторами, а все другие знаки как
символические знаки. Более определенно все unicode-знаки, назначенные на
general category, начинающуюся с "L" или "N" (letters и numbers)
или на категорию "Co" ("other, private use"), считают символами.
Все другие знаки это сепараторы. Каждое вхождение одного или более символических знаков считается символом.
Токенизатор нечувствительный к регистру согласно
правилам, определенным Unicode 6.1. По умолчанию диакритические знаки удалены от всех латинских символов.
Это означает, например, что "A", "a", "À", "à", "Â" и
"â" считаются эквивалентными. Любые аргументы после "unicode61"
в символической спецификации рассматривают как список переменных имен
выбора и значений. Unicode61 поддерживает следующие варианты: Например: Или: Токенизатор fts5 unicode61 tokenizer
совместим с токенизатором fts3/4 unicode61. Токенизатор Ascii похож на Unicode61 кроме: Например: Токенизатор porter это оболочка. Это берет вывод другого токенизатора и
применяет алгоритм
porter stemming к каждому символу, прежде чем это возвратит его к FTS5.
Это позволяет распознавать подобные слова, такие критерии поиска, как
"corrected" или "correcting". Алгоритм porter stemmer
разработан для использования только с английскими языковыми условиями.
Использование этого с другими языками
может не улучшить полезность поиска. По умолчанию porter действует в качестве обертки вокруг токенизатора
(unicode61). Или, если один или несколько дополнительных аргументов
добавляются к опции "tokenize", их рассматривают как спецификацию для
основного токенизатора, который использует porter stemmer: Токенизатор trigram расширяет FTS5, чтобы поддержать подстроку,
соответствующую в целом вместо обычного символического соответствия.
Используя токенизатор trigram, запрос или символ фразы может соответствовать
любой последовательности знаков в строке, не только
полному символу. Например: Токенизатор trigram поддерживает единственный выбор "case_sensitive".
Со значением по умолчанию 0 соответствие нечувствительно к регистру.
Если это значение установлено в 1, то все
соответствия чувствительны к регистру. Таблицы FTS5, которые используют trigram, также поддерживают
соответствие шаблонам GLOB и LIKE: Если FTS5 токенизатор trigram создается с case_sensitive = 1,
это может внести в указатель только запросы GLOB, но не LIKE. Замечания: Обычно, когда строка вставляется в таблицу FTS5, в дополнение к созданию
индекса, FTS5 делает копию оригинального содержания строки. Когда значения
столбцов требует от таблицы FTS5 пользователь или реализация вспомогательной
функции, те значения прочитаны из той частной копии содержания.
Выбор "content" может использоваться, чтобы составить таблицу FTS5, которая
хранит только полнотекстовые элементы индекса FTS.
Поскольку сами значения столбцов обычно намного больше, чем связанные
полнотекстовые элементы индекса, это может оставить значительное свободное
место базы данных. Есть два способа использовать выбор "content": Таблица contentless FTS5 создается, устанавливая выбор "content"
в пустую строку. Например: Таблицы Contentless FTS5 не поддерживают UPDATE или DELETE, а также
INSERT, которые не поставляют ненулевое значение для rowid.
Таблицы Contentless не поддерживают обработку конфликта REPLACE.
Операторы REPLACE и INSERT OR REPLACE рассматривают как регулярные операторы
INSERT. Строки могут быть удалены из contentless-таблицы, используя
команду FTS5 delete. Попытка прочитать любое значение столбца кроме rowid от таблицы
contentless FTS5 возвращает SQL NULL.
С version 3.43.0 также есть таблицы contentless-delete.
Таблица contentless-delete составлена, установив выбор содержания в пустую
строку и также установив contentless_delete = 1: Таблица contentless-delete отличается от contentless следующим: Если совместимость не требуется, новый код должен предпочесть
таблицы contentless-delete. Внешнее содержание таблицы FTS5 создается, устанавливая выбор content
в название таблицы, виртуальной таблицы или представления (далее
"таблица содержания") в той же самой базе данных. Каждый раз, когда
значения столбцов требуются FTS5, он запрашивает таблицу содержания
следующим образом с rowid строки, для которой значения требуются,
связанные с переменной SQL: В вышеупомянутом <content> заменяется названием таблицы содержания.
По умолчанию <content_rowid> заменяется буквенным текстом
"rowid". Или, если "content_rowid"
установлен в CREATE VIRTUAL TABLE, значением этой опции.
<cols> заменяются списком разделенных запятой значений названий
столбца таблицы FTS5. Например: Таблица содержания может также быть запрошена следующим образом: Все еще обязанность пользователя гарантировать, что внешнее содержание
таблица FTS5 соответствует таблице содержания. Один способ сделать
это с триггерами. Например: Как contentless-таблицы, внешние таблицы содержания не поддерживают
обработку конфликта REPLACE. Любые операции, которые определяют обработку
конфликта REPLACE, обработаны, используя ABORT. Обязанность пользователя гарантировать, что внешняя
таблица содержания FTS5 (одна из таблиц с непустым значением content=)
сохранена согласовываясь с таблицей содержания (таблица, названная в
content=). Если им позволяют стать непоследовательными, то результаты
запросов для таблицы FTS5 могут стать
неинтуитивными и казаться непоследовательными. В этих ситуациях по-видимому непоследовательные результаты, приведенные
запросами для внешней таблицы содержания FTS5, могут быть
поняты следующим образом: Если запрос не использует полнотекстовый индекс,
не содержит оператора MATCH или эквивалентный табличный синтаксис функций,
тогда, через запрос эффективно проходят к внешней таблице
содержания. В этом случае содержание индекса FTS не имеет никакого эффекта
на результаты запроса. Если запрос действительно использует полнотекстовый индекс, то модуль
FTS5 запрашивает его для набора значений rowid, соответствующих документам,
которые соответствуют запросу. Для каждого такого rowid это тогда управляет
запросом, подобным следующему, чтобы восстановить какие-либо необходимые
значения столбцов, где '?' заменяется значением rowid, а <content> и
<content_rowid> значениями, определенными для
content= и content_rowid=: Например, если база данных создается, используя следующий скрипт: таблица содержания содержит две строки, но индекс FTS не содержит записей,
соответствующих им. В этом случае следующие запросы возвратят
непоследовательные результаты следующим образом: Альтернативно, если база данных была создана и
наполнена следующим образом: таблица содержания пуста, но индекс FTS содержит записи для 6 различных
символов. В этом случае следующие запросы возвратят непоследовательные
результаты следующим образом: Как описано в предыдущей секции, триггеры
на таблице содержания это хороший способ гарантировать, что внешняя таблица
содержания FTS5 сохранена последовательной. Однако, триггеры запущены
только когда строки вставлены, обновлены или удалены в таблице содержания.
Это означает, что если, например, база данных создается следующим образом: тогда таблица содержания и таблица внешнего содержания FTS5
непоследовательны, поскольку созданные триггеры
не копируют существующие строки таблицы содержания в индекс FTS.
Триггеры только в состоянии гарантировать, что обновления, сделанные к
таблице содержания после того, как она создается, отражены в индексе FTS. В этой и любой другой ситуации, где индекс FTS и его таблица содержания
стали непоследовательными, команда 'rebuild'
может использоваться, чтобы полностью отказаться от содержания индекса
FTS и восстановить его на основе текущего содержания таблицы содержания. Обычно FTS5 поддерживает специальную таблицу поддержки в базе данных,
которая хранит размер каждого значения столбца в символах, вставленных в
главную таблицу FTS5, в отдельной таблице. Эта таблица поддержки используется
функцией API xColumnSize,
которая в свою очередь используется встроенной
функцией рейтинга bm25
(и, вероятно, будет полезна также для других функций рейтинга). Чтобы оставить свободное место, эта таблица поддержки может быть
опущена, установив columnsize = 0: Ошибка установить columnsize в любое значение кроме 0 или 1. Если таблица FTS5 формируется с columnsize=0, но не является
contentless, xColumnSize API
все еще работает, но намного более медленно. В этом случае, вместо того,
чтобы читать значение, чтобы возвратить,
непосредственно из базы данных, это читает текстовое значение
и считает символы в нем по требованию.. Или, если таблица также
contentless, то следующее применяется: xColumnSize API всегда вернет -1.
Нет никакого способа определить количество символов в значении, сохраненном в
таблице contentless FTS5, формируемой с columnsize=0. Каждая вставленная строка должна сопровождаться явно указанным
значением rowid. Если contentless-таблица формируется с columnsize=0,
попытка вставить NULL в rowid вызовет ошибку SQLITE_MISMATCH. Все запросы на таблице должны быть полнотекстовыми запросами.
Другими словами, они должны использовать MATCH или оператор = с колонкой
имени таблицы как левый операнд или иначе использовать табличный синтаксис
функций. Любой запрос, который не является полнотекстовым, вызовет ошибку.
Название таблицы, в которой сохранены значения xColumnSize (если
columnsize=0 не определяется), "<name>_docsize", где
<name> это название самой таблицы FTS5.
sqlite3_analyzer
может использоваться на существующей базе данных, чтобы определить,
сколько свободного места могло бы быть оставлено,
воссоздав таблицу FTS5, используя columnsize=0. Для каждого термина в документе индекс FTS, сохраняемый FTS5, хранит rowid
документа, номер столбца колонки, которая содержит термин и смещение
термина в значении столбца. Выбор "detail" может использоваться, чтобы
опустить часть этой информации. Это уменьшает место, которое индекс занимает
в файле базы данных, но также уменьшает эффективность системы. Опция detail может быть "full" (по умолчанию), "column" или "none": Если выбор detail = column, то для каждого термина индекс FTS
делает запись только rowid и номера столбца, опуская информацию о смещении
термина. Это приводит к следующим ограничениям: Если выбор detail установлен в none,
то для каждого термина в записи индекса FTS сохранен просто rowid.
Колонка и информация о смещении опущены. Ограничения, перечисленные выше для
detail=column, действуют, но налагает
следующие дополнительные ограничения: В одном тесте, который внес большой набор в указатель электронных писем
(1636 MB на диске), индекс FTS был 743 MB на диске с detail=full, 340 MB с
detail=column и 134 MB с detail=none. Вспомогательные функции подобны
скалярным функциям SQL, за исключением того, что они могут использоваться
только в полнотекстовых запросах (те, которые используют оператор MATCH)
на таблице FTS5. Их результаты вычисляются, базируясь не только на
аргументах, переданных им, но и на текущем соответствии и подобранной
строке. Например, вспомогательная функция может возвратить числовое значение,
указывающее на точность соответствия (см. функцию
bm25()) или фрагмент текста от
подобранной строки, который содержит один или несколько случаев критериев
поиска (см. функцию
snippet()). Чтобы вызвать вспомогательную функцию, название таблицы FTS5 должно быть
определено как первый аргумент. Другие аргументы могут следовать за первым, в
зависимости от определенной вспомогательной призываемой функции. Например,
чтобы вызвать функцию "highlight": Встроенные вспомогательные функции, обеспеченные как часть FTS5, описаны
в следующем разделе. Запросы могут также осуществить
свои вспомогательные функции
на C. FTS5 обеспечивает три встроенных вспомогательных функции: Встроенная вспомогательная функция bm25()
возвращает действительное значение, указывающее, как хорошо текущая
строка соответствует полнотекстовому запросу. Лучшее соответствие имеет
численно меньшее возвращенное значение. Запрос, такой как следующий, может
быть применен, чтобы вернуть соответствия в порядке от лучшего к худшему: Чтобы вычислить счет документов, полнотекстовый запрос разделен на его
составляющие фразы. Счет bm25 для документа D и запроса Q
вычисляется следующим образом: nPhrase количество фраз в запросе. |D| является количеством
символов в текущем документе. avgdl среднее количество символов во
всех документах в таблице FTS5. k1 и b это
константы, жестко закодированные в 1.2 и 0.75 соответственно. Термин "-1" в начале формулы не найден в большинстве внедрений алгоритма
BM25. Без него лучшему совпадению назначен численно выше счет BM25.
Так как порядок сортировки по умолчанию "ascending",
это означает, что добавление "ORDER BY bm25(fts)"
к запросу заставило бы результаты быть возвращенными в порядке
от худшего до лучшего. Ключевое слово "DESC" требовалось бы, чтобы возвратить
лучшие соответствия сначала. Чтобы избежать этой ловушки, внедрение FTS5 BM25
умножает результат на -1 прежде, чем возвратить, гарантируя, что лучшим
соответствиям назначают численно более низкие очки. IDF(qi) является обратной частотой документа фразы
запроса i. Вычисляется следующим образом, где N общее
количество строк в таблице FTS5, а n(qi) это общее
количество строк, которые содержат по крайней мере один случай фразы
i: Наконец f(qi,D) частота фразы i.
По умолчанию это просто количество случаев фразы в текущей строке.
