
Small. Fast. Reliable.
Choose any three.
Обзор
FTS3 и FTS4 это виртуальные модули таблицы SQLite, которые
позволяют пользователям выполнять полнотекстовые поиски на ряде документов.
Наиболее распространенный (и эффективный) способ описать полнотекстовые
поиски, "то, что Google, Yahoo и Бинг делают с документами, помещенными
во Всемирную паутину". Пользователи вводят термин или ряд условий,
возможно, связанных бинарным оператором или сгруппированных
во фразу, и полнотекстовая система запросов находит набор документов, которые
определили лучшие соответствия тем условиям, считая операторы и группировки
пользователем. Эта статья описывает развертывание и
использование FTS3 и FTS4.
FTS1 и FTS2 это устаревшие полнотекстовые модули поиска для SQLite.
Там известны проблемы с этими более старыми модулями и их использованием,
которых нужно избежать. Части оригинального кода FTS3
были внесены в проект SQLite от Google.
Это теперь развивается и сохраняется как часть SQLite.
1. Введение в FTS3 и FTS4
FTS3 и дополнительные модули FTS4 позволяют пользователям составлять
специальные таблицы со встроенным полнотекстовым индексом (после этого
"таблицы FTS"). Полнотекстовый индекс позволяет пользователю эффективно
запрашивать базу данных для всех строк, которые содержат одно или более слов
(после этого "символы"), даже если таблица содержит
много больших документов.
Например, если каждый из этих 517430 документов в
"Enron E-Mail Dataset"
вставляется в таблицу FTS и в обычную таблицу SQLite, созданную с
использованием следующего SQL:
CREATE VIRTUAL TABLE enrondata1 USING fts3(content TEXT); /* FTS3 table */
CREATE TABLE enrondata2(content TEXT); /* Ordinary table */
любой из двух запросов ниже может быть выполнен, чтобы найти количество
документов в базе данных, которые содержат слово "linux" (351).
Используя одну аппаратную конфигурацию настольного ПК, запрос на таблице FTS3
возвращается приблизительно через 0.03 секунды, против 22.5
для обычной таблицы.
SELECT count(*) FROM enrondata1 WHERE content MATCH 'linux'; /* 0.03 seconds */
SELECT count(*) FROM enrondata2 WHERE content LIKE '%linux%'; /* 22.5 seconds */
Конечно, два запроса выше не совсем эквивалентны. Например, запрос LIKE
соответствует строким, которые содержат условия, такие как "linuxophobe"
или "EnterpriseLinux" (Enron E-Mail Dataset на самом деле не содержит никакие
подобные условия), тогда как запрос MATCH на таблице FTS3 выбирает только те
строки, которые содержат "Linux" как дискретный символ.
Оба поиска нечувствительные к регистру. Таблица FTS3 потребляет
приблизительно 2006 МБ на диске по сравнению со всего 1453 МБ для обычной
таблицы. Используя ту же самую аппаратную конфигурацию, используемую, чтобы
выполнить SELECT выше, таблица FTS3 занял чуть менее чем 31 минуту, чтобы
наполниться, против 25 для обычной таблицы.
1.1. Разница между FTS3 и FTS4
FTS3 и FTS4 почти идентичны. Они разделяют большую
часть своего кода вместе, и их интерфейсы это то же самое. Различия:
FTS4 содержит оптимизацию производительности запросов, которая
может значительно улучшить исполнение полнотекстовых запросов, которые
содержат условия, которые очень распространены (существующие в большом
проценте строк таблицы). FTS4 поддерживает некоторые дополнительные опции, которые могут
использоваться с функцией matchinfo()
. Поскольку это хранит дополнительную информацию на диске в двух новых
теневых таблицах, чтобы поддержать
исполнительную оптимизацию и дополнительные варианты matchinfo(), таблицы
FTS4 могут потреблять больше дискового пространства, чем переводная таблица,
составленная, используя FTS3. Обычно издержки составят 1-2% или меньше, но
могут составлять целых 10%, если документы в таблице FTS, очень маленькие.
Это может быть уменьшено, определив
"matchinfo=fts3" как часть декларации таблицы FTS4, но это за счет
принесения в жертву части дополнительных опций matchinfo(). FTS4 обеспечивает перехватчики (опции
compress и uncompress),
позвоялющие данным быть сохраненным в сжатой форме, уменьшая
использование диска и IO.
FTS4 это улучшение к FTS3. FTS3 был доступен начиная с
SQLite version 3.5.0 (2007-09-04).
Улучшения для FTS4 были добавлены с SQLite
version 3.7.4 (2010-12-07).
Какой модуль, FTS3 или FTS4, необходимо использовать в приложении?
FTS4 иногда значительно быстрее, чем FTS3, даже на порядки величины быстрее в
зависимости от запроса, хотя в общем случае исполнение этих двух модулей
подобно. FTS4 также предлагает расширенный
matchinfo() вывод, который может быть полезен в рейтинге результатов
операции MATCH.
С другой стороны, в отсутствие
matchinfo=fts3 FTS4 требует немного большего количества дискового
пространства, чем FTS3, хотя только процента на два в большинстве случаев.
Для более новых приложений рекомендуется FTS4, хотя, если совместимость с
более старыми версиями SQLite будет важна, то FTS3 будет обычно служить
точно так же.
1.2.
Создание и удаление таблиц FTS
Как другие виртуальные типы таблицы, новые таблицы FTS составлены,
используя CREATE VIRTUAL TABLE.
Имя модуля, которое следует за ключевым словом USING, является "fts3" или
"fts4". Виртуальные аргументы модуля таблицы можно оставить пустыми, в этом
случае таблица FTS с определенной отдельными пользователями колонкой,
названной "content", составлена. Альтернативно, аргументы модуля могут быть
переданы в виде разделенного запятыми списка имен столбцов.
Если имена столбцов явно обеспечиваются для таблицы FTS как часть CREATE
VIRTUAL, то имя типа данных может быть произвольно определено для каждой
колонки. Это чистый синтаксический трюк, поставляемые имена типов не
используются FTS или ядром SQLite ни для какой цели.
То же самое относится к любым ограничениям, определенным наряду с именем
столбца FTS: они разбираются, но не используются или регистрируются
системой в любом случае.
-- Create an FTS table named "data" with one column - "content":
CREATE VIRTUAL TABLE data USING fts3();
-- Create an FTS table named "pages" with three columns:
CREATE VIRTUAL TABLE pages USING fts4(title, keywords, body);
-- Create an FTS table named "mail" with two columns. Datatypes
-- and column constraints are specified along with each column. These
-- are completely ignored by FTS and SQLite.
CREATE VIRTUAL TABLE mail USING fts3(subject VARCHAR(256) NOT NULL,
body TEXT CHECK(length(body)<10240));
А также список колонок, аргументы модуля, переданные CREATE VIRTUAL TABLE,
может использоваться, чтобы определить
токенизатор.
Это сделано, определив последовательность формы
"tokenize=<tokenizer name> <tokenizer args>"
вместо имени столбца, где <tokenizer name> это
название токенизатора, чтобы использовать, а <tokenizer args> это
дополнительный список отделенных пробелами определителей, чтобы передать
внедрению токенизатора. Спецификация токенизатора может быть помещена куда
угодно в списке столбцов, но самое большее одна декларация токенизатора
позволена для каждого CREATE VIRTUAL TABLE.
-- Create an FTS table named "papers" with two columns that uses
-- the tokenizer "porter".
CREATE VIRTUAL TABLE papers USING fts3(author, document, tokenize=porter);
-- Create an FTS table with a single column - "content" - that uses
-- the "simple" tokenizer.
CREATE VIRTUAL TABLE data USING fts4(tokenize=simple);
-- Create an FTS table with two columns that uses the "icu" tokenizer.
-- The qualifier "en_AU" is passed to the tokenizer implementation
CREATE VIRTUAL TABLE names USING fts3(a, b, tokenize=icu en_AU);
Таблицы FTS могут быть исключены из базы данных, используя обычный
запрос DROP TABLE:
-- Create, then immediately drop, an FTS4 table.
CREATE VIRTUAL TABLE data USING fts4();
DROP TABLE data;
1.3. Наполнение таблиц FTS
Таблицы FTS наполняются через INSERT,
UPDATE и DELETE
аналогично любым другим.
А также у колонок, названных пользователем (или колонки "content",
если никакие аргументы модуля не были определены как часть
CREATE VIRTUAL TABLE),
каждой таблицы FTS есть колонка "rowid". rowid таблиц FTS
ведет себя таким же образом как колонка rowid обычной таблицы SQLite, за
исключением того, что значения, сохраненные в колонке rowid таблицы FTS,
остаются неизменными, если база данных восстановлена, используя команду
VACUUM. Для таблиц FTS "docid"
позволен как псевдоним наряду с обычными идентификаторами
"rowid", "oid" и "_oid _".
Попытка вставить или обновить строку со значением docid, которая уже
существует в таблице, является ошибкой, как это было бы с
обычной таблицей SQLite.
Есть еще одно тонкое различие между "docid" и нормальными
псевдонимами SQLite для колонки rowid. Обычно, если запрос INSERT или UPDATE
назначает дискретные значения на два или больше псевдонима колонки rowid,
SQLite пишет самые правые из таких значений, определенных в INSERT или
UPDATE, в базу данных. Однако, назначение ненулевого значения к
"docid" и к одному или больше псевдонимов rowid, вставляя или
обновляя таблицу FTS, считают ошибкой. Посмотрите ниже для примера.
-- Create an FTS table
CREATE VIRTUAL TABLE pages USING fts4(title, body);
-- Insert a row with a specific docid value.
INSERT INTO pages(docid, title, body) VALUES(53, 'Home Page', 'SQLite is a software...');
-- Insert a row and allow FTS to assign a docid value using the same algorithm as
-- SQLite uses for ordinary tables. In this case the new docid will be 54,
-- one greater than the largest docid currently present in the table.
INSERT INTO pages(title, body) VALUES('Download', 'All SQLite source code...');
-- Change the title of the row just inserted.
UPDATE pages SET title = 'Download SQLite' WHERE rowid = 54;
-- Delete the entire table contents.
DELETE FROM pages;
-- The following is an error. It is not possible to assign non-NULL values to both
-- the rowid and docid columns of an FTS table.
INSERT INTO pages(rowid, docid, title, body) VALUES(1, 2, 'A title', 'A document body');
Чтобы поддержать полнотекстовые запросы, FTS поддерживает инвертированный
индекс, который отображает каждый уникальный термин или слово, которое
появляется в наборе данных к местоположениям, в которых это появляется в
содержании таблицы. Для любопытных имеется полное описание
структуры данных, используемой, чтобы
сохранить этот индекс в файле базы данных.
Особенность этой структуры данных в том, что в любое время база данных может
содержать не одно b-дерево индекса, а несколько различных b-деревьев, которые
с приращением слиты, поскольку строки вставлены, обновлены и удалены.
Эта техника улучшает работу при записи в таблицу FTS, но вызывает некоторые
издержки для полнотекстовых запросов, которые используют индекс.
Оценка специального предложения
"optimize", SQL-оператор формы
"INSERT INTO <fts-table>(<fts-table>) VALUES('optimize')",
заставляет FTS сливать все существующие b-деревья индекса в единственное
большое b-дерево, содержащее весь индекс.
Это может быть дорогой операцией, но может ускорить будущие запросы.
Например, чтобы оптимизировать полнотекстовый индекс для
таблицы FTS "docs":
-- Optimize the internal structure of FTS table "docs".
INSERT INTO docs(docs) VALUES('optimize');
Запрос выше может казаться синтаксически неправильным.
Обратитесь к секции, описывающей
простые запросы fts
, за подробностями.
Есть другой устаревший метод для вызова операции optimize, используя
оператор SELECT. Новый код должен использовать запросы, подобные INSERT
выше, чтобы оптимизировать структуры FTS.
1.4. Простые запросы FTS
Что касается всех других таблиц SQLite, виртуальных или иных,
данные восстанавливаются от таблиц FTS, используя
SELECT.
Таблицы FTS могут быть запрошены, эффективно используя операторы
SELECT двух различных форм:
Запрос по rowid. Если WHERE в SELECT
содержит подпункт формы "rowid = ?", где ? это выражение SQL, FTS
в состоянии восстановить требуемую строку, непосредственно используя
эквивалент индекса SQLite
INTEGER PRIMARY KEY. Полнотекстовый поиск. Если WHERE в SELECT
содержит подпункт формы "<column> MATCH ?", FTS
в состоянии использовать встроенный полнотекстовый индекс, чтобы ограничить
поиск теми документами, которые соответствуют полнотекстовой строке запроса,
определенной как правый операнд пункта MATCH.
Если ни одна из этих двух стратегий запроса не может использоваться, все
запросы на таблицах FTS осуществляются, используя линейный просмотр всей
таблицы. Если таблица содержит большие объемы данных, это может быть
непрактичным подходом (первый пример на этой странице показывает, что
линейный просмотр 1.5 ГБ данных занимает приблизительно 30 секунд,
используя современный PC).
-- The examples in this block assume the following FTS table:
CREATE VIRTUAL TABLE mail USING fts3(subject, body);
SELECT * FROM mail WHERE rowid = 15; -- Fast. Rowid lookup.
SELECT * FROM mail WHERE body MATCH 'sqlite';-- Fast. Full-text query.
SELECT * FROM mail WHERE mail MATCH 'search';-- Fast. Full-text query.