Однако, передавая дополнительные аргументы действительного значения
bm25(), каждой колонке таблицы можно назначить различный вес и частоту
фразы, вычисленную следующим образом: где wc вес, назначенный на колонку c, и
n(qi,c) количество случаев фразы i в колонке
c текущей строки. Первым аргументом, переданным к bm25()
после имени таблицы, является вес, назначенный на крайний левый столбец
таблицы FTS5. Вторым является вес, назначенный на второй слева столбец и так
далее. Если есть недостаточно аргументов для всех столбцов таблицы, остальным
столбцам назначают вес 1.0. Если есть слишком много аргументов,
лишние проигнорированы. Например: Обратитесь к Википедии
для получения
дополнительной информации относительно BM25. Функция highlight() возвращает копию текста из указанной колонки текущей
строки с дополнительным текстом разметки, вставленным, чтобы отметить начало
и конец соответствий фразы. highlight() должен быть вызван точно с тремя аргументами после имени
таблицы. Интерпретироваться они будут следующим образом: Например: В случаях, где два или больше случая фразы накладываются (разделяют один
или несколько символов вместе), единственный маркер
вставляется для каждого набора накладывающихся фраз. Например: Функция snippet() подобна highlight(),
за исключением того, что вместо того, чтобы возвратить все значения столбцов,
это автоматически выбирает и извлекает короткий фрагмент текста документа,
чтобы обработать и возвратить. Функции должно быть передано пять параметров
после аргумента имени таблицы: Все таблицы FTS5 включают специальный скрытый столбец, названный "rank".
Если текущий запрос это не полнотекстовый запрос (то есть, если он не
включает оператор MATCH), значение колонки "rank" всегда NULL.
Иначе, в полнотекстовом запросе, rank содержит по умолчанию то же самое
значение, какое было бы возвращено, выполнив bm25() без аргументов. Различие между чтением из колонки rank и использованием bm25()
непосредственно в запросе только при сортировке возвращенных значений.
В этом случае использование "rank" быстрее bm25(). Вместо того, чтобы использовать bm25() без аргументов, определенная
вспомогательная функция, отображающая колонку rank,
может формироваться на основе запроса или устанавливая различное постоянное
умолчание для таблицы FTS. Чтобы изменить отображение колонки rank для единого запроса, термин,
подобный любому из следующего, добавляется к оператору WHERE запроса: Правая сторона MATCH или = должна быть константным выражением, которое
оценивают к последовательности, состоящей из вспомогательной функции, чтобы
вызвать, сопровождая нулем или больше разделенных запятыми
аргументов в скобках. Аргументы должны быть литералами SQL. Например: Табличный синтаксис функций может также использоваться, чтобы определить
альтернативную функцию рейтинга. В этом случае текст, описывающий занимающую
место функцию, должен быть определен как второй табличный аргумент функции.
Следующие три запроса эквивалентны: Отображение по умолчанию колонки rank
для таблицы может быть изменено, используя
опцию настройки FTS5 rank. Вместо того, чтобы использовать единственную структуру данных на диске,
чтобы сохранить полнотекстовый индекс, FTS5 использует серию b-деревьев.
Каждый раз, когда новая транзакция передается, новое b-дерево, содержащее
содержание переданной транзакции, написано в файл базы данных.
Когда полнотекстовый индекс запрашивается, каждое b-дерево должно быть
запрошено индивидуально и результаты слиты прежде,
чем возвратить пользователю. Чтобы предотвратить слишком большое количество b-деревьев в базе данных
(замедляет запросы), меньшие b-деревья периодически сливаются в единственные
большие b-деревья, содержащие те же самые данные. По умолчанию это происходит
автоматически в INSERT, UPDATE или DELETE, которые изменяют полнотекстовый
индекс. Параметр 'automerge' определяет, сколько меньших b-деревьев слито
вместе за один раз. Урегулирование его к маленькой значении может ускорить
запросы (поскольку они должны запросить и слить следствия меньшего количества
b-деревьев), но может также замедлить запись базы данных (каждый INSERT,
UPDATE или DELETE должен сделать больше работы как часть
автоматического процесса слияния). Каждое из b-деревьев, которые составляют полнотекстовый индекс,
назначено на "level" на основе его размера. B-деревья уровня 0 являются
самыми маленькими, поскольку они содержат содержание единственной транзакции.
Высокоуровневые b-деревья это результат слияния двух или больше b-деревьев
уровня 0 вместе и таким образом, они больше. FTS5 начинает сливать b-деревья
вместе, как только там существуют M
или больше b-деревьев с тем же самым уровнем, где M это значение
параметра 'automerge'. Максимальное позволенное значение для параметра 'automerge' 16.
Значение по умолчанию равняется 4. Урегулирование параметра
'automerge' = 0 отключает автоматическое возрастающее
слияние b-деревьев в целом. 'crisismerge' аналогично 'automerge', в котором он определяет, как
часто составляющие b-деревья, которые составляют полнотекстовый индекс, слиты
вместе. Когда есть C или больше b-деревьев на единственном уровне в
полнотекстовом индексе, где C это значение 'crisismerge',
все b-деревья на уровне немедленно слиты в единственное b-дерево. Различие между этим выбором и 'automerge' в том что, когда предел
'automerge' достигнут, FTS5 только начинает сливать b-деревья вместе.
Большая часть работы выполняется как часть последующего INSERT, UPDATE или
DELETE. Когда предел 'crisismerge' достигнут, все b-деревья немедленно слиты.
Это означает, что INSERT, UPDATE или DELETE, который вызывает слияние, может
занять много времени. По умолчанию 'crisismerge' = 16. Нет никакого максимального предела.
Попытка установить 'crisismerge' в 0 или 1 эквивалентна установке
его к значению по умолчанию (16). Ошибка попытаться установить
'crisismerge' в отрицательную величину. Эта команда только доступна с
внешним содержанием и contentless
-таблицами. Это используется, чтобы удалить элементы индекса, связанные с
единственной строкой из полнотекстового индекса. Эта команда и
delete-all
являются единственными способами удалить записи из полнотекстового
индекса contentless-таблицы. Чтобы использовать эту команду, чтобы удалить строку, текстовое значение
'delete' должно быть вставлено в специальную колонку с тем же самым именем,
как таблица. rowid строки, чтобы удалить, вставляется в колонку rowid.
Значения, вставленные в другие колонки, должны соответствовать значениям,
в настоящее время хранящимся в таблице. Например: Если значения, "вставленные" в столбцы текста как часть команды
'delete', не являются теми же самыми, как в настоящее время хранящиеся в
таблице, результаты могут быть непредсказуемыми. Причину этого легко понять: Когда документ вставляется в таблица FTS5,
вход добавляется к полнотекстовому индексу, чтобы сделать запись положения
каждого символа в рамках нового документа.
Когда документ удален, оригинальные данные требуются, чтобы определить набор
записей, которые должны быть удалены из полнотекстового индекса.
Таким образом, если данные, переданные FTS5, когда строка удалена,
используя эту команду, отличаются от тех, которые раньше определяли набор
символических случаев, когда это было вставлено, некоторые полнотекстовые
элементы индекса не могут быть правильно удалены,
или FTS5 может попытаться удалить элементы индекса, которые не существуют.
Это может оставить полнотекстовый индекс в непредсказуемом статусе, делая
результаты будущего запроса ненадежными. Эта команда доступна только с таблицами
внешнего содержания и
contentless (включая
contentless-delete).
Это удаляет все записи из полнотекстового индекса. Опция 'deletemerge' используется только таблицами
contentless-delete. Когда строка удалена из таблицы contentless-delete,
записи, связанные с ее символами, немедленно не удалены из индекса FTS.
Вместо этого маркер "tombstone", содержащий rowid удаленной строки,
присоединен к b-дереву, которое содержит элементы индекса строки FTS.
Когда b-дерево запрашивается, любые строки результата запроса, для которых
там существуют маркеры tombstone, опущены от результатов. Когда b-дерево
слито с другими b-деревьями, от удаленных строк и
их маркеров отказываются. Этот выбор определяет минимальный процент строк в b-дереве, у которых
должны быть маркеры tombstone прежде, чем b-дерево будет сделано имеющим
право на слияние автоматически
или явными пользовательскими командами
'merge', даже если это не соответствует обычным критериям, как определено
опциями 'automerge' и
'usermerge'. Например, чтобы определить, что FTS5 должен рассмотреть слияние
составляющего b-дерева после того, как 15% его строк
связали маркеры tombstone: Значение по умолчанию этого выбора равняется 10. Попытка установить его
меньше, чем в ноль восстанавливает значение по умолчанию. Урегулирование
этого выбора к 0 или к большему, чем 100 гарантирует, что b-деревья никогда
не делаются имеющими право на слияние из-за маркеров tombstone. Эта команда используется, чтобы проверить, что полнотекстовый индекс
внутренне последователен и что это согласовывается с любой таблицей
внешнего содержания. Команда integrity-check вызвана, вставив текстовое значение
'integrity-check' в специальную колонку с тем же самым именем,
как таблица FTS5. Если значение поставляется для колонки "rank",
это должно быть 0 или 1. Например: Три формы выше эквивалентны для всех таблиц FTS, которые не являются
внешними таблицыми содержания. Они проверяют, что индексные структуры данных
не повреждены и, если таблица FTS не contentless, что содержание индекса
соответствует содержанию самой таблицы. Для внешней таблицы содержания содержание индекса сравнивается только с
содержанием таблицы внешнего содержания, если значение, определенное для
колонки rank = 1. Во всех случаях, если какие-либо несоответствия найдены, команда терпит
неудачу с ошибкой
SQLITE_CORRUPT_VTAB. Эта команда сливает b-древовидные-структуры
вместе, когда примерно N страниц данных были написаны базе данных, где N это
абсолютное значение параметра, определенного как часть команды 'merge'.
Размер каждой страницы формируется опцией
FTS5 pgsz. Если параметр положительное значение, B-древовидные-структуры имеют право
на слияние только если одно из следующего верно: Возможно сказать, нашла или нет команда 'merge', что какие-либо b-деревья
слились вместе, проверив значение, возвращенное
sqlite3_total_changes() API до и после
того, как команда выполняется. Если различие между двумя значениями равняется
2 или больше, то работа была выполнена. Если различие меньше 2, то команда
'merge' не сработала. В этом случае нет никакой причины выполнить ту же самую
команду 'merge' снова, по крайней мере пока таблица FTS
не будет затем обновлена. Если параметр отрицателен, и есть B-древовидные-структуры больше, чем на
одном уровне в индексе FTS, все B-древовидные-структуры назначены на тот же
самый уровень, прежде чем операция по слиянию будет начата.
Кроме того, если параметр отрицателен, значение параметра конфигурации
usermerge игнорируют, только два b-дерева того же самого уровня могут
быть слиты вместе. Вышеупомянутое значит что, выполняя команду 'merge'
с отрицательным параметром до и после того, как различие в возвращаемом
значении sqlite3_total_changes()
меньше 2, оптимизирует индекс FTS таким же образом, как команда
FTS5 optimize.
Однако, если новое b-дерево будет добавлено к индексу FTS в то время, как
этот процесс продолжается, FTS5 переместит новое b-дерево в тот же самый
уровень, где существующие b-деревья и перезапустит слияние.
Чтобы избежать этого, только первое вызов 'merge'
должен определить отрицательный параметр. Каждый последующий вызов 'merge'
должен определить положительное значение так, чтобы слиянием, начатым первым
вызовом, управляли до завершения, даже если новые b-деревья
добавляются к индексу FTS. Эта команда сливает все отдельные b-деревья, которые в настоящее время
составляют полнотекстовый индекс в единственную большую
b-древовидную-структуру. Это гарантирует, что полнотекстовый индекс занимает
минимальное место в базе данных и находится в самой быстрой форме. См. документацию по опции
FTS5 automerge
для получения дополнительной информации относительно отношений между
полнотекстовым индексом и его составляющими b-деревьями. Поскольку это реорганизовывает весь индекс FTS, команда optimize
может занять много времени. Команда
FTS5 merge может использоваться, чтобы разделить работу оптимизации
индекса FTS на шаги. Для этого: Здесь N это число страниц данных, чтобы слить на каждом вызове merge.
Применение должно прекратить вызывать слияние, когда различие в значении,
возвращенном sqlite3_total_changes() до и после команды станет меньше 2.
Команды слияния могут быть даны как часть тех же самых или отдельных
транзакций, теми же самыми или различными клиентами базы данных.
Обратитесь к документации для
команды merge. Эта команда используется, чтобы установить постоянную опцию "pgsz". Полнотекстовый индекс, сохраняемый FTS5, сохранен как серия blob
фиксированного размера в таблице базы данных. Это не строго необходимо
для всех blob, которые составляют полнотекстовый индекс, быть того же
размера. Опция pgsz определяет размер всех blob, созданных последующими
авторами индекса. Значение по умолчанию 1000. Эта команда используется, чтобы установить постоянное значение "rank". Опция rank используется, чтобы изменить
вспомогательное отображение функции для колонки rank.
Выбор должен быть установлен в текстовое значение в том же самом формате, как
описано для "rank
MATCH ?" ниже. Например: Эта команда сначала удаляет весь полнотекстовый индекс, затем
восстанавливает его на основе содержания таблицы или
таблицы содержания.