SELECT * FROM mail WHERE rowid BETWEEN 15 AND 20; -- Fast. Rowid lookup.
SELECT * FROM mail WHERE subject = 'database'; -- Slow. Linear scan.
SELECT * FROM mail WHERE subject MATCH 'database'; -- Fast. Full-text query.
Во всех полнотекстовых запросах выше правый операнд оператора MATCH
это последовательность, состоящая из единственного термина.
В этом случае выражение MATCH оценивается к true
для всех документов, которые содержат один или несколько случаев указанного
слова ("sqlite", "search" или "database", в зависимости от примера).
Определение единственного термина в качестве правого операнда оператора MATCH
приводит к самому простому и наиболее распространенному типу полнотекстового
возможного запроса. Однако, более сложные запросы возможны, включая поиски
фразы, поиски префикса термина и документа, содержащего комбинации условий,
происходящих в определенной близости друг от друга. Различные пути, которыми
может быть запрошен полнотекстовый индекс,
описаны ниже.
Обычно полнотекстовые запросы нечувствительные к регистру.
Однако, это зависит от определенного
токенизатора, используемого таблицей FTS.
Обратитесь к секции здесь.
Параграф выше отмечает, что оператор MATCH с простым термином в качестве
правого операнда оценивается к true
для всех документов, которые содержат указанный термин. В этом контексте
"документ" может относиться к данным
в отдельном столбце строки таблицы FTS или к содержанию всех колонок в
единственной строке, в зависимости от идентификатора, используемого в
качестве левого операнда оператору MATCH. Если идентификатор, определенный
как левый операнд оператора MATCH, является названием столбца таблицы FTS, то
документ, в котором должен содержаться критерий поиска, является значением,
сохраненным в указанной колонке. Однако, если идентификатор это название
самой таблицы FTS, то оператор MATCH оценивается к true для каждой
строки таблицы FTS, для которой любая колонка содержит критерий поиска.
Следующий пример демонстрирует это:
-- Example schema
CREATE VIRTUAL TABLE mail USING fts3(subject, body);
-- Example table population
INSERT INTO mail(docid, subject, body) VALUES(1, 'software feedback', 'found it too slow');
INSERT INTO mail(docid, subject, body) VALUES(2, 'software feedback', 'no feedback');
INSERT INTO mail(docid, subject, body) VALUES(3, 'slow lunch order', 'was a software problem');
-- Example queries
SELECT * FROM mail WHERE subject MATCH 'software'; -- Selects rows 1 and 2
SELECT * FROM mail WHERE body MATCH 'feedback'; -- Selects row 2
SELECT * FROM mail WHERE mail MATCH 'software'; -- Selects rows 1, 2 and 3
SELECT * FROM mail WHERE mail MATCH 'slow'; -- Selects rows 1 and 3
На первый взгляд заключительные два полнотекстовых запроса в примере выше,
кажется, синтаксически неправильные, поскольку есть имя таблицы ("mail"),
используемое в качестве SQL-выражения. Причина этого состоит в том, что у
каждой таблицы FTS на самом деле есть столбец
HIDDEN
с тем же самым именем, как сама таблица (в этом случае "mail").
Значение, сохраненная в этой колонке, не значащее для приложения, но может
использоваться в качестве левого операнда оператору MATCH.
Эта специальная колонка может также быть передана как аргумент
вспомогательным функциям FTS.
Следующий пример иллюстрирует вышеупомянутое. Выражения "docs",
"docs.docs" и "main.docs.docs" отсылают к колонке "docs".
Однако, выражение "main.docs" не обращается ни к какой колонке.
Это могло использоваться, чтобы относиться к таблице, но имя таблицы не
позволено в контексте, в котором это используется ниже.
-- Example schema
CREATE VIRTUAL TABLE docs USING fts4(content);
-- Example queries
SELECT * FROM docs WHERE docs MATCH 'sqlite';-- OK.
SELECT * FROM docs WHERE docs.docs MATCH 'sqlite'; -- OK.
SELECT * FROM docs WHERE main.docs.docs MATCH 'sqlite'; -- OK.
SELECT * FROM docs WHERE main.docs MATCH 'sqlite'; -- Error.
1.5. Резюме
С пользовательской точки зрения таблицы FTS подобны обычным таблицам
SQLite во многих отношениях. Данные могут быть добавлены, изменены и
удалены из таблиц FTS, используя INSERT, UPDATE и DELETE, как это может
быть с обычными таблицами. Точно так же команда SELECT может использоваться,
чтобы запросить данные. Следующий список суммирует различия между
FTS и обычными таблицами:
Как со всеми виртуальными типами таблицы, невозможно создать
индексы или триггеры к таблицам FTS. И при этом невозможно использовать
команду ALTER TABLE, чтобы добавить дополнительные столбцы к таблицам FTS
(хотя возможно использовать ALTER TABLE, чтобы
переименовать таблицу FTS). Типы данных, определенные как часть "CREATE VIRTUAL TABLE",
проигнорированы полностью. Вместо нормальных правил для применения
близости типа к вставленным
значениям, все значения, вставленные в столбцы таблицы FTS (кроме специальной
колонки rowid), преобразовываются в тип TEXT до сохранения. Таблицы FTS разрешают специальному псевдониму "docid"
использоваться, чтобы обратиться к колонке rowid, поддержанной всеми
виртуальными таблицами. Оператор FTS MATCH
поддерживается для запросов на основе
встроенного полнотекстового индекса. Вспомогательные функции FTS,
snippet(),
offsets() и
matchinfo()
доступны, чтобы поддержать полнотекстовые запросы. У каждой таблицы FTS есть
скрытый столбец с тем же самым именем, как
сам таблица. Значение, содержащееся в каждой строке для скрытого столбца,
является blob, который полезен только как левый операнд оператора
MATCH,
или как крайний левый аргумент одной из
вспомогательных функций FTS.
2. Компилирование и предоставление возможности FTS3 и FTS4
Хотя FTS3 и FTS4 включены в основной исходный код SQLite, их не включают
по умолчанию. Чтобы построить SQLite с позволенной функциональностью FTS,
определите макрос препроцессора
SQLITE_ENABLE_FTS3 при компиляции. Новые приложения должны также
определить макрос
SQLITE_ENABLE_FTS3_PARENTHESIS, чтобы позволить
расширенный синтаксис запроса (см. ниже). Обычно, это сделано, добавив
следующие два переключателя к командной строке компилятора:
-DSQLITE_ENABLE_FTS3
-DSQLITE_ENABLE_FTS3_PARENTHESIS
Обратите внимание на то, что предоставление возможности FTS3 также делает
доступным FTS4. Нет отдельного выбора времени компиляции
SQLITE_ENABLE_FTS4.
Если используется autoconf,
урегулирование переменной окружения CPPFLAGS, управляя скриптом 'configure',
является легким способом установить макрос. Например, следующая команда:
CPPFLAGS="-DSQLITE_ENABLE_FTS3 -DSQLITE_ENABLE_FTS3_PARENTHESIS" \
./configure <configure options>
где <configure options> это варианты, обычно переданные к
скрипту сборки, если таковые имеются.
Поскольку FTS3 и FTS4 это виртуальные таблицы, выбор времени компиляции
SQLITE_ENABLE_FTS3
несовместим с выбором
SQLITE_OMIT_VIRTUALTABLE.
Если SQLite не будет включать модули FTS, то любая попытка подготовить
SQL-оператор, чтобы создать, удалить или запросить таблицу FTS3 или FTS4
в любом случае потерпит неудачу. Возвращенное сообщение об ошибке будет
подобно "no such module: ftsN" (здесь N это 3 или 4).
Если версия C ICU library
доступна, то FTS может также быть собран с определенным макросом
препроцессора SQLITE_ENABLE_ICU. Компилирование с этим макросом позволяет FTS
токенизатор,
который пользуется библиотекой ICU, чтобы разделить документ на условия
(слова), используя соглашения для указанного языка и места действия.
3. Полнотекстовые запросы индекса
Самая полезная вещь в таблицах FTS это запросы, которые могут быть
выполнены, используя встроенный полнотекстовый индекс. Полнотекстовые запросы
выполняются, определяя пункт формы
"<column> MATCH <full-text query expression>" как часть WHERE в
SELECT, который читает данные из таблицы FTS.
Простые запросы FTS,
которые возвращают все документы, которые содержат данный термин, описаны
выше. В том обсуждении правый операнд оператора MATCH, как предполагалось,
был последовательностью, состоящей из единственного термина.
Эта секция описывает типы более сложного запроса, поддержанные таблицами FTS,
и как они могут быть использованы, определив выражение более сложного запроса
как правый операнд оператора MATCH.
Таблицы FTS поддерживают три основных типа запроса:
Символические или символические префиксные запросы.
Таблица FTS может быть запрошена
для всех документов, которые содержат указанный термин
(описано выше)
или для всех документов, которые содержат термин с указанным префиксом.
Как мы видели, выражение запроса для конкретного термина это
просто сам термин. Выражение запроса, используемое, чтобы искать префикс
термина, является самим префиксом с символом '*':
-- Virtual table declaration
CREATE VIRTUAL TABLE docs USING fts3(title, body);
-- Query for all documents containing the term "linux":
SELECT * FROM docs WHERE docs MATCH 'linux';
-- Query for all documents containing a term with the prefix "lin". This will match
-- all documents that contain "linux", but also those that contain terms "linear",
--"linker", "linguistic" and so on.
SELECT * FROM docs WHERE docs MATCH 'lin*';
Обычно символический запрос соответствует столбцу таблицы FTS, определенному
как левая сторона оператора MATCH. Или, если специальная колонка с тем же
самым именем, как сама таблица FTS, определяется против всех колонок.
Это может быть отвергнуто, определив имя столбца, сопровождаемое символом
":" перед запросом основного члена. Может быть пробел
между ":" и термином, чтобы запросить, но не между именем столбца и
":". Например:
-- Query the database for documents for which the term "linux" appears in
-- the document title, and the term "problems" appears in either the title
-- or body of the document.
SELECT * FROM docs WHERE docs MATCH 'title:linux problems';
-- Query the database for documents for which the term "linux" appears in
-- the document title, and the term "driver" appears in the body of the document
-- ("driver" may also appear in the title, but this alone will not satisfy the
-- query criteria).
SELECT * FROM docs WHERE body MATCH 'title:linux driver';
Если таблица FTS это таблица FTS4 (не FTS3),
символ может также быть оснащен префиксом с символом "^".
В этом случае, чтобы соответствовать, символ должен появиться как самый
первый символ в любой колонке соответствующей строки:
-- All documents for which "linux" is the first token of at
-- least one column.
SELECT * FROM docs WHERE docs MATCH '^linux';
-- All documents for which the first token in column "title" begins with "lin".
SELECT * FROM docs WHERE body MATCH 'title: ^lin*';
запросы фразы.
Это запрос, который восстанавливает все документы, которые содержат
назначенный набор условий или префиксы в указанном порядке
без прошедших символов. Запросы фразы определяются, прилагая
разделенную пробелами последовательность
условий или префиксов термина в двойных кавычках ("):
-- Query for all documents that contain the phrase "linux applications".
SELECT * FROM docs WHERE docs MATCH '"linux applications"';
-- Query for all documents that contain a phrase that matches "lin* app*". As well as
-- "linux applications", this will match common phrases such as "linoleum appliances"
-- or "link apprentice".
SELECT * FROM docs WHERE docs MATCH '"lin* app*"';
Запросы NEAR.
Запросы NEAR это запрос, который возвращает документы, которые содержат два
или больше номинируемые условия или фразы в указанной близости друг от друга
(по умолчанию с 10 или меньше прошедшими условиями).
Запрос NEAR определяется, помещая ключевое слово "NEAR" между двумя фразами
или символическими запросами. Чтобы определить близость кроме умолчания,
оператор формы "NEAR/<N>" может использоваться, где
<N> это максимальное количество позволенных условий. Например:
-- Virtual table declaration.
CREATE VIRTUAL TABLE docs USING fts4();
-- Virtual table data.
INSERT INTO docs VALUES('SQLite is an ACID compliant embedded relational database management system');
-- Search for a document that contains the terms "sqlite" and "database" with
-- not more than 10 intervening terms. This matches the only document in
-- table docs (since there are only six terms between "SQLite" and "database"
-- in the document).
SELECT * FROM docs WHERE docs MATCH 'sqlite NEAR database';
-- Search for a document that contains the terms "sqlite" and "database" with
-- not more than 6 intervening terms. This also matches the only document in
-- table docs. Note that the order in which the terms appear in the document
-- does not have to be the same as the order in which they appear in the query.
SELECT * FROM docs WHERE docs MATCH 'database NEAR/6 sqlite';
-- Search for a document that contains the terms "sqlite" and "database" with
-- not more than 5 intervening terms. This query matches no documents.
SELECT * FROM docs WHERE docs MATCH 'database NEAR/5 sqlite';
-- Search for a document that contains the phrase "ACID compliant" and the term
-- "database" with not more than 2 terms separating the two. This matches the
-- document stored in table docs.
SELECT * FROM docs WHERE docs MATCH 'database NEAR/2 "ACID compliant"';
-- Search for a document that contains the phrase "ACID compliant" and the term
-- "sqlite" with not more than 2 terms separating the two. This also matches
-- the only document stored in table docs.
SELECT * FROM docs WHERE docs MATCH '"ACID compliant" NEAR/2 sqlite';
Больше чем один оператор NEAR может появиться в едином запросе.