Это недоступно с таблицами
contentless. Эта команда используется, чтобы установить опцию boolean
"secure-delete". Например: Обычно, когда вход в fts5 таблице обновлен или удален, вместо того, чтобы
удалить записи из полнотекстового индекса, ключ delete добавляется к
новому b-tree,
созданному транзакцией. Это эффективно, но это означает, что старые
полнотекстовые элементы индекса остаются в файле базы данных, пока они в
конечном счете не удалены операциями по слиянию на полнотекстовом индексе.
Любой с доступом к базе данных может использовать эти записи, чтобы
тривиально восстановить содержание удаленных строк таблицы FTS5. Однако, если
'secure-delete' = 1, полнотекстовые записи на самом деле удалены из базы
данных, когда существующие строки таблицы FTS5 обновлены или удалены.
Это медленнее, но это препятствует тому, чтобы старые полнотекстовые записи
использовались, чтобы восстанавливать удаленные строки таблицы. Этот выбор гарантирует, что старые полнотекстовые записи недоступны
нападавшим с доступом SQL к базе данных. Чтобы также гарантировать, что они
не могут быть восстановлены нападавшими с доступом к самому файлу базы данных
SQLite, применение должно также позволить ядру SQLite безопасное удаление
через
"PRAGMA secure_delete = 1". ПРЕДУПРЕЖДЕНИЕ: Как только одна или более строк таблицы были
обновлены или удалены с этой опцией, таблица FTS5 больше не может читаться
или писаться любой версией FTS5 ранее, чем 3.42.0 (первая версия, в которой
этот выбор был доступен). Иначе будет сообщение об ошибке, подобное
"invalid fts5 file format (found 5, expected 4) - run 'rebuild'".
Формат файла FTS5 может переделан так, чтобы он мог быть прочитан более
ранними версиями FTS5, командой
'rebuild' на таблице, используя
версию 3.42.0 или позже. Значение по умолчанию secure-delete = 0. Эта команда используется, чтобы установить опцию "usermerge". Опция usermerge подобна automerge и crisismerge.
Это минимальное количество сегментов b-дерева, которые будут слиты вместе
командой 'merge' с положительным параметром. Например: Значение по умолчанию usermerge = 4.
Минимальное позволенное значение равняется 2, максимальное 16. FTS5 имеет API, позволяющий его улучшить: Встроенные токенизаторы и вспомогательные функции, описанные в этом
документе, осуществляются, используя общедоступный API, описанный ниже. Прежде чем новая вспомогательная функция или токенизатор
могут быть зарегистрированы в FTS5, применение должно получить указатель на
структуру "fts5_api". Есть одна структура fts5_api для каждого соединения с
базой данных, в котором зарегистрировано расширение FTS5.
Чтобы получить указатель, применение вызывает определенную пользователем
функцию SQL fts5() с отдельным аргументом. Тот аргумент должен быть
установлен в указатель на указатель на объект fts5_api, используя
sqlite3_bind_pointer().
Следующий пример кода демонстрирует технику: Предупреждение обратной совместимости: До SQLite version 3.20.0
(2017-08-01) fts5() работал немного по-другому. Более старые запросы, которые
расширяют FTS5, должны быть пересмотрены, чтобы использовать новую
технику, показанную выше. Структура fts5_api определяется следующим образом. Это выставляет три
метода, по одному для регистрации новых вспомогательных функций и
токенизаторыов и один для восстановления существующего токенизатора.
Последний предназначается, чтобы облегчить внедрение токенизаторов,
подобных встроенному токенизатору porter. Чтобы вызвать метод объекта fts5_api, сам указатель fts5_api должен быть
передан как первый аргумент метода, сопровождаемый другими, определенными
методом, аргументами. Например: Методы структуры fts5_api описаны индивидуально в следующих разделах. Чтобы создать токенизатор, применение должно осуществить три функции:
конструктор токенизатора (xCreate), деструктор (xDelete) и функцию, чтобы
сделать фактический анализ данных (xTokenize). Тип каждой функции задан в
структуре fts5_tokenizer: Внедрение зарегистрировано в модуле FTS5, вызвав метод xCreateTokenizer()
объекта fts5_api. Если уже есть токенизатор с тем же самым именем, он заменяется.
Если параметр не-NULL xDestroy передается xCreateTokenizer(),
это вызвано с копией указателя pUserData, переданного как единственный
аргумент, когда дескриптор базы данных закрывается или
когда токенизатор заменяется. При успехе xCreateTokenizer() вернет SQLITE_OK.
Иначе это возвращает код ошибки SQLite. В этом случае функция xDestroy
не вызвана. Когда таблица FTS5 использует обычай токенизатор, ядро FTS5 вызывает
xCreate() однажды, чтобы создать токенизатор, затем xTokenize()
ноль или больше раз, чтобы разметить последовательности, потом xDelete(),
чтобы освободить любые ресурсы, ассигнованные xCreate():
Эта функция используется, чтобы ассигновать и инициализировать токенизатор.
Он требуется, чтобы на самом деле размечать текст. Первым аргументом, переданным к этой функции, является копия (void*),
обеспеченная применением, когда объект fts5_tokenizer был зарегистрирован в
FTS5 (третий аргумент xCreateTokenizer()). Вторые и третьи аргументы это
множество nul-законченных последовательностей, содержащих аргументы
токенизатора, если таковые имеются, определенные после имени токенизатора
как часть CREATE VIRTUAL TABLE, которым создали таблицу FTS5. Заключительный аргумент выходная переменная. Если успешно, (*ppOut)
должна указать на новый дескриптор токенизатора и вернуть SQLITE_OK.
Если ошибка происходит, некоторое значение кроме SQLITE_OK должно быть
возвращено. В этом случае fts5 предполагает, что окончательное значение
*ppOut не определено.
Эта функция вызвана, чтобы удалить дескриптор токенизатора ранее
ассигнованный с использованием xCreate(). Fts5 гарантирует, что эта функция
будет вызвана точно однажды для каждого успешного вызова xCreate().
Эта функция, как ожидают, разметит строку байтов nText, обозначенную
аргументом pText. pText может быть или не быть nul-закончен.
Первым аргументом, переданным к этой функции, является указатель на объект
Fts5Tokenizer, возвращенный более ранним вызовом xCreate(). Второй аргумент указывает на причину, по которой FTS5 просит
токенизацию поставляемого текста. Это всегда одно из
следующих четырех значений: Для каждого символа во входной строке должен быть вызван поставляемый
отзыв xToken(). Первый аргумент ему должен быть копией указателя, переданного
как второй аргумент xTokenize(). Третий и четвертый аргументы это
указатель на буфер, содержащий символический текст и размер символа в байтах.
4 и 5 аргументы это байтовые смещения первого байта и первого байта
немедленно после текста, из которого символ получен во входе. Второй аргумент, переданный xToken() ("tflags")
должен обычно устанавливаться в 0. Исключение, если токенизатор поддерживает
синонимы. В этом случае посмотрите обсуждение ниже для деталей. FTS5 считает, что xToken() вызван для каждого символа в порядке, в котором
они происходят в рамках входного текста. Если xToken() возвращает какое-либо значение кроме SQLITE_OK, то
xTokenize() должен немедленно возвратить копию значения, возвращенного
xToken(). Или, если входной буфер исчерпан, xTokenize() должен вернуть
SQLITE_OK. Наконец, если ошибка происходит с xTokenize(),
это может оставить токенизацию и возвратить любой код ошибки кроме SQLITE_OK
или SQLITE_DONE. Свой токенизатор может также поддержать синонимы.
Рассмотрите случай, в котором пользователь хочет запросить
такие фразы, как "first place". Используя встроенные токенизаторы, запрос
FTS5 'first + place' будет соответствовать случаям "first place"
в наборе документов, но не альтернативным формам, таким как "1st place".
В некоторых запросах было бы лучше соответствовать всем случаям "first place"
или "1st place", независимо от формы, которую пользователь определил в
тексте запроса MATCH. Есть несколько способов приблизиться к этому в FTS5: токенизатор предлагает "1st" и "first" как синонимы для первого символа в
запросе MATCH, и FTS5 эффективно управляет запросом, подобным: за исключением того, что в целях вспомогательных функций запрос все еще,
кажется, содержит всего две фразы "(first OR 1st)", рассматриваемые
как единственная фраза. Этот путь, даже если токенизатор не обеспечивает синонимы, размечая текст
запроса (не должен: это было бы неэффективен), не имеет значения, если
пользовательские запросы для 'first + place' или '1st + place',
есть как записи в индексе FTS, соответствующем обеим формам первого символа.
Разбирает ли это текст документа или текст запроса, какой-либо вызов
xToken, который определяет аргумент tflags с битом
FTS5_TOKEN_COLOCATED, как полагают, поставляет синоним для предыдущего
символа. Например, разбирая документ "I won first place",
токенизатор, который поддерживает синонимы, вызвал бы xToken() 5 раз: Ошибка определить флаг FTS5_TOKEN_COLOCATED, с которым вызывают в первый
раз xToken(). Многократные синонимы могут быть определены для единственного
символа, сделав множественные вызовы xToken(FTS5_TOKEN_COLOCATED) в
последовательности. Нет никакого предела количеству синонимов, которые могут
быть обеспечены для единственного символа. Во многих случаях метод (1) выше является лучшим подходом.
Это не добавляет дополнительные данные к индексу FTS или требует, чтобы FTS5
запросил многочисленные термины, таким образом, это эффективно с точки зрения
скорости запроса и дискового пространства.
Однако, это не поддерживает запросы префикса очень хорошо.
Если, как предложено выше, символ "first" подставлен вместо "1st"
токенизатором, то запрос: не будет соответствовать документам, которые содержат символ "1st"
(поскольку токенизатор, вероятно, не отобразил "1s" ни к
какому префиксу "first"). Для полной поддержки префикса может быть предпочтен метод (3).
В этом случае, потому что индекс содержит записи для "first" и "1st", такие
запросы префикса, как 'fi*' или '1s*' будут соответствовать правильно.
Однако, потому что дополнительные записи добавляются к индексу FTS, этот
метод использует больше пространства в базе данных. Метод (2) это середина между (1) и (3).
Используя этот метод, такой запрос, как '1s*',
будет соответствовать документам, которые содержат буквальный
"1st", но не "first" (предполагая, что токенизатор не в состоянии обеспечить
синонимы для префиксов). Однако, такой запрос непрефикса, как '1st'
будет соответствовать "1st" и "first". Этот метод не требует дополнительного
дискового пространства, поскольку никакие дополнительные записи не
добавляются к индексу FTS. С другой стороны, это может потребовать, чтобы
больше циклов CPU управляло запросами MATCH, поскольку отдельные запросы
индекса FTS требуются для каждого синонима. Используя методы (2) или (3), важно, чтобы токенизатор только обеспечил
синонимы, размечая текст документа (метод (3)) или текст запроса (метод (2)),
но не то и другое сразу. Выполнение этого не вызовет
ошибок, но неэффективно. Осуществление своей вспомогательной функции подобно осуществлению
скалярной функции SQL. Внедрение должно быть
функцией C типа fts5_extension_function, определенной так: Внедрение зарегистрировано в модуле FTS5, вызвав метод
xCreateFunction() объекта fts5_api. Если уже есть вспомогательная функция с
тем же самым именем, она заменяется новой функцией. Если параметр не-NULL
xDestroy передается xCreateFunction(), это вызвано с копией указателя
pUserData, переданного как единственный аргумент, когда дескриптор
базы данных закрывается или когда зарегистрированная
вспомогательная функция заменяется. Если успешно, xCreateFunction() вернет SQLITE_OK.
Иначе это возвращает код ошибки SQLite. В этом случае функция
xDestroy НЕ вызвана. Заключительные три аргумента, переданные к вспомогательному отзыву
функции, подобны этим трем аргументам, переданным к внедрению скалярной
функции SQL. Все аргументы кроме первого, переданного к вспомогательной
функции, доступны внедрению в массиве apVal[]. Внедрение должно
возвратить результат или ошибку через обработчик pCtx. Первым аргументом, переданным к вспомогательному отзыву функции, является
указатель на структуру, содержащую методы, которые могут быть вызваны, чтобы
получить информацию относительно текущего запроса или строки. Второй аргумент
это дескриптор, который должен быть передан как первый аргумент любому такому
вызову метода. Например, следующее определение вспомогательной функции
возвращает общее количество символов во всех колонках текущей строки: Следующий раздел описывает API, предлагаемый реализациям вспомогательных
функций подробно. Дальнейшие примеры могут быть найдены в файле
исходного кода "fts5_aux.c" Возвратит копию указателя контекста, в
котором была зарегистрирована дополнительная функция. Если iCol меньше 0, выходная переменная *pnToken
установлена к общему количеству символов в таблице FTS5. Или, если iCol
неотрицательный, но меньше, чем количество колонок в таблице, возвратит
общее количество символов в колонке iCol, рассмотрев все
строки в таблице FTS5. Если iCol больше или равен количеству колонок в таблице, SQLITE_RANGE
возвращен. Или, если ошибка происходит (например, условие OOM или ошибка IO),
соответствующий код ошибки SQLite возвращен. Возвратит количество колонок в таблице. Если параметр iCol меньше 0, выходная переменная
*pnToken установлена к общему количеству символов в текущей строке.
Или, если iCol неотрицательный, но меньше, чем количество колонок в таблице,
*pnToken установлена к количеству символов в колонке iCol текущей строки. Если параметр iCol больше или равен количеству колонок в таблице,
SQLITE_RANGE возвращен. Или, если ошибка происходит (например, условие OOM
или ошибка IO), соответствующий код ошибки SQLite возвращен. Эта функция может быть довольно неэффективной, если используется с
таблицей FTS5, составленной с "columnsize=0". Эта функция пытается восстановить текст колонки iCol
текущего документа. Если успешно, (*pz) установлен в
указатель на буфер, содержащий текст в кодировании utf-8, (*pn)
установлен в размер в байтах (не знаках) буфера, и возвращается SQLITE_OK.
Иначе, если ошибка происходит, код ошибки SQLite возвращен, и окончательные
значения (*pz) и (*pn) не определены. Возвращает количество фраз в
текущем выражении запроса. Возвращает количество символов во фразе iPhrase
запроса. Фразы пронумерованы с 0. Установит *pnInst к общему количеству случаев
всех фраз в запросе в текущей строке.
Возвратит SQLITE_OK в случае успеха или код ошибки (SQLITE_NOMEM),
если ошибка происходит. Этот API может быть довольно медленным, если используется с таблицей
FTS5, составленной с "detail=none" или "detail=column".
Если таблица FTS5 составлена с "detail=none" или "detail=column" и опцией
"content=" (то есть, это таблица contentless), этот
API всегда вернет 0. Запрос для деталей фразы, соответствующей iIdx
в текущей строке. Соответствия фразы пронумерованы с 0, таким образом,
аргумент iIdx должен быть больше или равным нолю и меньшим, чем значение,
произведенное xInstCount(). Обычно параметр вывода *piPhrase устанавливается в число фраз, *piCol
к колонке, в которой это происходит и *piOff в смещение первого токена
фразы. SQLITE_OK вернется в случае успеха или код ошибки (SQLITE_NOMEM),
если ошибка происходит. Этот API может быть довольно медленным, если используется с таблицей
FTS5, составленной с "detail=none" или "detail=column". Возвращает rowid текущей строки. Разметьте текст, используя токенизатор,
принадлежащий таблице FTS5. Эта API-функция используется, чтобы запросить
таблицу FTS для фразы iPhrase текущего запроса.
Определенно, запрос, эквивалентный: $p установлен к фразе, эквивалентной фразе iPhrase текущего запроса.
Любой вертикальный фильтр, который относится к фразе iPhrase текущего
запроса, включен в $p. Для каждой строки, которую посещают, вызвана функция
обратного вызова, переданная как четвертый аргумент.
Контекст и объекты API, переданные к функции обратного вызова, могут
использоваться, чтобы получить доступ к свойствам каждой подобранной строки.
Api.xUserData() возвращает копию указателя, переданного как
третий аргумент pUserData. Если функция обратного вызова возвращает какое-либо значение кроме
SQLITE_OK, запрос оставлен, и функция xQueryPhrase немедленно возвращается.
Если возвращенное значение SQLITE_DONE, xQueryPhrase вернет SQLITE_OK.
Иначе код ошибки размножен вверх. Если запрос отработал нормально, возвращается SQLITE_OK.
Если некоторая ошибка происходит, прежде чем запрос заканчивает или
прерывается отзывом, код ошибки SQLite возвращен. Сохраните указатель, переданный как
второй аргумент вспомогательной дополнительной функции.
Указатель может тогда быть восстановлен текущим или любым будущим вызовом
той же самой дополнительной функции fts5, сделанным как часть того же самого
запроса MATCH, используя xGetAuxdata() API. Каждая дополнительная функция ассигнует единственное вспомогательное место
данных для каждого запроса FTS (выражение MATCH). Если дополнительная функция
вызвана несколько раз для единственного запроса FTS, то все вызовы
разделяют единственный вспомогательный контекст данных. Если уже есть вспомогательный указатель данных, когда эта функция вызвана,
то это заменяется новым указателем. Если отзыв xDelete был определен наряду с
оригинальным указателем, он вызван в этом пункте. Отзыв xDelete, если он есть,
также вызван на вспомогательный указатель данных после того, как
запрос FTS5 закончился. Если ошибка (например, условие OOM) происходит в этой функции,
вспомогательные данные установлены в NULL и возвращен код ошибки.
Если параметр xDelete не был NULL,
он вызван на вспомогательный указатель данных перед возвращением. Возвращает текущий вспомогательный указатель
данных для дополнительной функции fts5. Посмотрите метод xSetAuxdata(). Если bClear не 0, то вспомогательные данные очищены (установлены в NULL)
перед завершением этой функции. В этом случае xDelete, если
есть, не вызван.
Эта функция используется, чтобы восстановить общее количество строк
в таблице. Другими словами, то же самое значение, которое
было бы возвращено: Эта функция используется, наряду с типом
Fts5PhraseIter и методом xPhraseNext, чтобы повторить для всех случаев фразы
единого запроса в текущей строке.
Это та же самая информация, как доступна через xInstCount/xInst API.
В то время как xInstCount/xInst APIs более удобен для использования, этот API
может быть быстрее. Чтобы повторить для всех случаев
фразы iPhrase, используйте следующий код: Структура Fts5PhraseIter определяется выше. Запросы не должны изменять эту
структуру непосредственно, она должна использоваться только как показано выше
с помощью методов xPhraseFirst() и xPhraseNext() API (а также
xPhraseFirstColumn() и xPhraseNextColumn(), как иллюстрировано ниже). Этот API может быть довольно медленным, если используется с таблицей FTS5,
составленной с "detail=none" или "detail=column".
Если таблица FTS5 составлена с "detail=none" или "detail=column" и опцией
"content=" (то есть, если это contentless-таблица), то этот API всегда
проходит через пустое множество (все вызовы xPhraseFirst() устанавливают
iCol = -1). См. выше xPhraseFirst. Эта функция и xPhraseNextColumn() подобны
xPhraseFirst() и xPhraseNext() API (см. выше).
Различие в том, что вместо того, чтобы повторить для всех случаев фразы в
текущей строке эти API используются, чтобы пройти через набор колонок в
текущей строке, которые содержат один или несколько случаев
указанной фразы. Например: Этот API может быть довольно медленным, если используется с таблицей FTS5,
составленной с "detail=none". Если таблица FTS5 составлена с опциями
"detail=none" и "content=" (то есть, это contentless-таблица),
этот API всегда проходит через пустое множество (все вызовы
xPhraseFirstColumn() установят iCol = -1). Информация от доступа к использованию этого API, и его компаньона
xPhraseFirstColumn() может также быть получена, используя
xPhraseFirst/xPhraseNext (или xInst/xInstCount).
Главное преимущество этого API состоит в том, что это значительно более
эффективно, чем альтернативы, когда используется с таблицами
"detail=column". См. выше xPhraseFirstColumn. Виртуальный модуль таблицы fts5vocab позволяет пользователям извлекать
информацию из полнотекстового индекса FTS5 непосредственно.
Модуль fts5vocab это часть FTS5. Каждая таблица fts5vocab связана с единственной таблицей FTS5.
Таблица fts5vocab обычно составляется, определяя два аргумента вместо имен
столбцов в CREATE VIRTUAL TABLE: название связанной таблицы FTS5 и тип
таблицы fts5vocab. В настоящее время есть три типа таблицы fts5vocab:
"row", "col" и "instance".
Если таблица fts5vocab не составлена в базе данных "temp", это должна быть
часть той же самой базы данных, как связанная таблица FTS5. Если таблица fts5vocab составлена в базе данных temp,
она может быть связана с таблицей FTS5 в любой приложенной базе данных.
Чтобы приложить таблица fts5vocab к таблице FTS5, расположенной в базе данных
кроме "temp", имя базы данных вставляется перед именем таблицы FTS5 в
CREATE VIRTUAL TABLE: Определение трех аргументов, составляя таблицу fts5vocab в любой базе
данных кроме "temp" приводит к ошибке. Таблица fts5vocab типа "row" содержит одну строку для каждого отличного
термина в связанной таблице FTS5. Столбцы таблицы следующие: Таблица fts5vocab типа "col" содержит одну строку для каждой отличной
комбинации термина/колонки в связанной таблице FTS5.
Столбцы таблицы следующие: Таблица fts5vocab типа "instance" содержит одну строку для каждого случая
термина, сохраненного в связанном индексе FTS. Если таблицы FTS5 создается с
'detail' = 'full', столбцы таблицы следующие: Если таблица FTS5 составлена с 'detail' = 'col', то колонка
offset случая виртуальной таблицы всегда содержит NULL.
В этом случае есть один строка в таблице для каждой уникальной комбинации
термина//doc/col. Или, если таблица FTS5 составлена с 'detail' = 'none',
offset и col всегда NULL. Для таблиц FTS5 с
detail=none, есть одна строка в таблице fts5vocab для каждой уникальной
комбинации term/doc. Например: Эта секция описывает на высоком уровне как модуль FTS хранит свой индекс и
содержание в базе данных. Необязательно прочитать или понять материал в этой
секции, чтобы использовать FTS в применении. Однако, это может быть полезно
для разработчиков приложений, пытающихся проанализировать и понять показатели
производительности FTS, или разработчикам, рассматривающим улучшения к
существующему набору функций FTS. Когда виртуальная таблица FTS5 составлена в базе данных, от 3 до 5
реальных таблиц создается в базе данных. Они известны как
"теневые таблицы" и используются
виртуальным модулем таблицы, чтобы хранить постоянные данные. К ним не должен
получать доступ непосредственно пользователь. Много других виртуальных
модулей таблицы, включая FTS3 и
rtree, также создают и
используют теневые таблицы. FTS5 составляет следующие теневые таблицы. В каждом случае фактическое имя
таблицы основано на названии виртуальной таблицы FTS5 (в следующем
замените % на имя виртуальной таблицы, чтобы найти фактическое
теневое имя таблицы). Следующие разделы описывают более подробно, как эти пять таблиц
используются, чтобы хранить данные FTS5. Секции ниже относятся к 64-битным целым числам со знаком, сохраненным в
форме "varint". FTS5 использует тот же самый формат varint, как
используется в различных местах ядром SQLite. varint между 1 и 9 байтами в длину. varint состоит из ноля или из большего
количества байтов, которые следуют за старшим установленным битом,
сопровождаемые единственным байтом, у которого старший бит очищен,
или из девяти байтов, смотря что короче.
Младшие семь битов каждого из первых восьми байтов и все 8 битов девятого
байта используются, чтобы сохранить 64-битное целое число.
Varint имеет обратный порядок байтов: биты, взятые от более раннего байта
varint, более значительные, чем биты, взятые от более поздних байтов. Индекс FTS это упорядоченное хранилище ключей, где ключи это термины
документа или префиксы терминов и присваиваемые значения "doclists".
Этот doclist это упакованный массив varint, который кодирует положение
каждого случая термина в таблице FTS5. Положение единственного случая термина
определяется как комбинация: Индекс FTS содержит до (nPrefix+1) записей для каждого символа в наборе
данных, где nPrefix это количество определенных
индексов префикса. Ключи, связанные с главным индексом FTS (который не является индексом
префикса), имеют префиксом символ "0". Ключи для первого индекса префикса
имеют префиксом символ "1". Ключи для второго индекса префикса
имеют префиксом символ "2" и т.д. Например, если токен "document"
вставляется в таблицу FTS5 с индексами префикса
, определенными prefix="2 4", то ключи, добавленные к индексу FTS,
были бы "0document", "1do" и "2docu". Элементы индекса FTS не сохранены в единственном дереве или структуре
хэш-таблицы. Вместо этого они сохранены в серии неизменного b-дерева как
структуры, называемые "b-деревьями сегмента". Каждый раз при
записи таблице FTS5 передается один или несколько (но обычно всего один)
новые b-деревья сегмента, содержащие новые записи и tombstones-маркеры
для любых удаленных записей. Когда индекс FTS запрашивается, читатель
запрашивает каждое b-дерево сегмента в свою очередь и сливает результаты,
уделяя первостепенное значение более новым данным. Каждому b-дереву сегмента назначают числовой уровень. Когда новое b-дерево
сегмента написано базе данных как часть совершения транзакции, это назначено
на уровень 0. B-деревья сегмента, принадлежащие единственному уровню,
периодически сливаются вместе, чтобы создать единственное большее b-дерево
сегмента, которое назначено на следующий уровень (то есть, b-деревья сегмента
уровня 0 слиты, чтобы стать единственным b-деревом сегмента уровня 1).
Таким образом численно большие уровни содержат более старые данные в обычно
больших b-деревьях сегмента. Обратитесь к опциям
'automerge',
'crisismerge' и
'usermerge', наряду с
командами 'merge' и
'optimize'
для получения дополнительной информации о том, как управлять слиянием. В случаях, где doclist, связанный с термином или префиксом термина, очень
большой, может быть связанный индекс doclist
. Индекс doclist подобен набору внутренних узлов b-дерева. Это позволяет
большому doclist быть эффективно запрошенным для rowid или диапазонов rowid.