В этом случае каждая пара условий или фраз, отделенных оператором NEAR,
должна появиться в указанной близости друг от друга в документе.
Используя ту же самую таблицу и данные, как в блоке примеров выше:
-- The following query selects documents that contains an instance of the term
-- "sqlite" separated by two or fewer terms from an instance of the term "acid",
-- which is in turn separated by two or fewer terms from an instance of
-- the term "relational".
SELECT * FROM docs WHERE docs MATCH 'sqlite NEAR/2 acid NEAR/2 relational';
-- This query matches no documents. There is an instance of the term "sqlite" with
-- sufficient proximity to an instance of "acid" but it is not sufficiently close
-- to an instance of the term "relational".
SELECT * FROM docs WHERE docs MATCH 'acid NEAR/2 sqlite NEAR/2 relational';
Фраза и запросы NEAR могут не охватить многочисленные колонки в строке.
Три основных типа запроса, описанные выше, могут использоваться, чтобы
запросить полнотекстовый индекс для набора документов, которые соответствуют
указанным критериям. Используя язык выражения запроса FTS возможно выполнить
различные операции присвоения на результатах основных запросов.
В настоящее время есть три поддержанных операции:
- AND определяет пересечение двух наборов документов.
- OR вычисляет объединение двух наборов документов.
- NOT (или, используя стандартный синтаксис, одноместный "-")
может использоваться, чтобы вычислить относительное дополнение
одного набора документов относительно другого.
Модули FTS могут быть собраны, чтобы использовать одну из двух немного
отличающихся версий полнотекстового синтаксиса запроса: "standard"
и "enhanced". Основной член, префикс термина, фраза и запросы NEAR, описанные
выше, являются теми же самыми в обеих версиях синтаксиса.
Путь, которым определяются операции присвоения, немного отличается.
Следующие два подраздела описывают часть двух синтаксисов запроса,
которая принадлежит операциям присвоения. Обратитесь к описанию того, как
компилировать
fts.
3.1. Операции присвоения, используя
расширенный синтаксис запроса
Расширенный синтаксис запроса поддерживает двоичные операторы AND, OR и
NOT. Каждый из этих двух операндов оператору может быть основным запросом FTS
или результатом другого AND, OR или NOT.
Операторы должны быть введены, используя прописные буквы.
Иначе они интерпретируются как запросы основного члена вместо операторов.
AND может быть неявно определен. Если два основных запроса появляются без
оператора, отделяющего их в строке запроса FTS, результаты совпадают с тем,
что будет, если два основных запроса были отделены операцией AND.
Например, выражение запроса "implicit operator" является более сжатой версией
"implicit AND operator".
-- Virtual table declaration
CREATE VIRTUAL TABLE docs USING fts3();
-- Virtual table data
INSERT INTO docs(docid, content) VALUES(1, 'a database is a software system');
INSERT INTO docs(docid, content) VALUES(2, 'sqlite is a software system');
INSERT INTO docs(docid, content) VALUES(3, 'sqlite is a database');
-- Return the set of documents that contain the term "sqlite", and the
-- term "database". This query will return the document with docid 3 only.
SELECT * FROM docs WHERE docs MATCH 'sqlite AND database';
-- Again, return the set of documents that contain both "sqlite" and
-- "database". This time, use an implicit AND operator. Again, document
-- 3 is the only document matched by this query.
SELECT * FROM docs WHERE docs MATCH 'database sqlite';
-- Query for the set of documents that contains either "sqlite" or "database".
-- All three documents in the database are matched by this query.
SELECT * FROM docs WHERE docs MATCH 'sqlite OR database';
-- Query for all documents that contain the term "database", but do not contain
-- the term "sqlite". Document 1 is the only document that matches this criteria.
SELECT * FROM docs WHERE docs MATCH 'database NOT sqlite';
-- The following query matches no documents. Because "and" is in lowercase letters,
-- it is interpreted as a basic term query instead of an operator. Operators must
-- be specified using capital letters. In practice, this query will match any documents
-- that contain each of the three terms "database", "and" and "sqlite" at least once.
-- No documents in the example data above match this criteria.
SELECT * FROM docs WHERE docs MATCH 'database and sqlite';
Примеры, прежде всего, используют основные полнотекстовые запросы термина
в качестве обоих операндов продемонстрированных операций присвоения.
Фраза и запросы NEAR могут также использоваться, как могут и
результаты других операций присвоения. Когда больше, чем одна операция
присвоения присутствует в запросе FTS,
предшествование операторов следующие:
| Оператор |
Расширенное предшествование синтаксиса запроса
|
|---|
| NOT |
Наивысший приоритет.
| | AND |
| | OR |
Самый низкий приоритет. |
Используя расширенный синтаксис запроса, круглая скобка может
использоваться, чтобы отвергнуть предшествование по умолчанию
различных операторов. Например:
-- Return the docid values associated with all documents that contain the
-- two terms "sqlite" and "database", and/or contain the term "library".
SELECT docid FROM docs WHERE docs MATCH 'sqlite AND database OR library';
-- This query is equivalent to the above.
SELECT docid FROM docs WHERE docs MATCH 'sqlite AND database' UNION
SELECT docid FROM docs WHERE docs MATCH 'library';
-- Query for the set of documents that contains the term "linux", and at least
-- one of the phrases "sqlite database" and "sqlite library".
SELECT docid FROM docs WHERE docs MATCH '("sqlite database" OR
"sqlite library") AND linux';
-- This query is equivalent to the above.
SELECT docid FROM docs WHERE docs MATCH 'linux' INTERSECT
SELECT docid FROM (SELECT docid FROM docs WHERE docs MATCH '"sqlite library"'
UNION SELECT docid FROM docs WHERE docs MATCH '"sqlite database"');
3.2. Операции присвоения, используя стандартный синтаксис запроса
FTS использует операции присвоения, используя стандартный синтаксис
запроса, подобно, но не идентично, операциям присвоения с расширенным
синтаксисом запроса. Есть четыре различия:
Только неявная версия операции AND поддерживается.
Определение последовательности "AND" как части стандартного
запроса синтаксиса запроса интерпретируется как запрос термина для набора
документов, содержащих термин "and".
Круглая скобка не поддерживается.
Оператор NOT не поддерживается. Вместо NOT стандартный
синтаксис запроса поддерживает одноместный "-",
который может быть применен к основному члену и запросам префикса термина (но
не к фразе или запросам NEAR). Термин или префикс термина, у которого есть
одноместный "-", добавленный к нему, не могут появиться как операнд в
операции OR. Запрос FTS не может состоять полностью из условий или запросов
префикса термина с одноместным "-".
-- Search for the set of documents that contain the term "sqlite" but do
-- not contain the term "database".
SELECT * FROM docs WHERE docs MATCH 'sqlite -database';
Относительное предшествование операций присвоения
отличается. В частности, используя стандартный синтаксис запроса у оператора
"OR" есть более высокое предшествование, чем у "AND".
Предшествование операторов, используя
стандартный синтаксис запроса:
| Operator |
Стандартное предшествование синтаксиса запроса
|
|---|
|
Одноместный "-" | Наивысший приоритет.
| | OR |
| | AND |
Самый низкий приоритет. |
- Следующий пример иллюстрирует предшествование
операторов, использующих стандартный синтаксис запроса:
-- Search for documents that contain at least one of the terms "database"
-- and "sqlite", and also contain the term "library". Because of the differences
-- in operator precedences, this query would have a different interpretation using
-- the enhanced query syntax.
SELECT * FROM docs WHERE docs MATCH 'sqlite OR database library';
4. Вспомогательные функции Snippet, Offsets и Matchinfo
Модули FTS3 и FTS4 обеспечивают три специальных скалярных функции SQL,
которые могут быть полезны для разработчиков полнотекстовых систем запросов:
"snippet", "offsets" и "matchinfo". Цель "snippet" и "offsets"
состоит в том, чтобы позволить пользователю определять местоположение
запрошенных условий в возвращенных документах. Функция "matchinfo"
предоставляет пользователю метрики, которые могут быть полезны для фильтрации
или сортировки результатов запроса согласно уместности.
Первый аргумент всех трех специальных скалярных функций SQL должен быть
скрытым столбцом FTS таблицы FTS, что к
функции относится. Скрытый столбец FTS
это автоматически произведенная колонка во всех таблицах FTS, у которой есть
то же самое имя, как у самой таблицы FTS.
Например, таблица FTS с именем "mail":
SELECT offsets(mail) FROM mail WHERE mail MATCH <full-text query expression>;
SELECT snippet(mail) FROM mail WHERE mail MATCH <full-text query expression>;
SELECT matchinfo(mail) FROM mail WHERE mail MATCH <full-text query expression>;
Три вспомогательных функции только полезны в операторе SELECT, который
использует полнотекстовый индекс таблицы FTS. Если используется в SELECT,
который использует логику "запрос rowid" или "линейный
просмотр", то snippet и вернут пустую строку, а функция matchinfo
возвращает blob нуль байт в размере.
три вспомогательных функции извлекают набор "matchable phrases"
из выражения запроса FTS. Набор matchable фраз для данного запроса состоит из
всех фраз (включая неупомянутые символы и символические префиксы) в выражении
кроме тех, которые имеют одноместный "-" (стандартный синтаксис) или являются
частью подвыражения, которое используется в качестве правого
операнда оператора NOT.
Каждая серия символов в таблице FTS, который соответствует
одной из matchable фраз в выражении запроса, известна как "phrase match":
- Если matchable фраза это часть серии фраз, связанных операторами NEAR
в выражении запроса FTS, то каждое соответствие фразы
должно быть достаточно близко к другим соответствиям
фразы соответствующих типов, чтобы удовлетворить условие NEAR.
- Если matchable фраза в запросе FTS ограничивается соответствием данным в
указанном столбце таблицы FTS, то только соответствия
фразы, которые происходят в рамках той колонки, рассматривают.
4.1. Функция Offsets
Для запроса Select, который использует полнотекстовый индекс, функция
offsets() возвращает текстовую значение, содержащую серию разделенных
пробелом целых чисел. Для каждого термина в каждом
соответствии текущей строки в возвращенном списке есть четыре целых
числа. Каждый набор четырех целых чисел
интерпретируется следующим образом:
| Integer | Смысл |
|---|
| 0 |
Номер столбца, где экземпляр термина происходит (0 для крайнего левого
столбца таблицы FTS, 1 для следующего крайнего левого и т.д.). |
| 1 |
Номер соответствующего термина в полнотекстовом выражении запроса.
Условия в выражении запроса пронумерованы с 0 в порядке появления. |
| 2 |
Байтовое смещение соответствующего термина в рамках колонки. |
| 3 |
Размер соответствующего термина в байтах. |
Следующий блок содержит примеры, которые используют функцию offsets.
CREATE VIRTUAL TABLE mail USING fts3(subject, body);
INSERT INTO mail VALUES('hello world', 'This message is a hello world message.');
INSERT INTO mail VALUES('urgent: serious', 'This mail is seen as a more serious mail');
-- The following query returns a single row (as it matches only the first
-- entry in table "mail". The text returned by the offsets function is
-- "0 0 6 5 1 0 24 5".
--
-- The first set of four integers in the result indicate that column 0
-- contains an instance of term 0 ("world") at byte offset 6. The term instance
-- is 5 bytes in size. The second set of four integers shows that column 1
-- of the matched row contains an instance of term 0 ("world") at byte offset
-- 24. Again, the term instance is 5 bytes in size.
SELECT offsets(mail) FROM mail WHERE mail MATCH 'world';
-- The following query returns also matches only the first row in table "mail".
-- In this case the returned text is "1 0 5 7 1 0 30 7".
SELECT offsets(mail) FROM mail WHERE mail MATCH 'message';
-- The following query matches the second row in table "mail". It returns the
-- text "1 0 28 7 1 1 36 4". Only those occurrences of terms "serious" and "mail"
-- that are part of an instance of the phrase "serious mail" are identified; the
-- other occurrences of "serious" and "mail" are ignored.
SELECT offsets(mail) FROM mail WHERE mail MATCH '"serious mail"';
4.2. Функция Snippet
Функция snippet используется, чтобы создать отформатированные фрагменты
текста документа для показа как часть полнотекстового отчета о результатах
запроса. Функции может быть передано от одного до шести
аргументов, следующим образом:
| Аргумент | Значение по умолчанию |
Описание |
|---|
| 0 | N/A |
Первый аргумент функции snippet должен всегда быть
скрытым столбцом FTS таблицы FTS,
из которой должен быть взят отрывок. |
| 1 | "<b>" |
Начальное соответствие текста. |
| 2 |
"</b>" | Конечное соответствие текста. |
| 3 | "<b>...</b>" |
Текст "ellipses". |
| 4 | -1 |
Номер столбца таблицы FTS, чтобы извлечь возвращенные фрагменты текста.
Колонки пронумерованы от левой (номер 0) до крайней правой.
Отрицательная величина указывает, что текст может быть извлечен
из любой колонки. |
| 5 | -15 |
Абсолютное значение этого целочисленного аргумента используется в
качестве (приблизительного) количества символов, чтобы включать в
возвращенное текстовое значение. Максимальное допустимое абсолютное значение
равняется 64. Значение этого аргумента упоминается
как N в обсуждении ниже. |
Функция snippet сначала пытается найти фрагмент текста, состоящий из
|N| символов в текущей строке, который содержит по крайней мере одно
соответствие фразы для каждой matchable фразы, подобранной где-нибудь в
текущей строке, где |N| это абсолютное значение шестого аргумента,
переданное функции snippet. Если текст, сохраненный в отдельном столбце,
содержит меньше, чем |N| символов,
то все значение столбца рассматривают. Текстовые фрагменты могут
не охватить многочисленные колонки.
Если такой текстовый фрагмент может быть найден, он возвращен
со следующими модификациями:
- Если текстовый фрагмент не начинается в начале значения
столбца, текст "ellipses" добавлен перед ним.
- Если текстовый фрагмент не заканчивается в конце значения столбца, текст
"ellipses" добавлен после него.
- Для каждого символа в текстовом фрагменте, который является частью
соответствия фразы, текст начального соответствия
вставляется во фрагмент перед символом, а текст конечного соответствия
немедленно вставляется после него.
Если больше, чем один такой фрагмент может быть найден, то фрагменты,
которые содержат большее число "дополнительных" соответствий
фразы, одобрены. Начало отобранного текстового фрагмента может быть
продвинуто на несколько символов вперед или назад, чтобы попытаться
сконцентрировать соответствие фразы к центру фрагмента.
Допустим, N является положительным значением, если никакие
фрагменты не могут быть найдены, которые содержат соответствие
фразы, соответствующее каждой matchable фразе, функция snippet
пытается найти два фрагмента приблизительно по N/2 символов, которые
между ними содержат по крайней мере одно соответствие
фразы для каждой matchable фразы, соответствующей текущей строке.
Если это терпит неудачу, попытки предприняты, чтобы найти три фрагмента
по N/3 символов каждый и наконец четыре фрагмента по N/4
символа. Если ряд четырех фрагментов не может быть найден,
который охватывает необходимые соответствия фразы, четыре фрагмента по
N/4 символов, которые подходят лучше всего, выбраны.
Если N это отрицательная величина, и никакой единственный
фрагмент, содержащий необходимые соответствия фразы, не может быть найден,
функция snippet ищет два фрагмента по |N|
символы каждый, затем три, затем четыре. Другими словами, если указанное
значение N отрицательна, размеры фрагментов не уменьшены, если больше,
чем один фрагмент требуется, чтобы предоставлять соответствие фразы.
После того, как M фрагментов были найдены,
где M между 2 и 4, как описано в параграфах выше, они объединены в
сортированном порядке с текстом "ellipses", отделяющим их.
Перечисленные выше три модификации выполняются на тексте, прежде чем
он будет возвращен.
Note: In this block of examples, newlines and whitespace characters have
been inserted into the document inserted into the FTS table, and the expected
results described in SQL comments. This is done to enhance readability only,
they would not be present in actual SQLite commands or output.
-- Create and populate an FTS table.
CREATE VIRTUAL TABLE text USING fts4();
INSERT INTO text VALUES('
During 30 Nov-1 Dec, 2-3oC drops. Cool in the upper portion, minimum temperature 14-16oC
and cool elsewhere, minimum temperature 17-20oC. Cold to very cold on mountaintops,
minimum temperature 6-12oC. Northeasterly winds 15-30 km/hr. After that, temperature
increases. Northeasterly winds 15-30 km/hr.
');
-- The following query returns the text value:
--
-- "<b>...</b>cool elsewhere, minimum temperature 17-20oC. <b>Cold</b> to very
-- <b>cold</b> on mountaintops, minimum temperature 6<b>...</b>".
--
SELECT snippet(text) FROM text WHERE text MATCH 'cold';
-- The following query returns the text value:
--
-- "...the upper portion, [minimum] [temperature] 14-16oC and cool elsewhere,
-- [minimum] [temperature] 17-20oC. Cold..."
--
SELECT snippet(text, '[', ']', '...') FROM text WHERE text MATCH '"min* tem*"'
4.3. Функция Matchinfo
Функция matchinfo возвращает blob.
Если это используется в запросе, который не использует полнотекстовый индекс
("query by rowid" или "linear scan"), blob в длину 0 байт.
Иначе blob состоит из ноля или большего количества 32-битных целых без знака
в машинном порядке байтов. Точное количество целых чисел в возвращенном
массиве зависит от запроса и от значения второго аргумента (если
есть), функции matchinfo.
Функция matchinfo вызвана с одним или двумя аргументами. Что касается всех
вспомогательных функций, первый аргумент должен быть специальным
скрытым столбцом FTS.
Вторым аргументом, если это определяется, должно быть текстовое значение,
состоящее только из знаков 'p', 'c', 'n', 'a', 'l', 's', 'x', 'y' и 'b'.
Если никакой второй аргумент явно не поставляется, это по умолчанию "pcx".
Второй аргумент упоминается как "строка формата" ниже.
Знаки в matchinfo строке формата обрабатываются слева направо.
Каждый символ в строке формата заставляет одно или более 32-битных значений
целого без знака быть добавленными к возвращенному массиву.
Колонка "values" в следующей таблице содержит количество целочисленных
значений, приложенных к буферу вывода для каждого символа строки
поддерживаемого формата. В данной формуле cols это
количество колонок в таблице FTS, и phrases это
количество соответствующих фраз в запросе.
| Символ | Значения | Описание
|
|---|
| p |
1 | Количество соответствующих фраз в запросе. |
| c | 1 |
Число определенных пользователем колонок в таблице FTS (то есть, не
включая docid или скрытые столбцы FTS).
| | x |
3 * cols * phrases |
Для каждой отличной комбинации фразы и столбца
таблицы, следующих трех значений:
- В текущей строке число раз, которое фраза появляется в колонке.
- Общее количество раз, которое фраза появляется в колонке во всех
строках в таблице FTS.
- Общее количество строк в таблице FTS, для которого колонка содержит по
крайней мере один экземпляр фразы.
Первый набор трех значений соответствует крайнему левому столбцу таблицы
(колонка 0) и крайней леврой соответствующей фразе в запросе (фраза 0).
Если у таблицы есть больше, чем одна колонка, второй набор трех значений в
выходном массиве соответствуют фразе 0 и колонке 1. Далее фраза 0, колонка 2
и так далее для всех колонок таблицы. Далее так же для фразы 1, колонка 0,
затем фраза 1, колонка 1 и т.д. Другими словами, данные для экземпляров фразы
p в столбце c могут быть найдены, используя следующую формулу:
hits_this_row = array[3 * (c + p*cols) + 0]
hits_all_rows = array[3 * (c + p*cols) + 1]
docs_with_hits = array[3 * (c + p*cols) + 2]
|
| y |
cols * phrases |
Для каждой отличной комбинации фразы и столбца таблицы, количество применимых
совпадений фразы, которые появляются в колонке. Это обычно идентично первому
значению в каждом наборе, возвращенном
matchinfo 'x' flag.
Однако, количество хитов, о которых сообщает флаг 'y', является нолем для
любой фразы, которая является частью подвыражения, которое не соответствует
текущей строке. Это имеет значение для выражений, которые содержат операции
AND, которые являются потомками операций OR. Например, рассмотрите выражение:
a OR (b AND c)
и документ:
"a c d"
matchinfo 'x' flag
сообщил бы о единственном хите для фраз "a" и "c".
Однако, 'y' сообщает о количестве хитов для "c" = 0,
поскольку это часть подвыражения, которое не соответствует документу,
(b AND c). Для запросов, которые не содержат операции AND,
произошедшие от операций OR, значения результата, возвращенные 'y', всегда
являются теми же самыми, как возвращено 'x'.
Первое значение во множестве целочисленных значений соответствует крайнему
левому столбцу таблицы (колонка 0) и первой фразе в запросе (фраза 0).
Значения, соответствующие другим комбинациям колонки/фразы, могут быть
найдены, используя следующую формулу:
hits_for_phrase_p_column_c = array[c + p*cols]
Для запросов, которые используют выражения OR, или те, которые используют
LIMIT или возвращают много строк, опция 'y' matchinfo
модет быть быстрее, чем 'x'. |
| b |
((cols+31)/32) * phrases |
matchinfo 'b' флаг предоставляет подобную информацию
matchinfo 'y' flag,
но в более компактной форме. Вместо точного количества хитов 'b' обеспечивает
единственный булев флаг для каждой комбинации фразы/колонки. Если фраза
присутствует в колонке, по крайней мере, однажды (то есть, если бы
соответствующий вывод 'y' не 0), соответствующий флаг установлен.
Иначе он очищен.
Если у таблицы есть 32 или меньше колонок, единственное целое без знака
произведено для каждой фразы в запросе.
Младший значащий бит целого числа установлен, если фраза появляется, по
крайней мере, однажды в колонке 0. Второй младший значащий бит установлен,
если фраза появляется однажды или больше в колонке 1. И так далее.
Если у таблицы есть больше, чем 32 колонки, дополнительное целое число
добавляется к выводу каждой фразы для каждых дополнительных 32 колонок
или части этого. Целые числа, соответствующие той же самой фразе, собраны в
группу вместе. Например, если таблица с 45 колонками запрашивается
для двух фраз, 4 целых числа произведены. Первое соответствует фразе 0 и
колонкам 0-31 таблицы. Второе целое число содержит данные для фразы 0 и
колонок 32-44 и так далее.
Например, если nCol это количество колонок в таблице, чтобы определить,
присутствует ли фраза p в колонке c:
p_is_in_c = array[p * ((nCol+31)/32)] & (1 << (c % 32))
|
| n | 1 | Количество строк в
таблице FTS4. Это значение доступно только запрашивая таблицы FTS4,
но не FTS3. |
| a |
cols | Для каждой колонки среднее количество символов в
текстовых значениях, сохраненных в колонке (рассматривая все строки в таблице
FTS4). Это значение доступно только запрашивая
таблицы FTS4, не FTS3. |
| l | cols |
Для каждой колонки длина значения в текущей строке таблицы FTS4, в символах.
Это значение доступно только запрашивая таблицы FTS4, не FTS3,
только если "matchinfo=fts3" не была определена как часть
"CREATE VIRTUAL TABLE". |
| s |
cols | Для каждой колонки длина самой длинной
подпоследовательности соответствующей фразы, которую значение столбца имеет
вместе с текстом запроса. Например, если столбец таблицы содержит текст
'a b c d e' и запрос 'a c "d e"', тогда длина самой длинной общей
подпоследовательности равняется 2 (фраза "c", сопровождаемая фразой "d e").
|
Например:
-- Create and populate an FTS4 table with two columns:
CREATE VIRTUAL TABLE t1 USING fts4(a, b);
INSERT INTO t1 VALUES('transaction default models default', 'Non transaction reads');
INSERT INTO t1 VALUES('the default transaction', 'these semantics present');
INSERT INTO t1 VALUES('single request', 'default data');
-- In the following query, no format string is specified and so it defaults
-- to "pcx". It therefore returns a single row consisting of a single blob
-- value 80 bytes in size (20 32-bit integers - 1 for "p", 1 for "c" and
-- 3*2*3 for "x"). If each block of 4 bytes in the blob is interpreted
-- as an unsigned integer in machine byte-order, the values will be:
--
-- 3 2 1 3 2 0 1 1 1 2 2 0 1 1 0 0 0 1 1 1
--
-- The row returned corresponds to the second entry inserted into table t1.
-- The first two integers in the blob show that the query contained three
-- phrases and the table being queried has two columns. The next block of
-- three integers describes column 0 (in this case column "a") and phrase
-- 0 (in this case "default"). The current row contains 1 hit for "default"
-- in column 0, of a total of 3 hits for "default" that occur in column
-- 0 of any table row. The 3 hits are spread across 2 different rows.
--
-- The next set of three integers (0 1 1) pertain to the hits for "default"
-- in column 1 of the table (0 in this row, 1 in all rows, spread across
-- 1 rows).
--
SELECT matchinfo(t1) FROM t1 WHERE t1 MATCH 'default transaction "these semantics"';
-- The format string for this query is "ns". The output array will therefore
-- contain 3 integer values - 1 for "n" and 2 for "s". The query returns
-- two rows (the first two rows in the table match). The values returned are:
--
-- 3 1 1
-- 3 2 0
--
-- The first value in the matchinfo array returned for both rows is 3 (the
-- number of rows in the table). The following two values are the lengths
-- of the longest common subsequence of phrase matches in each column.
SELECT matchinfo(t1, 'ns') FROM t1 WHERE t1 MATCH 'default transaction';
Функция matchinfo намного быстрее, чем snippet или offsets.
Это вызвано тем, что внедрение snippet и offsets
требует получения проанализированных документов с диска, тогда как все
данные, требуемые matchinfo, доступны как часть тех же самых частей
полнотекстового индекса, которые требуются, чтобы осуществлять сам
полнотекстовый запрос. Это означает что из следующих двух запросов, первый
может быть на порядок быстрее, чем второй:
SELECT docid, matchinfo(tbl) FROM tbl WHERE tbl MATCH <query expression>;
SELECT docid, offsets(tbl) FROM tbl WHERE tbl MATCH <query expression>;
Функция matchinfo предоставляет всю информацию, запрошенную, чтобы
вычислить вероятностные очки уместности "bag-of-words", такие как
Okapi BM25/BM25F,
которые могут использоваться, чтобы упорядочить результаты в полнотекстовом
поисковом приложении. Приложение A этого документа
содержит пример
использования функции matchinfo() эффективно.
5. Fts4aux прямой доступ к полнотекстовому индексу
С version 3.7.6 (2011-04-12)
SQLite включает новый виртуальный модуль таблицы, названный "fts4aux",
который может использоваться, чтобы просмотреть полнотекстовый индекс
существующей таблицы FTS непосредственно. Несмотря на его имя, fts4aux
работает точно также с таблицами FTS3, как с таблицами FTS4.