Например, обрабатывая запрос: FTS5 использует b-древовидный-индекс сегмента, чтобы определить
местонахождение doclist для термина "term",
затем использует его индекс doclist (предполагая, что это присутствует),
чтобы эффективно определить подмножество соответствий
с rowid в необходимом диапазоне. Таблица %_data используется, чтобы сохранить три типа записей: Каждому b-дереву сегмента в системе назначают уникальный 16-битный
id сегмента. id сегмента могут быть снова использованы только после того, как
b-дерево сегмента первоначального владельца полностью слито в высокоуровневое
b-дерево сегмента. В b-дереве сегмента каждой странице листа назначают
уникальный номер страницы: 1 для первой страницы листа, 2 для
второй и так далее. Каждой странице листа индекса doclist также назначают номер страницы.
Первой (крайней левой) странице листа в индексе doclist назначают тот же
самый номер страницы в качестве страницы листа b-дерева сегмента, на которой
ее термин появляется (потому что индексы doclist создаются только для
терминов с очень длинным doclist, самое большее у одного термина на лист
b-дерева сегмента есть связанный индекс doclist).
Назовите этот номер страницы P. Если doclist столь большой, что он требует
второго листа, второй лист имеет номер страницы P+1. Третий лист P+2.
Каждая строка индекса doclist b-дерева (листья, родители листьев, их предки)
получают номера страниц этим способом, начиная с номера страницы P. Значение "id", используемое в таблице %_data, чтобы сохранить любой
данный лист b-дерева сегмента, лист индекса doclist или узел,
составлено следующим образом: Запись структуры определяет набор b-деревьев сегмента, которые составляют
текущий индекс FTS, наряду с деталями любых продолжающихся возрастающих
операций по слиянию. Это сохранено в таблице %_data с id=10.
Запись структуры начинается с единственного значения 32-bit unsigned cookie.
Это значение увеличено каждый раз, когда структура изменяется. Далее идут три
значения varint: Затем для каждого уровня от 0 до nLevel: Средняя запись, которая всегда снабжается id=1 в таблице %_data,
не хранит среднее число. Вместо этого это содержит вектор (nCol+1)
упакованных значений varint, где nCol это количество колонок в таблице FTS5,
включая неиндексируемые колонки. Первый varint содержит общее количество
строк в таблице FTS5. Второй содержит общее количество символов во всех
значениях, сохраненных в крайнем левом столбце таблицы FTS5.
Третий хранит количество символов во всех значениях
для следующего крайнего левого и так далее. Значение для неиндексируемых
колонок всегда 0. Формат key/doclist это формат, используемый, чтобы сохранить серию ключей
(термины документа или префиксы термина, предварительно прикрепленные
отдельным символом к определенному индексу, которому они принадлежат)
в сортированном порядке, каждый с их связанным doclist. Формат состоит из
переменных ключей и doclist, упакованных вместе. Первый ключ сохранен как: Каждый последующий ключ сохранен как: Например, если первые два ключа в записи FTS5 key/doclist являются
"0challenger" и "0chandelier", то первый ключ сохранен как varint 11,
сопровождаемый 11 байтами "0challenger", второй ключ хранится как varints 4
и 7, сопровождается 7 байтами "ndelier". Рис. 1. Формат Term/Doclist. Каждый doclist определяет строки (их значениями rowid), которые содержат
по крайней мере один случай термина или называют префикс и связанный список
положения (он же "poslist"), перечисляющий положения каждого случая термина в
строке. В этом смысле "position" определяется как номер столбца и смещение
термина в значении столбца. В doclist документы всегда хранятся в порядке,
отсортированном по rowid. Первый rowid в doclist сохранен
как varint. Это немедленно сопровождается его связанным списком положений.
После этого хранятся различия между первым rowid и вторым, как varint,
сопровождаемый doclist, связанным со вторым rowid в doclist. И так далее. Нет никакого способа определить размер doclist, разбирая его.
Это должно быть сохранено внешне. Посмотрите
ниже для деталей того, как это достигается в FTS5. Рис. 2. Формат Doclist Список положений, часто сокращаемый до "poslist",
определяет колонку и смещение термина в строке
каждого случая рассматриваемого символа. Формат poslist: Рис. 3. Список положений (poslist) со смещениями в колонках 0 и i
Если это достаточно маленькое (по умолчанию, это означает меньше 4000
байт), все содержание b-дерева сегмента может быть сохранено в формате
key/doclist, описанном в предыдущей секции как единственный blob
в таблице %_data. Иначе key/doclist разделен на страницы (по умолчанию,
приблизительно по 4000 байтов каждая) и сохранен в смежном наборе записей в
таблице %_data (см. ниже). Когда key/doclist разделен на страницы, следующие
модификации сделаны к формату: У каждой страницы также есть заголовок 4 байта
фиксированного размера и непостоянного размера хвост.
Заголовок разделен на 2 16-битных области целого числа с обратным
порядком байтов. Они содержат: Нижний колонтитул состоит из серии varints, содержащих
байтовое смещение каждого ключа, который появляется на странице.
Нижний колонтитул 0 байт в размере при отсутствии ключей на странице. Рис. 4. Формат страницы Результатом форматирования содержания b-дерева сегмента в формате
key/doclist и затем разделения его на страницы является что-то очень похожее
на листья b+tree. Вместо того, чтобы создать формат для внутренних узлов
этого b+tree и сохранить их в таблице %_data
вместе с листьями, ключи, которые были бы сохранены в таких узлах,
добавляются к таблице %_idx, определенной как: Для каждой страницы "leaf", которая содержит по крайней мере один ключ,
вход добавляется к таблице %_idx. Области установлены следующим образом: Затем чтобы найти лист для сегмента i, который может содержать термин t,
вместо того, чтобы перерыть внутренние узлы, FTS5 управляет запросом: Индекс сегмента, описанный в предыдущей секции
, позволяет b-дереву сегмента быть эффективно запрошенным
термином или, предполагая, что есть индекс префикса необходимого размера,
префиксом термина. Структура данных, описанная в этой секции, индексы
doclist, позволяет FTS5 эффективно искать rowid или диапазон rowid
в doclist, связанном с единственным термином или префиксом термина. Не все ключи связаны с индексами doclist.
По умолчанию индекс doclist добавляется только для ключа, если его doclist
охватывает больше, чем 4 страницы листа b-дерева сегмента.
Индексы Doclist это самостоятельные b-деревья с обоими листьями и внутренними
узлами, сохраненными как записи в таблице %_data,
но на практике большинство doclist достаточно маленькое, чтобы
поместиться на единственном листе. FTS5 использует тот же самый грубый
размер для узла индекса doclist, как это делается для листьев b-дерева
сегмента (по умолчанию 4000 байт). Листья индекса Doclist и внутренние узлы используют тот же самый
формат страниц. Первый байт это байт "flags".
Это установлено в 0x00 для страницы корня doclist b-дерева индекса и 0x01
для всех других страниц. Остаток страницы это
серия плотно упакованных varint, следующим образом: Для крайнего левого листа индекса doclist в индексе doclist
крайняя левая дочерняя страница это первый лист b-дерева сегмента после того,
который содержит сам ключ. Много общих функций рейтинга результата поиска требуют как вход размер в
символах документа результата (поскольку критерий поиска
в коротком документе, считают более значительным, чем
в длинном документе). Чтобы обеспечить быстрый доступ к этой информации, для
каждой строки в таблице FTS5 существует соответствующая запись
(с тем же самым rowid) в теневой таблице %_docsize, которая содержит размер
каждого значения столбца в строке в символах. Размеры значения столбца сохранены в blob, содержащем один упакованный
varint для каждой колонки таблицы FTS5, слева направо.
varint содержит, конечно, общее количество символов в соответствующем
значении столбца. Неиндексируемые колонки включены в этот вектор varint,
для них значение всегда устанавливается к нолю. Эта таблица используется xColumnSize API.
Это может быть опущено в целом, определив опцию
columnsize=0.
В этом случае xColumnSize API все еще доступен вспомогательным функциям, но
работает намного более медленно. Фактическое содержание таблицы это значения, вставленные в таблице FTS5,
сохранены в таблице %_content.
Эта таблица составлена с один столбцом "c*" для каждой колонки таблицы FTS5,
включая любые неиндексируемые колонки. Значения для крайнего левого столбца
таблицы FTS5 сохранены в колонке "c0" таблицы %_content, значения из
следующего столбца таблицы FTS5 сохранены в колонке "c1" и т.д. Эта таблица опущена полностью для таблиц
внешнего содержания или contentless FTS5. Эта таблица хранит значения любых постоянных параметров конфигурации.
Колонка "k" хранит название выбора (текст), колонка "v" хранит
значение. Содержание в качестве примера: Также доступен подобный, но более зрелый модуль
FTS3/4. FTS5 это новая версия FTS4, которая включает
различные меры и решения для проблем, которые не могли быть решены в FTS4,
не жертвуя совместимостью. Некоторые из этих проблем
описаны ниже. Чтобы использовать FTS5 вместо FTS3 или FTS4, запросы обычно требуют
минимальных модификаций. Большую часть проблем можно поделить на три
категории: изменения, требуемые CREATE VIRTUAL TABLE для создания таблиц FTS,
изменения в SELECT, которые раньше выполняли запросы этих таблиц,
и изменения запросов, которые используют
вспомогательные функции FTS. Имя модуля должно быть изменено с "fts3" или "
fts4" на "fts5". Вся информация о типе или ограничительные технические требования
должны быть удалены из определений столбца. FTS3/4 игнорирует все после имени
столбца в определении столбца, FTS5 пытается разобрать его (и сообщит об
ошибке, если это потерпит неудачу. Опция "matchinfo=fts3" недоступна. Замена
"columnsize=0". Опция notindexed= недоступна. Замена
UNINDEXED
в определении столбца. Токенизатор ICU недоступен. Недоступны опции compress=, uncompress= и languageid=.
Нет на данный момент никакого эквивалента для их функциональности.
Псевдоним "docid" не существует. Запросы должны использовать
"rowid" вместо этого. Поведение запросов, когда вертикальный фильтр определяется как часть
запроса FTS или при помощи колонки как LHS оператора MATCH, немного
отличается. Для таблицы с колонками "a" и
"b" и запросом, подобным: FTS3/4 ищет соответствия в колонке "b". Однако, FTS5 всегда
возвращает нулевые строки, поскольку результаты сначала фильтрованы для
колонки "b", затем для колонки "a", не оставив
результатов. Другими словами, в FTS3/4 внутренний фильтр отвергает
внешнее, в FTS5 применяются оба фильтра. Синтаксис запроса FTS (правая сторона оператора MATCH) изменился до
некоторой степени. Синтаксис FTS5 близок к расширенному синтаксису FTS4.
Основное различие в том, что FTS5 более тщательный в
непризнанных символах пунктуации и подобный в строках запроса.
Большинство запросов, которые работают с FTS3/4, должны также работать с
FTS5, а те, которые этого не делают, должны возвратить ошибки анализа.
FTS5 не имеет функций matchinfo() или offsets(), функция snippet()
не так полнофункциональна как в FTS3/4. Однако, так как FTS5
действительно обеспечивает API, позволяющий запросам создать
свои вспомогательные функции, любая необходимая функциональность
может быть осуществлена в коде приложения. Набор встроенных вспомогательных функций, обеспеченных FTS5, может
быть улучшен в будущем. Функциональность, обеспеченная модулем fts4aux,
теперь обеспечивается
fts5vocab. Схема этих двух таблиц немного отличается. FTS3/4 команда "merge=X,Y" была заменена
командой FTS5 merge. Команда FTS3/4 "automerge=X" была заменена опцией
FTS5 automerge.
FTS5 похож на FTS3/4, основная задача каждого состоит в том, чтобы
поддержать отображение индекса от каждого уникального символа до списка
случаев того символа в ряде документов, где каждый случай определяется
документом, в котором это появляется, и его положением в рамках
того документа. Например: В примере выше, каждый трижды определяет местоположение символического
случая rowid, номер столбца (колонки пронумерованы, последовательно с
0 и идут слева направо) и положение в значении столбца (первый символ в
значении столбца 0, второй равняется 1 и так далее).
Используя этот индекс, FTS5 в состоянии предоставить своевременные
ответы на такие запросы, как
"набор всех документов, которые содержат символ 'A'",
или "набор всех документов, которые содержат последовательность 'Y Z'".
Список случаев, связанных с единственным символом, называют
"списком случаев". Принципиальное различие между FTS3/4 и FTS5 в том, что в FTS3/4 каждый
список случая сохранен как единственная большая запись базы данных, тогда как
в больших списках случаи FTS5 разделены между многочисленными записями базы
данных. Это имеет следующие последствия для контакта с большими базами
данных, которые содержат большие списки: FTS5 в состоянии загрузить списки случая в память с приращением,
чтобы уменьшить использование памяти и пиковый размер распределения.