Таблицы Fts4aux только для чтения. Единственный способ изменить содержание
таблицы fts4aux, это изменить содержание связанной таблицы FTS.
Модуль fts4aux автоматически включен во все сборки,
которые включают FTS.
Виртуальная таблица fts4aux построена с одним или двумя аргументами.
Когда используется с отдельным аргументом, тот аргумент задает
неквалифицированное название таблицы FTS для доступа.
Чтобы получить доступ к таблице в иной базе данных (например, создать таблицу
TEMP fts4aux, который получит доступ к таблице FTS3 в базе данных MAIN)
используют форму с двумя аргументами и дают название целевой базы данных
(например: "main") в первом аргументе и название таблицы FTS3/4 как второй
аргумент. Форма с двумя аргументами fts4aux была добавлена в SQLite
version 3.7.17 (2013-05-20)
и бросит ошибку в предшествующих выпусках. Например:
-- Create an FTS4 table
CREATE VIRTUAL TABLE ft USING fts4(x, y);
-- Create an fts4aux table to access the full-text index for table "ft"
CREATE VIRTUAL TABLE ft_terms USING fts4aux(ft);
-- Create a TEMP fts4aux table accessing the "ft" table in "main"
CREATE VIRTUAL TABLE temp.ft_terms_2 USING fts4aux(main,ft);
Для каждого термина, существующего в таблице FTS, есть от 2 до N+1 строк
в таблице fts4aux, где N это количество определенных пользователями колонок в
связанной таблице FTS. У таблицы fts4aux всегда есть те же самые четыре
колонки, следующим образом, слева направо:
| Колонка | Содержание |
|---|
| term |
Содержит текст термина для этой строки. |
| col |
Эта колонка может содержать любое текстовое значение '*' (то есть
отдельный символ U+002a) или integer от 0 до N-1, где N это
количество определенных пользователями колонок в
соответствующей таблице FTS. |
| documents |
Эта колонка всегда содержит целочисленное значение, больше, чем ноль.
Если колонка "col" содержит значение '*', то эта колонка содержит количество
строк таблицы FTS, которые содержат по крайней мере один экземпляр термина (в
любой колонке). Если col содержит integer, то эта колонка содержит количество
строк таблицы FTS, которые содержат по крайней мере один экземпляр
термина в колонке, определенной значением col. Как обычно, колонки таблицы
FTS пронумерованы слева направо, начиная с 0. |
| occurrences |
Эта колонка также всегда содержит целочисленное значение, больше, чем ноль.
Если колонка "col" содержит значение '*',
то эта колонка содержит общее количество экземпляров
термина во всех строках таблицы FTS (в любой колонке). Иначе, если col
содержит integer, то эта колонка содержит общее количество экземпляров
термина, которые появляются в столбце таблицы FTS,
определенном значением col. |
|
languageid (скрытый) |
Эта колонка определяет, какой
languageid используется, чтобы извлечь словарь из таблицы FTS3/4.
По умолчанию languageid = 0. Если альтернативный язык определяется в
ограничениях оператора Where, то та альтернатива используется вместо 0.
Может только быть единственный languageid на запрос.
Другими словами, оператор Where не может содержать ограничение
диапазона или оператор IN на languageid. |
Например, используя таблицы, составленные выше:
INSERT INTO ft(x, y) VALUES('Apple banana', 'Cherry');
INSERT INTO ft(x, y) VALUES('Banana Date Date', 'cherry');
INSERT INTO ft(x, y) VALUES('Cherry Elderberry', 'Elderberry');
-- The following query returns this data:
--
-- apple| * | 1 | 1
-- apple| 0 | 1 | 1
-- banana | * | 2 | 2
-- banana | 0 | 2 | 2
-- cherry | * | 3 | 3
-- cherry | 0 | 1 | 1
-- cherry | 1 | 2 | 2
-- date | * | 1 | 2
-- date | 0 | 1 | 2
-- elderberry | * | 1 | 2
-- elderberry | 0 | 1 | 1
-- elderberry | 1 | 1 | 1
--
SELECT term, col, documents, occurrences FROM ft_terms;
В этом примере значения в "term" все
в нижнем регистре даже при том, что они были вставлены в таблиц "ft"
в смешанном регистре. Это вызвано тем, что таблица fts4aux содержит термины,
как они извлечены из текста документа
токенизатором. В этом случае начиная с таблицы "ft" использует
простой токенизатор,
это означает, что все термины были свернуты к нижнему регистру.
Кроме того, нет (например), никакой строки с "term", установленным в
"apple", и "col" = 1. Пока нет никаких случаев термина "apple" в столбце 1,
никакая строка не присутствует в таблице fts4aux.
Во время транзакции некоторые данные, написанные в таблицу FTS, могут
кэшироваться в памяти и будут записаны в базу данных только, когда
транзакция передается. Однако, внедрение модуля fts4aux в состоянии прочитать
данные только из базы данных. На практике это означает, что если таблица
fts4aux запрашивается из транзакции, в которой была изменена связанная
таблица FTS, результаты запроса, вероятно, будут отражать
только (возможно пустое) подмножество внесенных изменений.
6. Опции FTS4
Если "CREATE VIRTUAL TABLE" определяет модуль FTS4 (не FTS3), то
специальные директивы, опции FTS4, подобные "tokenize=*",
могут также появиться вместо имен столбцов. Выбор FTS4 состоит из имени
выбора, сопровождаемого "=" и значением. Значение выбора может произвольно
быть указано в одинарных или двойных кавычках с вложенными символами кавычки,
которые экранируют таким же образом что касается литералов SQL.
Может не быть пробелов по обе стороны от "=".
Например, чтобы составить таблицу FTS4 со значением
опции "matchinfo" = "fts3":
-- Create a reduced-footprint FTS4 table.
CREATE VIRTUAL TABLE papers USING fts4(author, document, matchinfo=fts3);
FTS4 в настоящее время поддерживает следующие опции:
| Опция | Значение |
|---|
| compress |
Выбор compress используется, чтобы определить функцию сжатия.
Ошибка определить функцию compress, также не определяя функцию uncompress.
| | content |
Содержание позволяет текст, внесенный в указатель, чтобы быть сохраненным в
отдельной таблице, отличной от таблицы FTS4, или даже за пределами SQLite.
|
| languageid | Опция languageid заставляет таблицу FTS4
использовать дополнительную скрытую колонку целого числа, которая
определяет язык текста, содержавшегося в каждой строке.
Использование languageid позволяет той же самой таблице FTS4 вмещать текст на
нескольких языках или сценарии, каждый с различными правилами токенизатора, и
запрашивать каждый язык независимо от других. |
| matchinfo |
Когда установлено в значение "fts3", matchinfo уменьшает объем
информации, хранимой FTS4, но опция "l" в
matchinfo() больше не доступна. |
| notindexed |
Этот выбор используется, чтобы определить название колонки, для которой не
внесены в указатель данные. Значения, сохраненные в колонках, которые не
внесены в указатель, не соответствуют запросам MATCH. И при этом они не
признаны вспомогательными функциями. CREATE VIRTUAL TABLE
может иметь любое количество параметров notindexed. |
| order |
Опция "order" может быть установлена в "DESC" или "ASC" (в любом регистре).
Если это установлено в "DESC", FTS4 хранит свои данные так, чтобы
оптимизировать результаты возвращения в порядке убывания docid.
Если это установлено в "ASC" (по умолчанию),
то структуры данных оптимизированы для возвращения результатов в порядке
возрастания docid. Другими словами, если многие запросы, которыми управляют
для таблицы FTS4, используют "ORDER BY docid DESC",
тогда чтобы улучшить работу, возможно стоит добавить "order=desc" в
CREATE VIRTUAL TABLE. |
| prefix |
Этот выбор может быть установлен в список разделенных запятой значений
положительных целых чисел отличных от нуля.
Для каждого целого числа N в списке, отдельный индекс создается в файле базы
данных, чтобы оптимизировать префикс запроса
, где термин запроса имеет N байт в длину, не включая символ '*',
когда закодировано, используя UTF-8. |
| uncompress |
Этот выбор используется, чтобы определить функцию распаковки.
Ошибка определить эту функцию, но не задать функцию compress.
|
При использовании FTS4, определение имени столбца, которое содержит
символ "=" и не является "tokenize=*" или опцией FTS4, выдает ошибку.
С FTS3 первый символ в непризнанной директиве интерпретируется как имя
столбца. Точно так же определение, многократных "tokenize=*"
в единственной декларации таблицы, это ошибка, используя FTS4, тогда как
вторая и последующие "tokenize=*"
интерпретируются как имена столбцов FTS3. Например:
-- An error. FTS4 does not recognize the directive "xyz=abc".
CREATE VIRTUAL TABLE papers USING fts4(author, document, xyz=abc);
-- Create an FTS3 table with three columns - "author", "document"
-- and "xyz".
CREATE VIRTUAL TABLE papers USING fts3(author, document, xyz=abc);
-- An error. FTS4 does not allow multiple tokenize=* directives
CREATE VIRTUAL TABLE papers USING fts4(tokenize=porter, tokenize=simple);
-- Create an FTS3 table with a single column named "tokenize". The
-- table uses the "porter" tokenizer.
CREATE VIRTUAL TABLE papers USING fts3(tokenize=porter, tokenize=simple);
-- An error. Cannot create a table with two columns named "tokenize".
CREATE VIRTUAL TABLE papers USING fts3(tokenize=porter, tokenize=simple, tokenize=icu);
6.1. Опции compress= и uncompress=
Опции compress и uncompress позволяют содержанию FTS4 быть сохраненным в
базе данных в сжатой форме. Оба варианта должны быть установлены в название
скалярной функции SQL, зарегистрированной, используя
sqlite3_create_function(), которая
принимает отдельный аргумент.
Функция compress должна возвратить сжатую версию значения,
переданногокак аргумент. Каждый раз, когда данные написаны в таблицу FTS4,
каждое значение столбца передается функции compress,
значение результата сохранено в базе данных. Функция compress может
возвратить любой тип значения в SQLite (blob, text, real,
integer или null).
Функция uncompress должна распаковать данные, ранее сжатые функцией
compress. Другими словами, для всех значений SQLite X, должно быть верно, что
uncompress(compress(X)) = X. Когда данные, которые были сжаты функцией
compress, прочитаны из базы данных FTS4, это передается функции uncompress
прежде чем это будет использоваться.
Если указанная функция не существует, таблица может все еще быть
составлена. Ошибка не возвращена, пока таблица FTS4 не прочитана (если
функция uncompress не существует) или записана (если
функция compress не существует).
-- Create an FTS4 table that stores data in compressed form. This
-- assumes that the scalar functions zip() and unzip() have been (or
-- will be) added to the database handle.
CREATE VIRTUAL TABLE papers USING fts4(author, document, compress=zip, uncompress=unzip);
При реализации функций compress и uncompress
важно обратить внимание на типы данных. Определенно, когда пользователь
читает значение от сжатой таблицы FTS, значение, возвращенное FTS, является
точно тем же самым, как значение, возвращенное функцией uncompress,
включая тип данных. Если тот тип данных не тот же самый, как тип данных
исходного значения, как передано функции compress (например, если функция
uncompress возвращает BLOB, когда compress первоначально передан TEXT),
то пользовательские запросы могут не функционировать как ожидалось.
6.2. Опция content=
Опция content позволяет FTS4 хранение внесенного в указатель текста.
Выбор содержания может использоваться двумя способами:
Индексируемые документы не хранятся в базе данных SQLite
вообще (таблица "contentless" FTS4) Индексируемые документы хранятся в таблице базы данных,
созданной и управляемой пользователем (таблица "внешнего содержания" FTS4).
Поскольку сами индексируемые документы обычно намного больше, чем
полнотекстовый индекс, выбор содержания может использоваться, чтобы
достигнуть значительной экономии места.
6.2.1. Таблицы Contentless FTS4
Чтобы составить таблицу FTS4, которая не хранит копию индексируемых
документов вообще, выбор содержания должен быть установлен в пустую строку.
Например, следующий SQL составляет такую таблицу FTS4 с тремя колонками:
"a", "b" и "c":
CREATE VIRTUAL TABLE t1 USING fts4(content="", a, b, c);
Данные могут быть вставлены в такую таблицу FTS4, используя операторы
INSERT. Однако, в отличие от обычных таблиц FTS4, пользователь должен
поставлять явное целое число значения docid. Например:
-- This statement is Ok:
INSERT INTO t1(docid, a, b, c) VALUES(1, 'a b c', 'd e f', 'g h i');
-- This statement causes an error, as no docid value has been provided:
INSERT INTO t1(a, b, c) VALUES('j k l', 'm n o', 'p q r');
Невозможно UPDATE или DELETE строку, сохраненную в таблице contentless
FTS4. Попытка сделать так является ошибкой.
Таблицы Contentless FTS4 также поддерживают операторы SELECT.
Однако, ошибка попытаться восстановить значение
любого столбца таблицы кроме колонки docid.
Вспомогательная функция matchinfo() может использоваться, но
snippet() и offsets() не могут:
-- The following statements are Ok:
SELECT docid FROM t1 WHERE t1 MATCH 'xxx';
SELECT docid FROM t1 WHERE a MATCH 'xxx';
SELECT matchinfo(t1) FROM t1 WHERE t1 MATCH 'xxx';
-- The following statements all cause errors, as the value of columns
-- other than docid are required to evaluate them.