FTS3/4 очень часто загружает все списки случая в память. Обрабатывая запросы, которые показывают больше, чем один символ, FTS5
иногда в состоянии решить, что запросу можно ответить, осмотрев подмножество
большого списка случаев. FTS3/4 почти всегда должен смотреть
все списки случаев. По этим причинам много сложных запросов могут использовать меньше памяти и
работать быстрее с FTS5. Некоторые другие моменты, которыми FTS5 отличается от FTS3/4: FTS5 поддержвает "ORDER BY rank"
для возвращения результатов в порядке уменьшающейся уместности. FTS5 показывает API, разрешающий пользователям создать свои
вспомогательные функции для продвинутых приложений рейтинга и обработки
текста. Специальная колонка "rank" может быть отображена
к своей вспомогательной функции так, чтобы добавление "ORDER BY rank"
к запросу работало как ожидалось. FTS5 признает unicode-символы разделителя и эквивалентность регистра
по умолчанию. Это также возможно при использовании FTS3/4, но должно
быть явно позволено. Синтаксис запроса был пересмотрен в случае необходимости, чтобы
удалить двусмысленности и позволить избежать специальных
символов в терминах запроса. По умолчанию FTS3/4 иногда сливает вместе два или больше из
b-деревьев, которые составляют его полнотекстовый индекс в INSERT, UPDATE или
DELETE, выполненном пользователем. Это означает, что любая операция на
таблице FTS3/4 может оказаться удивительно медленной, поскольку FTS3/4
непредсказуемо может слить вместе два или больше больших b-дерева в ней.
FTS5 использует возрастающее слияние по умолчанию, которое ограничивает объем
обработки, которая может произойти в любом данном INSERT, UPDATE или DELETE.
 Small. Fast. Reliable.
Small. Fast. Reliable.
Choose any three.
Расширение SQLite FTS5
1. Обзор FTS5
CREATE VIRTUAL TABLE email USING fts5(sender, title, body);
-- Query for all rows that contain at least once instance of the term
-- "fts5" (in any column). The following three queries are equivalent.
SELECT * FROM email WHERE email MATCH 'fts5';
SELECT * FROM email WHERE email = 'fts5';
SELECT * FROM email('fts5');
-- Query for all rows that contain at least once instance of the term
-- "fts5" (in any column). Return results in order from best to worst
-- match.
SELECT * FROM email WHERE email MATCH 'fts5' ORDER BY rank;
-- Query for rows that match "fts5". Return a copy of the "body" column
-- of each row with the matches surrounded by <b></b> tags.
SELECT highlight(email, 2, '<b>', '</b>') FROM email('fts5');
2. Компиляция и использование FTS5
2.1. Сборка FTS5 как часть SQLite
2.2.
Сборка загружаемого расширения
$ wget -c https://www.sqlite.org/src/tarball/SQLite-trunk.tgz?uuid=trunk \
-O SQLite-trunk.tgz
.... output ...
$ tar -xzf SQLite-trunk.tgz
$ cd SQLite-trunk
$ ./configure && make fts5.c
... lots of output ...
$ ls fts5.[ch]
fts5.c fts5.h
3. Полнотекстовый синтаксис запроса
<phrase> := string [*]
<phrase> := <phrase> + <phrase>
<neargroup> := NEAR ( <phrase> <phrase> ... [, N] )
<query> := [ [-] <colspec> :] [^] <phrase>
<query> := [ [-] <colspec> :] <neargroup>
<query> := [ [-] <colspec> :] ( <query> )
<query> := <query> AND <query>
<query> := <query> OR <query>
<query> := <query> NOT <query>
<colspec> := colname
<colspec> := { colname1 colname2 ... }
3.1. Строки FTS5
Должны быть указаны последовательности, которые включают любые другие знаки.
Знаки, которые в настоящее время не разрешаются, не являются символами
кавычки и в настоящее время не служат любым особым целям выражениях запроса
FTS5, могут в какой-то момент в будущем позволяться или использоваться, чтобы
осуществить новую функциональность запроса.
Это означает, что запрашивть это в настоящее время является синтаксической
ошибкой, потому что включение такого символа за пределами указанной
последовательности может интерпретироваться по-другому некоторой
будущей версией FTS5.3.2. Фразы FTS5
... MATCH '"one two three"'
... MATCH 'one + two + three'
... MATCH '"one two" + three'
... MATCH 'one.two.three'
3.3. Запросы префикса FTS5
... MATCH '"one two thr" * '
... MATCH 'one + two + thr*'
... MATCH '"one two thr*"' -- May not work as expected!
3.4. Запросы начального токена FTS5
... MATCH '^one' -- first token in any column must be "one"
... MATCH '^ one + two'-- phrase "one two" must appear at start of a column
... MATCH '^ "one two"'-- same as previous
... MATCH 'a : ^two'-- first token of column "a" must be "two"
... MATCH 'NEAR(^one, two)' -- syntax error!
... MATCH 'one + ^two' -- syntax error!
... MATCH '"^one two"' -- May not work as expected!
3.5. Запросы FTS5 NEAR
... MATCH 'NEAR("one two" "three four", 10)'
... MATCH 'NEAR("one two" thr* + four)'
CREATE VIRTUAL TABLE f USING fts5(x);
INSERT INTO f(rowid, x) VALUES(1, 'A B C D x x x E F x');
... MATCH 'NEAR(e d, 4)'; -- Matches!
... MATCH 'NEAR(e d, 3)'; -- Matches!
... MATCH 'NEAR(e d, 2)'; -- Does not match!
... MATCH 'NEAR("c d" "e f", 3)'; -- Matches!
... MATCH 'NEAR("c" "e f", 3)'; -- Does not match!
... MATCH 'NEAR(a d e, 6)';-- Matches!
... MATCH 'NEAR(a d e, 5)';-- Does not match!
... MATCH 'NEAR("a b c d" "b c" "e f", 4)'; -- Matches!
... MATCH 'NEAR("a b c d" "b c" "e f", 3)'; -- Does not match!
3.6. Вертикальные фильтры FTS5
... MATCH 'colname : NEAR("one two" "three four", 10)'
... MATCH '"colname" : one + two + three'
... MATCH '{col1 col2} : NEAR("one two" "three four", 10)'
... MATCH '{col2 col1 col3} : one + two + three'
-- Search for matches in all columns except "colname"
... MATCH '- colname : NEAR("one two" "three four", 10)'
-- Search for matches in all columns except "col1", "col2" and "col3"
... MATCH '- {col2 col1 col3} : one + two + three'
-- The following are equivalent:
... MATCH '{a b} : ( {b c} : "hello" AND "world" )'
... MATCH '(b : "hello") AND ({a b} : "world")'
-- Given the following table
CREATE VIRTUAL TABLE ft USING fts5(a, b, c);
-- The following are equivalent
SELECT * FROM ft WHERE b MATCH 'uvw AND xyz';
SELECT * FROM ft WHERE ft MATCH 'b : (uvw AND xyz)';
-- This query cannot match any rows (since all columns are filtered out):
SELECT * FROM ft WHERE b MATCH 'a : xyz';
3.7. FTS5-операторы Boolean
Оператор Функция <query1>
NOT <query2>Совпадает, если query1 соответствует и query2 не соответствует. <query1> AND <query2>
Совпадает, если соответствуют query1 и query2. <query1>
OR <query2>Совпадает, если соответствует query1 или query2.
-- Because NOT groups more tightly than OR, either of the following may
-- be used to match all documents that contain the token "two" but not
-- "three", or contain the token "one".
... MATCH 'one OR two NOT three'
... MATCH 'one OR (two NOT three)'
-- Matches documents that contain at least one instance of either "one"
-- or "two", but do not contain any instances of token "three".
... MATCH '(one OR two) NOT three'
... MATCH 'one two three' -- 'one AND two AND three'
... MATCH 'three "one two"'-- 'three AND "one two"'
... MATCH 'NEAR(one two) three' -- 'NEAR(one two) AND three'
... MATCH 'one OR two three' -- 'one OR two AND three'
... MATCH 'one NOT two three' -- 'one NOT (two AND three)'
... MATCH '(one OR two) three' -- Syntax error!
... MATCH 'func(one two)' -- Syntax error!
4. Создание и запуск таблицы FTS5
CREATE VIRTUAL TABLE mail USING fts5(sender, title, body,
tokenize = 'porter ascii');
4.1. Опция UNINDEXED
CREATE VIRTUAL TABLE customers USING fts5(name, addr, uuid UNINDEXED);
4.2. Индексы префикса
-- Two ways to create an FTS5 table that maintains prefix indexes for
-- two and three character prefix tokens.
CREATE VIRTUAL TABLE ft USING fts5(a, b, prefix='2 3');
CREATE VIRTUAL TABLE ft USING fts5(a, b, prefix=2, prefix=3);
4.3. Токенизаторы
-- The following are all equivalent
CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = 'porter ascii');
CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = "porter ascii");
CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = "'porter' 'ascii'");
CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = '''porter'' ''ascii''');
-- But this will fail:
CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = '"porter" "ascii"');
-- This will fail too:
CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = 'porter' 'ascii');
4.3.1. Токенизатор Unicode61
Опция Использование remove_diacritics
Этот выбор должен быть установлен в "0", "1"
или "2". Значение по умолчанию равняется "1".
Если это установлено в "1" или "2", то диакритические
знаки удалены от латинских символов, как описано выше. Однако, если это
установлено в "1", тогда диакритические знаки не удалены в довольно
необычном случае, где единственная кодовая точка unicode используется, чтобы
представлять символ с больше, чем одним диакритическим знаком.
Например, диакритические знаки не удалены из кодовой точки 0x1ED9
("LATIN SMALL LETTER O WITH CIRCUMFLEX AND DOT BELOW").
Это технически ошибка, но не может быть исправлено, не создавая проблемы
совместимости. Если этот выбор установлен в "2", то диакритические
знаки правильно удалены от всех латинских символов. categories
Этот выбор может использоваться, чтобы изменить набор общих категорий
Unicode, которые, как полагают, соответствуют символическим знакам.
Аргумент должен состоять из отделенного пробелами
списка двухсимвольных сокращений общих категорий (например, "Lu" или "Nd")
или того же самого со вторым символом, замененным звездочкой ("*"),
интерпретируемой как образец. Значение по умолчанию: "L* N* Co". tokenchars
Этот выбор используется, чтобы определить дополнительные символы unicode,
которые нужно считать символическими, даже если они пробел или символы
пунктуации согласно Unicode 6.1. Все символы в последовательности, в которую
установлен этот выбор, считают символическими. separators
Этот выбор используется, чтобы определить дополнительные unicode-знаки,
которые нужно рассмотреть как символы разделителя, даже если они
символические персонажи согласно Unicode 6.1. Все знаки в последовательности,
в которую установлен этот выбор, считают сепараторами.
-- Create an FTS5 table that does not remove diacritics from Latin
-- script characters, and that considers hyphens and underscore characters
-- to be part of tokens.
CREATE VIRTUAL TABLE ft USING fts5(a, b,
tokenize = "unicode61 remove_diacritics 0 tokenchars '-_'"
);
-- Create an FTS5 table that, as well as the default token character classes,
-- considers characters in class "Mn" to be token characters.
CREATE VIRTUAL TABLE ft USING fts5(a, b, tokenize = "unicode61 categories
'L* N* Co Mn'");
4.3.2. Токенизатор Ascii
-- Create an FTS5 table that uses the ascii tokenizer, but does not
-- consider numeric characters to be part of tokens.
CREATE VIRTUAL TABLE ft USING fts5(a, b, tokenize = "ascii separators
'0123456789'");
4.3.3. Токенизатор Porter
-- Two ways to create an FTS5 table that uses the porter tokenizer to
-- stem the output of the default tokenizer (unicode61).
CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = porter);
CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = 'porter unicode61');
-- A porter tokenizer used to stem the output of the unicode61 tokenizer,
-- with diacritics removed before stemming.
CREATE VIRTUAL TABLE t1 USING fts5(x, tokenize = 'porter unicode61 remove_diacritics 1');
4.3.4. Токенизатор Trigram
CREATE VIRTUAL TABLE tri USING fts5(a, tokenize="trigram");
INSERT INTO tri VALUES('abcdefghij KLMNOPQRST uvwxyz');
-- The following queries all match the single row in the table
SELECT * FROM tri('cdefg');
SELECT * FROM tri('cdefg AND pqr');
SELECT * FROM tri('"hij klm" NOT stuv');
-- A case-sensitive trigram index
CREATE VIRTUAL TABLE tri USING fts5(a, tokenize="trigram case_sensitive 1");
SELECT * FROM tri WHERE a LIKE '%cdefg%';
SELECT * FROM tri WHERE a GLOB '*ij klm*xyz';
4.4. Внешнее содержание и таблицы Contentless
4.4.1. Таблицы Contentless
CREATE VIRTUAL TABLE f1 USING fts5(a, b, c, content='');
4.4.2. Таблицы Contentless-Delete
CREATE VIRTUAL TABLE f1 USING fts5(a,b,c, content='', contentless_delete=1);
-- Supported UPDATE statement:
UPDATE f1 SET a=?, b=?, c=? WHERE rowid=?;
-- This UPDATE is not supported, as it does not supply a new value
-- for column "c".