SELECT * FROM t1;
SELECT a, b FROM t1 WHERE t1 MATCH 'xxx';
SELECT docid FROM t1 WHERE a LIKE 'xxx%';
SELECT snippet(t1) FROM t1 WHERE t1 MATCH 'xxx';
Ошибки, связанные с попыткой восстановить значения столбцов кроме docid,
являются ошибками периода выполнения, которые происходят в sqlite3_step().
В некоторых случаях, например, если выражение MATCH в SELECT
соответствует нулю строк, может не быть никакой ошибки вообще, даже если
запрос действительно относится к значениям столбцов кроме docid.
6.2.2. Таблицы внешнего содержания FTS4
Таблицы внешнего содержания FTS4 похожи на таблицы contentless,
за исключением того, что, если оценка запроса требует значения колонки кроме
docid, FTS4 пытается восстановить то
значение от таблицы (представления или виртуальной таблицы), назначенной
пользователем (в дальнейшем именуемой "таблица содержания").
Модуль FTS4 никогда не пишет таблицу содержания, и
запись таблицы содержания не затрагивает полнотекстовый индекс.
Обязанность пользователя гарантировать, что таблица содержания и
полнотекстовый индекс последовательны.
Внешняя таблица FTS4 содержания составлена, установив опцию content в
название таблицы (представления или виртуальной таблицы), которая может быть
запрошена FTS4, чтобы восстановить значения столбцов при необходимости.
Если назначенная таблица не существует, то внешняя таблица содержания ведет
себя таким же образом, как таблица contentless:
CREATE TABLE t2(id INTEGER PRIMARY KEY, a, b, c);
CREATE VIRTUAL TABLE t3 USING fts4(content="t2", a, c);
Предположим, что назначенная таблица действительно существует,
тогда ее колонки должны совпасть или быть супернабором определенных для
таблицы FTS. Внешняя таблица должна также быть в том же самом файле базы
данных, как таблица FTS. Другими словами, внешняя таблица не может быть в
другом файле базы данных, связанном, используя
ATTACH, при этом ни одна из FTS не может
составить таблицы и внешнее содержание быть в базе данных TEMP, когда другая
находится в постоянном файле базы данных, таком как MAIN.
Когда пользовательский запрос на таблице FTS требует значения столбца
кроме docid, FTS пытается прочитать требуемое значение из соответствующей
колонки строки в таблице содержания со значением rowid, равной текущему
FTS docid. Только подмножество столбцов таблицы контента,
дублированных в декларации таблицы FTS3/4, может быть
запрошено, чтобы восстановить значения из любых других колонок, таблица
содержания должна быть запрошена непосредственно. Или, если такая строка
не может быть найдена в таблице содержания, NULL
используется вместо этого. Например:
CREATE TABLE t2(id INTEGER PRIMARY KEY, a, b, c);
CREATE VIRTUAL TABLE t3 USING fts4(content="t2", b, c);
INSERT INTO t2 VALUES(2, 'a b', 'c d', 'e f');
INSERT INTO t2 VALUES(3, 'g h', 'i j', 'k l');
INSERT INTO t3(docid, b, c) SELECT id, b, c FROM t2;
-- The following query returns a single row with two columns containing
-- the text values "i j" and "k l".
--
-- The query uses the full-text index to discover that the MATCH
-- term matches the row with docid=3. It then retrieves the values
-- of columns b and c from the row with rowid=3 in the content table
-- to return.
--
SELECT * FROM t3 WHERE t3 MATCH 'k';
-- Following the UPDATE, the query still returns a single row, this
-- time containing the text values "xxx" and "yyy". This is because the
-- full-text index still indicates that the row with docid=3 matches
-- the FTS4 query 'k', even though the documents stored in the content
-- table have been modified.
--
UPDATE t2 SET b = 'xxx', c = 'yyy' WHERE rowid = 3;
SELECT * FROM t3 WHERE t3 MATCH 'k';
-- Following the DELETE below, the query returns one row containing two
-- NULL values. NULL values are returned because FTS is unable to find
-- a row with rowid=3 within the content table.
--
DELETE FROM t2;
SELECT * FROM t3 WHERE t3 MATCH 'k';
Когда строка удалена из внешнего содержания таблицы FTS4, FTS4 должен
получить значения столбцов строки, удаляемой из таблицы содержания.
Это чтобы FTS4 мог обновить полнотекстовые элементы индекса для каждого
символа, который происходит в удаленной строке, чтобы указать, что строка
была удалена. Если строка таблицы содержания не может быть найдена, или если
она содержит значения, несовместимые с содержанием индекса FTS, результаты
может быть трудно предсказать. Индекс FTS можно оставить содержащим записи,
соответствующие удаленной строке,
что может привести к с виду бессмысленным результатам, возвращаемым
последующими запросами SELECT. То же самое применяется, когда строка
обновляется, так как внутренний UPDATE действует как DELETE + INSERT.
Это означает, что, чтобы держать FTS в синхронизации с внешней таблицей
содержания, любой UPDATE или DELETE должны быть применены сначала к таблице
FTS, а уж затем к внешней таблице содержания. Например:
CREATE TABLE t1_real(id INTEGER PRIMARY KEY, a, b, c, d);
CREATE VIRTUAL TABLE t1_fts USING fts4(content="t1_real", b, c);
-- This works. When the row is removed from the FTS table, FTS retrieves
-- the row with rowid=123 and tokenizes it in order to determine the entries
-- that must be removed from the full-text index.
--
DELETE FROM t1_fts WHERE rowid = 123;
DELETE FROM t1_real WHERE rowid = 123;
-- This does not work. By the time the FTS table is updated, the row
-- has already been deleted from the underlying content table. As a result
-- FTS is unable to determine the entries to remove from the FTS index and
-- so the index and content table are left out of sync.
--
DELETE FROM t1_real WHERE rowid = 123;
DELETE FROM t1_fts WHERE rowid = 123;
Вместо того, чтобы писать отдельно полнотекстовый
индекс и таблицу содержания, некоторые пользователи могут хотеть использовать
триггеры базы данных, чтобы обновить полнотекстовый индекс относительно
набора документов в таблице содержания. Например, используя таблицы от
более ранних примеров:
CREATE TRIGGER t2_bu BEFORE UPDATE ON t2 BEGIN
DELETE FROM t3 WHERE docid=old.rowid;
END;
CREATE TRIGGER t2_bd BEFORE DELETE ON t2 BEGIN
DELETE FROM t3 WHERE docid=old.rowid;
END;
CREATE TRIGGER t2_au AFTER UPDATE ON t2 BEGIN
INSERT INTO t3(docid, b, c) VALUES(new.rowid, new.b, new.c);
END;
CREATE TRIGGER t2_ai AFTER INSERT ON t2 BEGIN
INSERT INTO t3(docid, b, c) VALUES(new.rowid, new.b, new.c);
END;
Триггер DELETE должен быть запущен, прежде чем фактическое
удаление происходит на таблице содержания. Это чтобы FTS4 мог все еще
восстановить исходные значения, чтобы обновить полнотекстовый индекс.
Триггер INSERT должен быть запущен после того, как новая строка вставляется,
чтобы обращаться со случаем, где rowid назначен автоматически в системе.
Триггер UPDATE должен быть разделен на две части, одна запущена прежде и одна
после обновления таблицы содержания, по тем же самым причинам.
Команда FTS4 "rebuild"
удаляет весь полнотекстовый индекс и восстанавливает его на основе текущего
набора документов в таблице содержания. Предполагая снова, что "t3" это имя
внешнего содержания таблица FTS4, команда rebuild похожа на это:
INSERT INTO t3(t3) VALUES('rebuild');
Эта команда может также использоваться с обычными таблицами FTS4,
например, если внедрение токенизатора изменяется.
Ошибка попытаться восстановить полнотекстовый индекс, сохраняемый таблицей
contentless FTS4, так как никакое содержание не будет доступно,
чтобы сделать восстановление.
6.3. Опция languageid=
Когда опция languageid присутствует, она определяет название другого
скрытого столбца,
который добавляется к таблице FTS4 и используется, чтобы определить язык,
сохраненный в каждой строке таблицы FTS4. Название скрытого столбца
languageid должно быть отлично от всех других имен столбцов в
таблице FTS4. Пример:
CREATE VIRTUAL TABLE t1 USING fts4(x, y, languageid="lid")
Значение по умолчанию languageid колонки 0. Любое значение, вставленное в
languageid преобразовывается в 32-bit (не 64) signed integer.
По умолчанию запросы FTS (те, которые используют оператор MATCH)
рассматривают только строки с languageid = 0. Чтобы запросить для строк с
другими значениями languageid, нужно добавить ограничение формы
" = " к оператору Where запросов. Например:
SELECT * FROM t1 WHERE t1 MATCH 'abc' AND lid=5;
Для единственного запроса FTS невозможно возвратить строки с различными
значениями languageid. Результаты добавления операторов Where, которые
используют другие операторы (например, lid!=5 или
lid<=5) не определены.
Если выбор содержания используется вместе с languageid,
то названная languageid колонка должна существовать в таблице content=
(подвергается обычным правилам: если запрос никогда не должен читать таблицу
содержания, тогда это ограничение не применяется).
Когда languageid используется, SQLite вызывает xLanguageid() на объекте
sqlite3_tokenizer_module немедленно после того, как объект создается, чтобы
передать языковой id, который должен использовать токенизатор.
Метод xLanguageid() никогда не будут вызывать несколько раз ни для какого
единственного объекта токенизатора. То, что различные языки могли бы быть
размечены по-другому, является одной из причин, почему никакой единственный
запрос FTS не может возвратить строки с различными значениями languageid.
6.4. Опция matchinfo=
Опция matchinfo может быть установлен только в значение "fts3".
Попытка установить matchinfo во что-либо кроме "fts3" является
ошибкой. Если этот выбор определяется, то часть дополнительной информации,
хранимой FTS4, пропущена. Это уменьшает сумму дискового пространства,
потребляемого таблицей FTS4, но также означает, что данные, к которым
получают доступ, передавая флаг 'l' в функцию
matchinfo(), недоступны.
6.5. Опция notindexed=
Обычно модуль FTS поддерживает инвертированный индекс всех условий во всех
колонках таблицы. Этот выбор используется, чтобы определить название колонки,
для которой записи не должны быть добавлены к индексу.
Многократные "notindexed" варианты могут использоваться, чтобы
определить, что многочисленные колонки должны быть пропущены. Например:
-- Create an FTS4 table for which only the contents of columns c2 and c4
-- are tokenized and added to the inverted index.
CREATE VIRTUAL TABLE t1 USING fts4(c1, c2, c3, c4, notindexed=c1, notindexed=c3);
Значения, сохраненные в неиндексируемых колонках, не могут соответствовать
операторам MATCH. Они не влияют на результаты offsets() или matchinfo().
Функция snippet() не будет когда-либо возвращает отрывок на основе
значения, сохраненного в неиндексируемой колонке.
6.6. Опция prefix=
Опция FTS4 prefix предписывает FTS индексировать префиксы термина
указанных длин таким же образом, как это всегда индексирует полные термины.
Выбор префикса должен быть установлен в список разделенных запятой значений
положительных целых чисел отличных от нуля. Для каждого значения N
в списке, внесены в указатель префиксы длиной N байт (когда закодировано,
используя UTF-8). FTS4 использует индексы префикса термина, чтобы ускорить
префиксные запросы.
Цена конечно, то, что префиксы термина индексирования, а также полные
термины увеличивают размер базы данных и замедляют операции записи
на таблице FTS4.
Индексы префикса могут использоваться, чтобы оптимизировать
префиксные запросы в двух случаях.
Если запрос для префикса N байт, то индекс префикса, созданный с "prefix=N",
обеспечивает лучшую оптимизацию. Или, если никакой "prefix=N"
индекс недоступен, то индекс "prefix=N+1" может использоваться
вместо этого. Использовать индекс "prefix=N+1" менее эффективно,
чем индекс "prefix=N", но не хуже, чем никакого
индекса префикса вообще.
-- Create an FTS4 table with indexes to optimize 2 and 4 byte prefix queries.
CREATE VIRTUAL TABLE t1 USING fts4(c1, c2, prefix="2,4");
-- The following two queries are both optimized using the prefix indexes.
SELECT * FROM t1 WHERE t1 MATCH 'ab*';
SELECT * FROM t1 WHERE t1 MATCH 'abcd*';
-- The following two queries are both partially optimized using the prefix
-- indexes. The optimization is not as pronounced as it is for the queries
-- above, but still an improvement over no prefix indexes at all.
SELECT * FROM t1 WHERE t1 MATCH 'a*';
SELECT * FROM t1 WHERE t1 MATCH 'abc*';
7.
Специальные команды для FTS3 и FTS4
Специальный INSERT может использоваться, чтобы дать команду таблицам FTS3
и FTS4. У каждой FTS3 и FTS4 есть скрытая колонка только для чтения, которая
является тем же самым именем, как сама таблица.
INSERT в этот скрытый столбец интерпретируется как команды к таблице FTS3/4.
Для таблицы с именем "xyz" следующие команды поддерживаются:
INSERT INTO xyz(xyz) VALUES('optimize'); INSERT INTO xyz(xyz) VALUES('rebuild'); INSERT INTO xyz(xyz) VALUES('integrity-check'); INSERT INTO xyz(xyz) VALUES('merge=X,Y'); INSERT INTO xyz(xyz) VALUES('automerge=N');
7.1. Команда "optimize"
Команда "optimize" заставляет FTS3/4 сливать вместе все свои b-деревья
инвертированного индекса в одно большое и полное b-дерево. Выполнение
оптимизирования сделает последующие запросы управляемыми быстрее, так как
есть меньше b-деревьев, чтобы искать, и может уменьшить использование диска,
соединив избыточные записи. Однако, для большой таблицы FTS оптимизация
может быть столь же дорогой, как VACUUM.
Команда optimize по существу должна прочитать и написать всю таблицу FTS,
приводящий к большой транзакции.
В операции пакетного режима, где таблица FTS первоначально создается,
используя большое количество операций INSERT, затем неоднократно
запрашивается без дальнейших изменений, часто хорошая идея выполнить
"optimize" после последней INSERT, но перед первым запросом.
7.2. Команда "rebuild"
Команда "rebuild" заставляет SQLite отказаться от всей таблицы FTS3/4 и
затем восстанавливать ее снова из исходного текста. Понятие подобно
REINDEX,
только это относится к таблице FTS3/4 вместо обысного индекса.
Командой "rebuild" нужно управлять каждый раз, когда свое внедрение
токенизатора изменилось, чтобы все содержание могло быть повторно размечено.
Команда "rebuild" также полезна, используя
опции контента FTS4
после того, как изменения были внесены в оригинальную таблицу содержания.
7.3. Команда "integrity-check"
Команда "integrity-check" заставляет SQLite читать и проверять точность
всех перевернутых индексов в таблице FTS3/4, сравнивая те перевернутые
индексы с оригинальным содержанием. Команда "integrity-check"
тихо имеет успех, если перевернутые индексы в норме,
но потерпит неудачу с ошибкой SQLITE_CORRUPT, если
какие-либо проблемы найдены.
Команда "integrity-check" подобна в понятии
PRAGMA integrity_check.
В рабочей системе "integrity-command"
должна всегда быть успешной. Возможные причины неудач
проверки целостности включают:
- Приложение внесло изменения в
теневые таблицы FTS
непосредственно, не используя виртуальные таблицы FTS3/4, заставив теневые
таблицы выйти из синхронизации друг с другом.
- Использованы опции контента FTS4,
но не в состоянии вручную держать содержание в синхронизации с
инвертированным индексом FTS4.
- Ошибка в виртуальной таблице FTS3/4. "integrity-check" была оригинально
задумана как часть набора тестов для FTS3/4.
- Повреждение основного файла базы данных SQLite. См.
здесь подробности.
7.4. Команда "merge=X,Y"
Команда "merge=X,Y" (здесь X и Y это integer)
заставляет SQLite делать ограниченный объем работы по слиянию различных
b-деревьев инвертированного индекса таблицы FTS3/4 вместе в одно большое
b-дерево. X это целевое количество "блоков", которые будут слиты,
Y это минимальное количество сегментов b-дерева на уровне, требуемом, прежде
чем слияние будет применено к тому уровню.
Y должно быть между 2 и 16 с рекомендуемым значением 8.
X может быть любым положительным целым числом, но рекомендуются
значения от 100 до 300.
Когда таблица FTS накопит 16 сегментов b-дерева на том же самом уровне,
следующий INSERT в эту таблицу заставит все 16 сегментов быть слитыми в
единственный сегмент b-дерева на следующем более высоком уровне.
Эффект этих слияний уровней состоит в том, что большая часть INSERT в таблицу
FTS очень быстра и занимает минимальную память,
но случайный INSERT медленный и производит большую транзакцию
из-за потребности сделать слияние. Это приводит к
"остроконечному" исполнению INSERT.
Чтобы избежать остроконечной работы INSERT, приложение может выполнить
"merge=X,Y" периодически, возможно в простаивающем потоке или процессе,
чтобы гарантировать, что таблица FTS никогда не накапливает слишком много
сегментов b-дерева на том же самом уровне. Исполнительных проблем INSERT
можно обычно избегать, и исполнение FTS3/4 может быть максимизировано,
выполняя "merge=X,Y" после каждых нескольких тысяч вставок документа.
Каждая "merge=X,Y" работает в отдельной транзакции
(если они не будут группироваться, используя
BEGIN...
COMMIT, конечно). Транзакции могут быть сохранены маленькими, выбрав
значение для X в диапазоне 100-300. Простаивающий поток, который
управляет командами слияния, может знать, когда она сделана, проверив
различие в sqlite3_total_changes()
прежде и после каждой команды "merge=X,Y" и остановив цикл,
когда различие понижается ниже двух.
7.5. Команда "automerge=N"
Команда "automerge=N" (N это integer от 0 до 15, включительно)
используется, чтобы формировать параметр "automerge" таблиц FTS3/4,
который управляет автоматическим возрастающим слиянием инвертированного
индекса. Значение по умолчанию для новых таблиц 0, означая, что
автоматическое возрастающее слияние полностью отключено. Если значение
изменяется, используя команду "automerge=N",
новое значение параметра постоянно хранится в базе данных и используется
всеми впоследствии установленными соединениями с базой данных.
Установка параметра automerge в
ненулевое значение позволяет автоматическое возрастающее слияние.
Это заставляет SQLite делать небольшое количество инвертированного индекса,
сливающегося после каждой операции INSERT. Объем слияния разработан так,
чтобы таблица FTS3/4 никогда не достигала точки, где это имеет 16 сегментов
на том же самом уровне и следовательно должно сделать большое слияние,
чтобы закончить вставку. Другими словами, автоматическое возрастающее слияние
разработано, чтобы предотвратить остроконечную работу INSERT.
Оборотная сторона автоматического возрастающего слияния в том, что оно
делает каждый INSERT, UPDATE и DELETE на таблице FTS3/4 немного медленнее,
так как дополнительное время должно использоваться, чтобы сделать
возрастающее слияние. Для максимальной производительности рекомендуется,
чтобы приложение отключило автоматическое возрастающее слияние и вместо этого
использовало команду "merge"
в неработающем процессе, чтобы сохранять перевернутые индексы хорошо слитыми.
Но если структура применения не допускает неработающие процессы,
использование автоматического возрастающего слияния это
очень разумное решение.
Фактическое значение параметра определяет количество сегментов индекса,
слитых одновременно автоматическим слиянием инвертированного индекса.
Если значение установлено к N, система ждет, пока нет, по крайней мере, N
сегментов на единственном уровне прежде, чем начать сливать их.
Урегулирование нижнего значения N заставляет сегменты быть слитыми более
быстро, что может ускорить полнотекстовые запросы и, если рабочая нагрузка
содержит UPDATE, DELETE или INSERT, уменьшить пространство на диске,
потребляемое полнотекстовым индексом.
Однако, это также увеличивает объем данных, написанный на диск.
Для общего использования в случаях, где рабочая нагрузка содержит немного
UPDATE или DELETE, хороший выбор для automerge равняется 8.
Если рабочая нагрузка содержит много UPDATE или DELETE, или если скорость
запроса вызывает беспокойство, может быть выгодно уменьшить automerge до 2.
По причинам совместимости, "automerge=1" установит параметр
automerge = 8, не в 1 (1 не имело бы никакого смысла так или иначе, поскольку
данные из единственного сегмента не сливаются).
8. Токенизаторы
Токенизатор FTS является рядом правил для извлечения условий из документа
или основного полнотекстового запроса FTS.
Если определенный токенизатор не определяется как часть CREATE
VIRTUAL TABLE, по умолчанию используется "simple".
Простой токенизатор извлекает символы из документа или основного
полнотекстового запроса FTS согласно следующим правилам:
Термин это смежная последовательность знаков, где знаки это
все алфавитно-цифровые символы и все знаки со значениями кодовой точки
Unicode больше или равным 128.
От всех других знаков отказываются, разделяя документ на термины.
Их единственный вклад должен отделить смежные термины. Все символы верхнего регистра в диапазоне ASCII (кодовые точки Unicode
меньше 128), преобразовываются к их строчным эквивалентам как часть процесса
токенизации. Таким образом полнотекстовые запросы нечувствительны к регистру,
используя простой токенизатор.
Например, когда документ, содержащий текст "Right now, they're very
frustrated.", условия, извлечены из документа и добавлены к полнотекстовому
индексу в порядке "right now they re very frustrated".
Такой документ соответствовал бы полнотекстовому запросу, такому как
"MATCH 'Frustrated'", поскольку простой токенизатор преобразовывает термин в
запросе к строчным буквам прежде, чем искать полнотекстовый индекс.
А также исходный код FTS показывает токенизатор, который использует
Porter Stemming
algorithm. Этот токенизатор использует те же самые правила, чтобы
разделить входной документ на термины, включая сворачивание всех терминов в
нижний регистр, но также использует алгоритм Porter Stemming,
чтобы уменьшить связанные английские языковые слова до общего корня.
Например, используя тот же самый входной документ в параграфе выше,
токенизатор извлекает следующие символы: "right now thei veri frustrat".
Даже при том, что некоторые из этих условий даже не английские слова, в
некоторых случаях использование их, чтобы построить полнотекстовый индекс
более полезно, чем более понятный вывод, произведенный простым токенизатор.
Используя этот токенизатор, документ не только соответствует полнотекстовым
запросам, таким как "MATCH 'Frustrated'", но также и запросам, таким как
"MATCH 'Frustration'", поскольку термин "Frustration"
уменьшается до "frustrat", как и "Frustrated". Так, используя этот алгоритм,
FTS в состоянии найти не только точные совпадения для запрошенных
условий, но и соответствия подобных английских языковых условий.
Пример, иллюстрирующий различие между "simple" и "porter":
-- Create a table using the simple tokenizer. Insert a document into it.
CREATE VIRTUAL TABLE simple USING fts3(tokenize=simple);
INSERT INTO simple VALUES('Right now they''re very frustrated');
-- The first of the following two queries matches the document stored in
-- table "simple". The second does not.
SELECT * FROM simple WHERE simple MATCH 'Frustrated';
SELECT * FROM simple WHERE simple MATCH 'Frustration';
-- Create a table using the porter tokenizer. Insert the same document into it
CREATE VIRTUAL TABLE porter USING fts3(tokenize=porter);
INSERT INTO porter VALUES('Right now they''re very frustrated');
-- Both of the following queries match the document stored in table "porter".
SELECT * FROM porter WHERE porter MATCH 'Frustrated';
SELECT * FROM porter WHERE porter MATCH 'Frustration';
Если это расширение собрано с определенным символом препроцессора
SQLITE_ENABLE_ICU, то там существует, встроенный токенизатор, названный
"icu", который использует библиотеку ICU. Первым аргументом, переданным
методу xCreate() (см. fts3_tokenizer.h) этого токенизатора, может быть
идентификатор локали ICU. Например, "tr_TR" для турецкого при применении в
Турции или "en_AU" для австралийского английского. Например:
CREATE VIRTUAL TABLE thai_text USING fts3(text, tokenize=icu th_TH)
Токенизатор ICU очень прост. Это разделяет входной текст согласно
правилам ICU для нахождения границ слова и отказывается от любых символов,
которые состоят полностью из пробелов. Это может подойти для некоторых
применений в некоторых местах действия, но не всех. Если более сложная
обработка требуется, например чтобы осуществить пунктуацию, это может быть
сделано, создав токенизатор, который использует токенизатор ICU в качестве
части его внедрения.
Токенизатор "unicode61" доступен с SQLite
version 3.7.13 (2012-06-11).
Unicode61 работает очень похоже на "simple"
за исключением того, что это делает простой случай unicode, сворачивающийся
согласно правилам в Unicode Version 6.1, и это признает в unicode пробелы и
символы пунктуации и использует их, чтобы отделить символы.
Простой токенизатор сворачивает только знаки ASCII и признает только пробелы
ASCII и символы пунктуации как символические сепараторы.
По умолчанию "unicode61" пытается удалить диакритические знаки из
латинских символов. Это поведение может быть отвергнуто, добавив токенизатору
аргумент "remove_diacritics=0":
-- Create tables that remove alldiacritics from Latin script characters
-- as part of tokenization.
CREATE VIRTUAL TABLE txt1 USING fts4(tokenize=unicode61);
CREATE VIRTUAL TABLE txt2 USING fts4(tokenize=unicode61 "remove_diacritics=2");
-- Create a table that does not remove diacritics from Latin script
-- characters as part of tokenization.
CREATE VIRTUAL TABLE txt3 USING fts4(tokenize=unicode61 "remove_diacritics=0");
Опция remove_diacritics может быть установлена в "0", "1" или "2".
По умолчанию "1". Если это установлено в "1" или "2",
диакритические знаки удалены из латинских символов, как описано выше.
Однако, если это установлено в "1", диакритические знаки не удалены в
довольно необычном случае, где единственная unicode кодовая точка
используется, чтобы представлять символ с больше, чем одним диакритическим
знаком. Например, диакритические знаки не удалены из кодовой точки 0x1ED9
("LATIN SMALL LETTER O WITH CIRCUMFLEX AND DOT BELOW").
Это технически ошибка, но не может быть исправлена, не создавая проблемы
совместимости. Если этот выбор установлен в "2", то диакритические
знаки правильно удалены у всех латинских символов.
Также возможно настроить набор кодовых точек, которые unicode61
рассматривает как символы разделителя. Опция "separators=" может
использоваться, чтобы определить один или несколько дополнительных символов,
которые нужно рассматривать как символы разделителя, и опция
"tokenchars=" может использоваться, чтобы
определить один или несколько дополнительных символов, которые нужно
рассматривать как токены вместо символов-разделителей:
-- Create a table that uses the unicode61 tokenizer, but considers "."