UPDATE f1 SET a=?, b=? WHERE rowid=?;
4.4.3. Внешние таблицы содержания
SELECT <content_rowid>, <cols> FROM <content>
WHERE <content_rowid> = ?;
-- If the database schema is:
CREATE TABLE tbl (a, b, c, d INTEGER PRIMARY KEY);
CREATE VIRTUAL TABLE fts USING fts5(a, c, content=tbl, content_rowid=d);
-- Fts5 may issue queries such as:
SELECT d, a, c FROM tbl WHERE d = ?;
SELECT <content_rowid>, <cols> FROM <content>
ORDER BY <content_rowid> ASC;
SELECT <content_rowid>, <cols> FROM <content>
ORDER BY <content_rowid> DESC;
-- Create a table. And an external content fts5 table to index it.
CREATE TABLE tbl(a INTEGER PRIMARY KEY, b, c);
CREATE VIRTUAL TABLE fts_idx USING fts5(b, c, content='tbl',
content_rowid='a');
-- Triggers to keep the FTS index up to date.
CREATE TRIGGER tbl_ai AFTER INSERT ON tbl BEGIN
INSERT INTO fts_idx(rowid, b, c) VALUES (new.a, new.b, new.c);
END;
CREATE TRIGGER tbl_ad AFTER DELETE ON tbl BEGIN
INSERT INTO fts_idx(fts_idx, rowid, b, c)
VALUES('delete', old.a, old.b, old.c);
END;
CREATE TRIGGER tbl_au AFTER UPDATE ON tbl BEGIN
INSERT INTO fts_idx(fts_idx, rowid, b, c)
VALUES('delete', old.a, old.b, old.c);
INSERT INTO fts_idx(rowid, b, c) VALUES (new.a, new.b, new.c);
END;
4.4.4. Ловушки внешних таблиц содержания
SELECT <content_rowid>, <cols> FROM <content>
WHERE <content_rowid> = ?;
-- Create and populate a table.
CREATE TABLE tbl(a INTEGER PRIMARY KEY, t TEXT);
INSERT INTO tbl VALUES(1, 'all that glitters');
INSERT INTO tbl VALUES(2, 'is not gold');
-- Create an external content FTS5 table
CREATE VIRTUAL TABLE ft USING fts5(t, content='tbl', content_rowid='a');
-- Returns 2 rows. Because the query does not use the FTS index, it is
-- effectively executed against table 'tbl' directly, and so returns
-- both rows.
SELECT * FROM t1;
-- Returns 0 rows. This query does use the FTS index, which currently
-- contains no entries. So it returns 0 rows.
SELECT rowid, t FROM t1('gold')
-- Create and populate a table.
CREATE TABLE tbl(a INTEGER PRIMARY KEY, t TEXT);
-- Create an external content FTS5 table
CREATE VIRTUAL TABLE ft USING fts5(t, content='tbl', content_rowid='a');
INSERT INTO ft(rowid, t) VALUES(1, 'all that glitters');
INSERT INTO ft(rowid, t) VALUES(2, 'is not gold');
-- Returns 0 rows. Since it does not use the FTS index, the query is
-- passed directly through to table 'tbl', which contains no data.
SELECT * FROM t1;
-- Returns 1 row. The "rowid" field of the returned row is 2, and
-- the "t" field set to NULL. "t" is set to NULL because when the external
-- content table "tbl" was queried for the data associated with the row
-- with a=2 ("a" is the content_rowid column), none could be found.
SELECT rowid, t FROM t1('gold')
-- Create and populate a table.
CREATE TABLE tbl(a INTEGER PRIMARY KEY, t TEXT);
INSERT INTO tbl VALUES(1, 'all that glitters');
INSERT INTO tbl VALUES(2, 'is not gold');
-- Create an external content FTS5 table
CREATE VIRTUAL TABLE ft USING fts5(t, content='tbl', content_rowid='a');
-- Create triggers to keep the FTS5 table up to date
CREATE TRIGGER tbl_ai AFTER INSERT ON tbl BEGIN
INSERT INTO ft(rowid, t) VALUES (new.a, new.t);
END;
<similar triggers for update + delete>
4.5. Опция Columnsize
-- A table without the xColumnSize() values stored on disk:
CREATE VIRTUAL TABLE ft USING fts5(a, b, c, columnsize=0);
-- Three equivalent ways of creating a table that does store the
-- xColumnSize() values on disk:
CREATE VIRTUAL TABLE ft USING fts5(a, b, c);
CREATE VIRTUAL TABLE ft USING fts5(a, b, c, columnsize=1);
CREATE VIRTUAL TABLE ft USING fts5(a, b, columnsize='1', c);
4.6. Опция Detail
-- The following two lines are equivalent (because the default value
-- of "detail" is "full".
CREATE VIRTUAL TABLE ft1 USING fts5(a, b, c);
CREATE VIRTUAL TABLE ft1 USING fts5(a, b, c, detail=full);
CREATE VIRTUAL TABLE ft2 USING fts5(a, b, c, detail=column);
CREATE VIRTUAL TABLE ft3 USING fts5(a, b, c, detail=none);
5. Вспомогательные функции
SELECT highlight(email, 2, '<b>', '</b>') FROM email
WHERE email MATCH 'fts5'
5.1.
Встроенные вспомогательные функции
5.1.1.
Функция bm25()
SELECT * FROM fts WHERE fts MATCH ? ORDER BY bm25(fts)

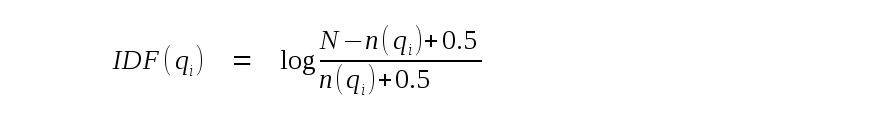
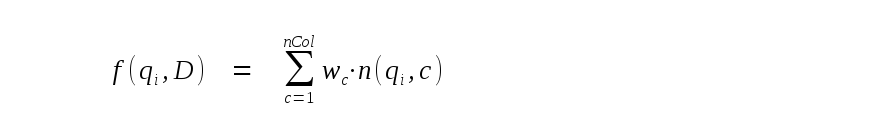
-- Assuming the following schema:
CREATE VIRTUAL TABLE email USING fts5(sender, title, body);
-- Return results in bm25 order, with each phrase hit in the "sender"
-- column considered the equal of 10 hits in the "body" column, and
-- each hit in the "title" column considered as valuable as 5 hits in
-- the "body" column.
SELECT * FROM email WHERE email MATCH ? ORDER BY bm25(email, 10.0, 5.0);
5.1.2.
Функция highlight()
-- Return a copy of the text from the leftmost column of the current
-- row, with phrase matches marked using html "b" tags.
SELECT highlight(fts, 0, '<b>', '</b>') FROM fts WHERE fts MATCH ?
-- Assuming this:
CREATE VIRTUAL TABLE ft USING fts5(a);
INSERT INTO ft VALUES('a b c x c d e');
INSERT INTO ft VALUES('a b c c d e');
INSERT INTO ft VALUES('a b c d e');
-- The following SELECT statement returns these three rows:
-- '[a b c] x [c d e]'
-- '[a b c] [c d e]'
-- '[a b c d e]'
SELECT highlight(ft, 0, '[', ']') FROM ft WHERE ft MATCH 'a+b+c AND c+d+e';
5.1.3.
Функция snippet()
5.2.
Сортировка результатов вспомогательными функции
-- The following queries are logically equivalent. But the second may
-- be faster, particularly if the caller abandons the query before
-- all rows have been returned (or if the queries were modified to
-- include LIMIT clauses).
SELECT * FROM fts WHERE fts MATCH ? ORDER BY bm25(fts);
SELECT * FROM fts WHERE fts MATCH ? ORDER BY rank;
rank MATCH 'auxiliary-function-name(arg1, arg2, ...)'
rank = 'auxiliary-function-name(arg1, arg2, ...)'
-- The following queries are logically equivalent. But the second may
-- be faster. See above.
SELECT * FROM fts WHERE fts MATCH ? ORDER BY bm25(fts, 10.0, 5.0);
SELECT * FROM fts WHERE fts MATCH ? AND rank MATCH 'bm25(10.0, 5.0)' ORDER BY rank;
SELECT * FROM fts WHERE fts MATCH ? AND rank MATCH 'bm25(10.0, 5.0)'
ORDER BY rank;
SELECT * FROM fts WHERE fts = ? AND rank = 'bm25(10.0, 5.0)' ORDER BY rank;
SELECT * FROM fts WHERE fts(?, 'bm25(10.0, 5.0)') ORDER BY rank;
6.
Специальные команды INSERT
6.1. Опция 'automerge'
INSERT INTO ft(ft, rank) VALUES('automerge', 8);
6.2.
Опция 'crisismerge'
INSERT INTO ft(ft, rank) VALUES('crisismerge', 16);
6.3.
Команда 'delete'
-- Insert a row with rowid=14 into the fts5 table.
INSERT INTO ft(rowid, a, b, c) VALUES(14, $a, $b, $c);
-- Remove the same row from the fts5 table.
INSERT INTO ft(ft, rowid, a, b, c) VALUES('delete', 14, $a, $b, $c);
6.4. Команда 'delete-all'
INSERT INTO ft(ft) VALUES('delete-all');
6.5. Опция 'deletemerge'
INSERT INTO ft(ft, rank) VALUES('deletemerge', 15);
6.6.
Команда 'integrity-check'
INSERT INTO ft(ft) VALUES('integrity-check');
INSERT INTO ft(ft, rank) VALUES('integrity-check', 0);
INSERT INTO ft(ft, rank) VALUES('integrity-check', 1);
6.7. Команда 'merge'
INSERT INTO ft(ft, rank) VALUES('merge', 500);
6.8. Команда 'optimize'
INSERT INTO ft(ft) VALUES('optimize');
6.9. Опция 'pgsz'
INSERT INTO ft(ft, rank) VALUES('pgsz', 4072);
6.10. Опция 'rank'
INSERT INTO ft(ft, rank) VALUES('rank', 'bm25(10.0, 5.0)');
6.11. Команда 'rebuild'
INSERT INTO ft(ft) VALUES('rebuild');
6.12. Опция 'secure-delete'
INSERT INTO ft(ft, rank) VALUES('secure-delete', 1);
6.13. Опция 'usermerge'
INSERT INTO ft(ft, rank) VALUES('usermerge', 4);
7. Улучшение FTS5
/*
** Return a pointer to the fts5_api pointer for database connection db.
** If an error occurs, return NULL and leave an error in the database
** handle (accessible using sqlite3_errcode()/errmsg()).
*/
fts5_api *fts5_api_from_db(sqlite3 *db){
fts5_api *pRet = 0;
sqlite3_stmt *pStmt = 0;
if( SQLITE_OK==sqlite3_prepare(db, "SELECT fts5(?1)", -1, &pStmt, 0) ){
sqlite3_bind_pointer(pStmt, 1, (void*)&pRet, "fts5_api_ptr", NULL);
sqlite3_step(pStmt);
}
sqlite3_finalize(pStmt);
return pRet;
}
typedef struct fts5_api fts5_api;
struct fts5_api {
int iVersion; /* Currently always set to 2 */
/* Create a new tokenizer */
int (*xCreateTokenizer)(fts5_api *pApi, const char *zName, void *pUserData,
fts5_tokenizer *pTokenizer,
void (*xDestroy)(void*));
/* Find an existing tokenizer */
int (*xFindTokenizer)(fts5_api *pApi, const char *zName, void **ppUserData,
fts5_tokenizer *pTokenizer);
/* Create a new auxiliary function */
int (*xCreateFunction) (fts5_api *pApi, const char *zName, void *pUserData,
fts5_extension_function xFunction,
void (*xDestroy)(void*));
};
rc = pFts5Api->xCreateTokenizer(pFts5Api, ... other args ...);
7.1. Свои токенизаторы
typedef struct Fts5Tokenizer Fts5Tokenizer;
typedef struct fts5_tokenizer fts5_tokenizer;
struct fts5_tokenizer {
int (*xCreate)(void*, const char **azArg, int nArg, Fts5Tokenizer **ppOut);
void (*xDelete) (Fts5Tokenizer*);
int (*xTokenize) (Fts5Tokenizer*, void *pCtx,
int flags, /* Mask of FTS5_TOKENIZE_* flags */
const char *pText, int nText,
int (*xToken)(
void *pCtx, /* Copy of 2nd argument to xTokenize() */
int tflags, /* Mask of FTS5_TOKEN_* flags */
const char *pToken, /* Pointer to buffer containing token */
int nToken, /* Size of token in bytes */
int iStart, /* Byte offset of token within input text */
int iEnd /* Byte offset of end of token within input text */
)
);
};
/* Flags that may be passed as the third argument to xTokenize() */
#define FTS5_TOKENIZE_QUERY 0x0001
#define FTS5_TOKENIZE_PREFIX 0x0002
#define FTS5_TOKENIZE_DOCUMENT 0x0004
#define FTS5_TOKENIZE_AUX0x0008
/* Flags that may be passed by the tokenizer implementation back to FTS5
** as the third argument to the supplied xToken callback. */
#define FTS5_TOKEN_COLOCATED 0x0001 /* Same position as prev. token */
7.1.1. Поддержка синонимов
... MATCH 'first place'
... MATCH '(first OR 1st) place'
xToken(pCtx, 0, "i", 1, 0, 1);
xToken(pCtx, 0, "won",3, 2, 5);
xToken(pCtx, 0, "first", 5, 6, 11);
xToken(pCtx, FTS5_TOKEN_COLOCATED, "1st", 3, 6, 11);
xToken(pCtx, 0, "place", 5, 12, 17);
... MATCH '1s*'
7.2. Свои вспомогательные функции
typedef struct Fts5ExtensionApi Fts5ExtensionApi;
typedef struct Fts5Context Fts5Context;
typedef struct Fts5PhraseIter Fts5PhraseIter;
typedef void (*fts5_extension_function)(
const Fts5ExtensionApi *pApi, /* API offered by current FTS version */
Fts5Context *pFts, /* First arg to pass to pApi functions */
sqlite3_context *pCtx,/* Context for returning result/error */
int nVal, /* Number of values in apVal[] array */
sqlite3_value **apVal /* Array of trailing arguments */
);
/*
** Implementation of an auxiliary function that returns the number
** of tokens in the current row (including all columns).
*/
static void column_size_imp(const Fts5ExtensionApi *pApi, Fts5Context *pFts,
sqlite3_context *pCtx, int nVal,
sqlite3_value **apVal)
{
int rc;
int nToken;
rc = pApi->xColumnSize(pFts, -1, &nToken);
if( rc==SQLITE_OK ){
sqlite3_result_int(pCtx, nToken);
}else{
sqlite3_result_error_code(pCtx, rc);
}
}
7.2.1.
Свои вспомогательные функции API
struct Fts5ExtensionApi {
int iVersion; /* Currently always set to 2 */
void *(*xUserData)(Fts5Context*);
int (*xColumnCount)(Fts5Context*);
int (*xRowCount)(Fts5Context*, sqlite3_int64 *pnRow);
int (*xColumnTotalSize)(Fts5Context*, int iCol, sqlite3_int64 *pnToken);
int (*xTokenize)(Fts5Context*,
const char *pText, int nText, /* Text to tokenize */
void *pCtx, /* Context passed to xToken() */
int (*xToken)(void*, int, const char*, int, int, int)/* Callback */
);
int (*xPhraseCount)(Fts5Context*);
int (*xPhraseSize)(Fts5Context*, int iPhrase);
int (*xInstCount)(Fts5Context*, int *pnInst);
int (*xInst)(Fts5Context*, int iIdx, int *piPhrase, int *piCol, int *piOff);
sqlite3_int64 (*xRowid)(Fts5Context*);
int (*xColumnText)(Fts5Context*, int iCol, const char **pz, int *pn);
int (*xColumnSize)(Fts5Context*, int iCol, int *pnToken);
int (*xQueryPhrase)(Fts5Context*, int iPhrase, void *pUserData,
int(*)(const Fts5ExtensionApi*,Fts5Context*,void*)
);
int (*xSetAuxdata)(Fts5Context*, void *pAux, void(*xDelete)(void*));
void *(*xGetAuxdata)(Fts5Context*, int bClear);
int (*xPhraseFirst)(Fts5Context*, int iPhrase, Fts5PhraseIter*, int*, int*);
void (*xPhraseNext)(Fts5Context*, Fts5PhraseIter*, int *piCol, int *piOff);
int (*xPhraseFirstColumn)(Fts5Context*, int iPhrase, Fts5PhraseIter*, int*);
void (*xPhraseNextColumn)(Fts5Context*, Fts5PhraseIter*, int *piCol);
};
... FROM ftstable WHERE ftstable MATCH $p ORDER BY rowid
SELECT count(*) FROM ftstable;
Fts5PhraseIter iter;
int iCol, iOff;
for (pApi->xPhraseFirst(pFts, iPhrase, &iter, &iCol, &iOff); iCol>=0;
pApi->xPhraseNext(pFts, &iter, &iCol, &iOff))
{
// An instance of phrase iPhrase at offset iOff of column iCol
}
Fts5PhraseIter iter;
int iCol;
for (pApi->xPhraseFirstColumn(pFts, iPhrase, &iter, &iCol); iCol>=0;
pApi->xPhraseNextColumn(pFts, &iter, &iCol))
{
// Column iCol contains at least one instance of phrase iPhrase
}
8. Виртуальный модуль таблицы fts5vocab
-- Create an fts5vocab "row" table to query the full-text index belonging
-- to FTS5 table "ft1".
CREATE VIRTUAL TABLE ft1_v USING fts5vocab('ft1', 'row');
-- Create an fts5vocab "col" table to query the full-text index belonging
-- to FTS5 table "ft2".
CREATE VIRTUAL TABLE ft2_v USING fts5vocab(ft2, col);
-- Create an fts5vocab "instance" table to query the full-text index
-- belonging to FTS5 table "ft3".
CREATE VIRTUAL TABLE ft3_v USING fts5vocab(ft3, instance);
-- Create an fts5vocab "row" table to query the full-text index belonging
-- to FTS5 table "ft1" in database "main".
CREATE VIRTUAL TABLE temp.ft1_v USING fts5vocab(main, 'ft1', 'row');
-- Create an fts5vocab "col" table to query the full-text index belonging
-- to FTS5 table "ft2" in attached database "aux".
CREATE VIRTUAL TABLE temp.ft2_v USING fts5vocab('aux', ft2, col);
-- Create an fts5vocab "instance" table to query the full-text index
-- belonging to FTS5 table "ft3" in attached database "other".
CREATE VIRTUAL TABLE temp.ft2_v USING fts5vocab('aux', ft3, 'instance');
Столбец Содержание term
Термин, как сохранено в индексе FTS5. doc
Количество рядов, которые содержат по крайней мере один случай термина.
cnt
Общее количество случаев термина во всей таблице FTS5.
Столбец Содержание term
Термин, как сохранено в индексе FTS5. col Название столбца таблицы FTS5,
который содержит термин. doc
Количество строк в таблице FTS5, для которых колонка $col содержит по
крайней мере один случай термина. cnt
Общее количество случаев термина, которые появляются в колонке $col
таблицы FTS5 (рассматривая все строки).
Столбец Содержание term
Термин, как сохранено в индексе FTS5. doc
rowid документа, который содержит случай термина. col
Название колонки, которая содержит случай термина. offset Индекс случая термина в рамках
его колонки. Термины пронумерованы в порядке возникновения с 0.
-- Assuming a database created using:
CREATE VIRTUAL TABLE ft1 USING fts5(c1, c2);
INSERT INTO ft1 VALUES('apple banana cherry', 'banana banana cherry');
INSERT INTO ft1 VALUES('cherry cherry cherry', 'date date date');
-- Then querying the following fts5vocab table (type "col") returns:
--
-- apple | c1 | 1 | 1
-- banana | c1 | 1 | 1
-- banana | c2 | 1 | 2
-- cherry | c1 | 2 | 4
-- cherry | c2 | 1 | 1
-- date | c3 | 1 | 3
--
CREATE VIRTUAL TABLE ft1_v_col USING fts5vocab(ft1, col);
-- Querying an fts5vocab table of type "row" returns:
--
-- apple | 1 | 1
-- banana | 1 | 3
-- cherry | 2 | 5
-- date | 1 | 3
--
CREATE VIRTUAL TABLE ft1_v_row USING fts5vocab(ft1, row);
-- And, for type "instance"
INSERT INTO ft1 VALUES('apple banana cherry', 'banana banana cherry');
INSERT INTO ft1 VALUES('cherry cherry cherry', 'date date date');
--
-- apple | 1 | c1 | 0
-- banana | 1 | c1 | 1
-- banana | 1 | c2 | 0
-- banana | 1 | c2 | 1
-- cherry | 1 | c1 | 2
-- cherry | 1 | c2 | 2
-- cherry | 2 | c1 | 0
-- cherry | 2 | c1 | 1
-- cherry | 2 | c1 | 2
-- date | 2 | c2 | 0
-- date | 2 | c2 | 1
-- date | 2 | c2 | 2
--
CREATE VIRTUAL TABLE ft1_v_instance USING fts5vocab(ft1, instance);
9. Структура данных FTS5
-- This table contains most of the full-text index data.
CREATE TABLE %_data(id INTEGER PRIMARY KEY, block BLOB);
-- This table contains the remainder of the full-text index data.
-- It is almost always much smaller than the %_data table.
CREATE TABLE %_idx(segid, term, pgno, PRIMARY KEY(segid, term)) WITHOUT ROWID;
-- Contains the values of persistent configuration parameters.
CREATE TABLE %_config(k PRIMARY KEY, v) WITHOUT ROWID;
-- Contains the size of each column of each row in the virtual table
-- in tokens. This shadow table is not present if the "columnsize"
-- option is set to 0.
CREATE TABLE %_docsize(id INTEGER PRIMARY KEY, sz BLOB);
-- Contains the actual data inserted into the FTS5 table. There
-- is one "cN" column for each indexed column in the FTS5 table.
-- This shadow table is not present for contentless or external
-- content FTS5 tables.
CREATE TABLE %_content(id INTEGER PRIMARY KEY, c0, c1...);
9.1. Формат Varint
9.2.
Индекс FTS (таблицы %_idx и %_data)
SELECT ... FROM fts_table('term') WHERE rowid BETWEEN ? AND ?
9.2.1. Пространство Rowid таблицы %_data
CREATE TABLE %_data(id INTEGER PRIMARY KEY, block BLOB);
Биты Rowid Содержание 38..43
(16 бит) Значение идентификатора b-дерева сегмента. 37 (1 бит) Флаг индекса Doclist.
Установлен для индексных страниц doclist для листьев b-дерева сегмента.
32..36
(5 бит) Высота в дереве. Это установлено в 0 для b-дерева сегмента
и doclist листьев индекса, в 1 для родителей doclist листьев индекса, 2 для
их предков и т.д. 0..31
(32 бита) Номер страницы
9.2.2. Формат структуры записи
9.2.3. Формат средней записи
9.2.4. Формат B-дерева сегмента
9.2.4.1. Формат Key/Doclist
2, 12, 7, 3
9.2.4.2. Нумерация страниц
9.2.4.3. Формат индекса сегмента
CREATE TABLE %_idx(
segid INTEGER, -- segment id
term TEXT, -- prefix of first key on page
pgno INTEGER, -- (2*pgno + bDoclistIndex)
PRIMARY KEY(segid, term)
);
Столбец Содержание segid
integer segment id. term
Самый маленький префикс первого ключа на странице, который больше, чем
все ключи на предыдущей странице. Для первой страницы в сегменте этот
префикс 0 байт в размере. pgno
Эта область кодирует номер страницы (в сегменте начинается с 1) и
флаг индекса doclist. Флаг индекса doclist установлен, если финальный ключ
на странице имеет связанный индекс
doclist. Значение этой области:
(pgno*2 + bDoclistIndexFlag)
SELECT pgno FROM %_idx WHERE segid=$i AND term>=$t ORDER BY term LIMIT 1
9.2.4.4. Формат индекса Doclist
9.3. Таблица размеров документа (таблица %_docsize)
CREATE TABLE %_docsize(
id INTEGER PRIMARY KEY, -- id of FTS5 row this record pertains to
sz BLOB -- blob containing nCol packed varints
);
9.4. Содержание таблицы (таблица %_content)
CREATE TABLE %_content(id INTEGER PRIMARY KEY, c0, c1...);
9.5. Опции настройки (таблица %_config)
CREATE TABLE %_config(k PRIMARY KEY, v) WITHOUT ROWID;
sqlite> SELECT * FROM fts_tbl_config;
+-------------+------+
| k | v |
+-------------+------+
| crisismerge | 8 |
| pgsz | 8000 |
| usermerge | 4 |
| version | 4 |
+--------------------+
Приложение A: Сравнение с FTS3/4
Портирование
Изменения в CREATE VIRTUAL TABLE
-- FTS3/4 statement
CREATE VIRTUAL TABLE t1 USING fts4(linkid INTEGER, header CHAR(20),
text VARCHAR, notindexed=linkid,
matchinfo=fts3, tokenizer=unicode61);
-- FTS5 equivalent (note - the "tokenizer=unicode61" option is not
-- required as this is the default for FTS5 anyway)
CREATE VIRTUAL TABLE t1 USING fts5(linkid UNINDEXED, header, text,
columnsize=0);
Изменения в SELECT
... a MATCH 'b: string'
Изменения вспомогательных функций
Другие проблемы
Резюме технических различий
-- Given the following SQL:
CREATE VIRTUAL TABLE ft USING fts5(a, b);
INSERT INTO ft(rowid, a, b) VALUES(1, 'X Y', 'Y Z');
INSERT INTO ft(rowid, a, b) VALUES(2, 'A Z', 'Y Y');
-- The FTS5 module creates the following mapping on disk:
A --> (2, 0, 0)
X --> (1, 0, 0)
Y --> (1, 0, 1) (1, 1, 0) (2, 1, 0) (2, 1, 1)
Z --> (1, 1, 1) (2, 0, 1)