-- and "=" characters to be part of tokens, and capital "X" characters to
-- function as separators.
CREATE VIRTUAL TABLE txt3 USING fts4(tokenize=unicode61 "tokenchars=.=" "separators=X");
-- Create a table that considers space characters (codepoint 32) to be
-- a token character
CREATE VIRTUAL TABLE txt4 USING fts4(tokenize=unicode61 "tokenchars= ");
Если символ, определенный как часть аргумента "tokenchars=",
считается токеном по умолчанию, это проигнорировано. Это верно, даже если это
было отмечено как сепаратор раньше в "separators=".
Точно так же, если символ, определенный как часть "separators=",
рассматривают как символ разделителя по умолчанию, это проигнорировано.
Если много "tokenchars=" или "separators="
определяется, обрабатываются все. Например:
-- Create a table that uses the unicode61 tokenizer, but considers "."
-- and "=" characters to be part of tokens, and capital "X" characters to
-- function as separators. Both of the "tokenchars=" options are processed
-- The "separators=" option ignores the "." passed to it, as "." is by
-- default a separator character, even though it has been marked as a token
-- character by an earlier "tokenchars=" option.
CREATE VIRTUAL TABLE txt5 USING fts4(tokenize=unicode61 "tokenchars=."
"separators=X." "tokenchars==");
Аргументы, переданные "tokenchars=" или "separators=",
чувствительные к регистру. В примере выше, определение того, что "X" это
символ разделителя, не затрагивает обработку "x".
8.1. Определенные приложением токенизаторы
В дополнение к обеспечению встроенных токенизаторов "simple", "porter",
"icu" и "unicode61", FTS обеспечивает интерфейс, чтобы
осуществить и зарегистрировать токенизаторы, написанные на C.
Интерфейс, используемый, чтобы создать новый токенизатор, определен и описан
в исходном файле fts3_tokenizer.h.
Регистрация нового токенизатора FTS подобна регистрации нового
виртуального модуля таблицы в SQLite. Пользователь передает указатель на
структуру, содержащую указатели на различные функции обратного вызова,
которые составляют внедрение нового типа токенизатора. Для структуры
токенизатора (определена в fts3_tokenizer.h) вызывают
"sqlite3_tokenizer_module".
FTS не выставляет C-функцию, которую пользователи вызывают, чтобы
зарегистрировать новые типы токенизаторов в дескрипторе
базы данных. Вместо этого указатель должен быть закодирован как значение SQL
blob и передан к FTS через SQL, оценив специальную скалярную функцию,
"fts3_tokenizer()". Функцию fts3_tokenizer()
можно вызвать с одним или двумя аргументами следующим образом:
SELECT fts3_tokenizer(<tokenizer-name>);
SELECT fts3_tokenizer(<tokenizer-name>, <sqlite3_tokenizer_module ptr>);
<tokenizer-name> это parameter
, для которого последовательность связана, используя
sqlite3_bind_text(),
где последовательность определяет, что токенизатор и
<sqlite3_tokenizer_module ptr> это
параметр, привязанный к BLOB через
sqlite3_bind_blob(),
здесь значение BLOB это указатель на структуру sqlite3_tokenizer_module.
Если второй аргумент присутствует, он зарегистрирован как
<tokenizer-name>, и его копия возвращена.
Если только один аргумент передается, указатель на токенизатор, в настоящее
время токенизатор регистрируется как <tokenizer-name>, это возвращено
как blob. Или, если никакой такой токенизатор не существует, исключение
SQL (ошибка) поднято.
До SQLite version 3.11.0
(2016-02-15) аргументами fts3_tokenizer()
могли быть литеральные строки или BLOB. Они не должны были быть
связанными параметрами.
Но это могло привести к проблемам безопасности в случае SQL injection.
Следовательно, устаревшее поведение теперь отключено по умолчанию.
Но старое устаревшее поведение может быть позволено для совместимости в
приложенияз, для которых действительно нужно, вызывая
sqlite3_db_config(db,
SQLITE_DBCONFIG_ENABLE_FTS3_TOKENIZER,1,0).
Следующий блок содержит пример запроса функции fts3_tokenizer()
из кода на C:
/*
** Register a tokenizer implementation with FTS3 or FTS4.
*/
int registerTokenizer(sqlite3 *db, char *zName,
const sqlite3_tokenizer_module *p)
{
int rc;
sqlite3_stmt *pStmt;
const char *zSql = "SELECT fts3_tokenizer(?1, ?2)";
rc = sqlite3_prepare_v2(db, zSql, -1, &pStmt, 0);
if( rc!=SQLITE_OK ){
return rc;
}
sqlite3_bind_text(pStmt, 1, zName, -1, SQLITE_STATIC);
sqlite3_bind_blob(pStmt, 2, &p, sizeof(p), SQLITE_STATIC);
sqlite3_step(pStmt);
return sqlite3_finalize(pStmt);
}
/*
** Query FTS for the tokenizer implementation named zName.
*/
int queryTokenizer(sqlite3 *db, char *zName,
const sqlite3_tokenizer_module **pp)
{
int rc;
sqlite3_stmt *pStmt;
const char *zSql = "SELECT fts3_tokenizer(?)";
*pp = 0;
rc = sqlite3_prepare_v2(db, zSql, -1, &pStmt, 0);
if( rc!=SQLITE_OK ){
return rc;
}
sqlite3_bind_text(pStmt, 1, zName, -1, SQLITE_STATIC);
if( SQLITE_ROW==sqlite3_step(pStmt) ){
if( sqlite3_column_type(pStmt, 0)==SQLITE_BLOB ){
memcpy(pp, sqlite3_column_blob(pStmt, 0), sizeof(*pp));
}
}
return sqlite3_finalize(pStmt);
}
8.2. Запрос токенизатора
Виртуальная таблица "fts3tokenize" может использоваться, чтобы
непосредственно получить доступ к любому токенизатору. Следующий SQL
демонстрирует, как создать экземпляр виртуальной таблицы fts3tokenize:
CREATE VIRTUAL TABLE tok1 USING fts3tokenize('porter');
Названием желаемого токенизатора нужно заменить 'porter'
в примере, конечно. Если токенизатор требует одного или более аргументов, они
должны быть отделены запятыми в декларации fts3tokenize
(даже при том, что они отделены пробелами в декларациях обычных таблиц fts4).
Следующее создает таблицы fts4 и fts3tokenize, которые используют тот
же самый токенизатор:
CREATE VIRTUAL TABLE text1 USING fts4(tokenize=icu en_AU);
CREATE VIRTUAL TABLE tokens1 USING fts3tokenize(icu, en_AU);
CREATE VIRTUAL TABLE text2 USING fts4(tokenize=unicode61 "tokenchars=@." "separators=123");
CREATE VIRTUAL TABLE tokens2 USING fts3tokenize(unicode61, "tokenchars=@.", "separators=123");
Как только виртуальная таблица составлена, она может быть
запрошена следующим образом:
SELECT token, start, end, position FROM tok1
WHERE input='This is a test sentence.';
Виртуальная таблица возвратит одну строку вывода
для каждого символа во входной строке.
Колонка "token" это текст символа. Колонки "start" и "end"
байтовое смещение к началу и концу символа в оригинальной входной строке.
Колонка "position" это порядковый номер символа в оригинальной входной
строке. Есть также колонка "input", которая является просто копией входной
строки, которая определяется в операторе Where. Отметьте, что ограничение
формы "input=?" должно появиться в операторе Where, иначе виртуальная таблица
не будет иметь никакого входа, чтобы разметить, и не возвратит строк.
Пример выше производит следующий вывод:
thi|0|4|0
is|5|7|1
a|8|9|2
test|10|14|3
sentenc|15|23|4
Заметьте, что символы в наборе результатов от виртуальной таблицы
fts3tokenize были преобразованы согласно правилам токенизатора.
Так как этот пример использовал токенизатор "porter", токен "This"
был преобразован в "thi". Если исходный текст символа желаем, это может быть
восстановлено, используя колонки "start" и "end" функцией
substr():
SELECT substr(input, start+1, end-start), token, position
FROM tok1 WHERE input='This is a test sentence.';
Виртуальная таблица fts3tokenize может использоваться на любом
токенизаторе, независимо от того, существует ли там таблица FTS3 или FTS4,
которую на самом деле использует этот токенизатор.
9.
Структуры данных
Эта секция описывает на высоком уровне, как
модуль FTS хранит свой индекс и содержание в базе данных.
Не необходимо прочитать или понять материал в этой секции, чтобы
использовать FTS в применении. Однако, это может быть полезно для
разработчиков приложений, пытающихся проанализировать и понять показатели
производительности FTS, или разработчикам, рассматривающим улучшения к
существующему набору функций FTS.
9.1. Теневые таблицы
Для каждой виртуальной таблицы FTS в базе данных,
три-пять реальных (невиртуальных) таблиц составлены, чтобы хранить основные
данные. Эти реальные таблицы называют "теневыми таблицами".
Реальные таблицы называют "%_content", "%_segdir", "%_segments", "%_stat" и
"%_docsize", где "%" заменяется названием виртуальной таблицы FTS.
Крайним левым столбцом таблицы "%_content" является поле INTEGER PRIMARY
KEY с именем "docid". После этого одна колонка для каждой колонки виртуальной
таблицы FTS, как объявлено пользователем, названа, дополнив имя столбца,
поставляемое пользователем, префиксом "cN", где N это
индекс колонки в таблице слева направо, начиная с 0.
Типы данных, поставляемые как часть виртуальной декларации таблицы, не
используются в качестве части декларации таблицы %_content:
-- Virtual table declaration
CREATE VIRTUAL TABLE abc USING fts4(a NUMBER, b TEXT, c);
-- Corresponding %_content table declaration
CREATE TABLE abc_content(docid INTEGER PRIMARY KEY, c0a, c1b, c2c);
Таблица %_content содержит настоящие данные, вставленные пользователем в
виртуальную таблицу FTS пользователем.
Если пользователь явно не поставляет значение "docid", вставляя
записи, оно выбрано автоматически системой.
Таблицы %_stat и %_docsize создаются только, если таблица FTS использует
модуль FTS4, но не FTS3. Кроме того, таблица %_docsize
опущена, если таблица FTS4 составлена с
"matchinfo=fts3", указанной как часть CREATE VIRTUAL TABLE.
Если они создаются, схемы этих двух таблиц следующие:
CREATE TABLE %_stat(id INTEGER PRIMARY KEY, value BLOB);
CREATE TABLE %_docsize(docid INTEGER PRIMARY KEY, size BLOB);
Для каждой строки в таблице FTS таблица %_docsize
содержит соответствующую строку с тем же самыс значением "docid".
Поле "size" содержит blob, состоящий из N FTS varints, где N
это количество определенных пользователями колонок в таблице. Каждый varint в
"size" blob это количество символов в соответствующей колонке связанной
строки в таблице FTS. Таблица %_stat всегда содержит единственную строку с
колонкой "id" = 0. Колонка "value" содержит blob, состоящий из
N+1 FTS varints, где N это
количество определенных пользователями колонок в таблице FTS. Первый varint в
blob установлен в общее количество строк в таблице FTS. Вторые и последующие
varints содержат общее количество символов, сохраненных в соответствующей
колонке для всех строк таблицы FTS.
Две остающихся таблицы, %_segments и %_segdir,
используются, чтобы сохранить полнотекстовый индекс. Концептуально, этот
индекс это таблица поиска, которая отображает
каждый термин (слово) к набору значений docid, соответствующих записям в
таблице %_content, которые содержат одни или более случаев термина.
Чтобы восстановить все документы, которые содержат указанный термин, модуль
FTS запрашивает этот индекс, чтобы определить набор значений docid для
записей, которые содержат термин, затем восстанавливает необходимые документы
от таблицы %_content. Независимо от схемы виртуальной таблицы FTS, таблицы
%_segments и %_segdir всегда создаются следующим образом:
CREATE TABLE %_segments(
blockid INTEGER PRIMARY KEY, -- B-tree node id
block blob -- B-tree node data
);
CREATE TABLE %_segdir(level INTEGER, idx INTEGER,
start_block INTEGER, -- Blockid of first node in %_segments
leaves_end_block INTEGER, -- Blockid of last leaf node in %_segments
end_block INTEGER, -- Blockid of last node in %_segments
root BLOB, -- B-tree root node
PRIMARY KEY(level, idx)
);
Схема, изображенная выше, не разработана, чтобы сохранить полнотекстовый
индекс непосредственно. Вместо этого это используется, чтобы сохранить одну
или более b-древовидных-структур. Есть одно b-дерево для каждой строки в
таблице %_segdir. Строка таблицы %_segdir
содержит корневой узел и различные метаданные, связанные с
b-древовидной-структурой, а таблица %_segments
содержит все другие (некорневые) узлы b-дерева. Каждое b-дерево упоминается
как "сегмент". Как только это было создано, b-дерево сегмента
никогда не обновляется (хотя это может быть удалено в целом).
Ключи, используемые каждым b-деревом сегмента, являются терминами
(словами). У каждого входа b-дерева сегмента есть связанный "doclist"
(document list). doclist состоит из ноля или большего количества записей,
где каждый вход состоит из:
- docid (document id)
- Список смещений термина, одно для каждого возникновения термина в рамках
документа. Смещение термина указывает на количество символов
(слов), которые происходят перед рассматриваемым термином, а не количество
знаков или байтов. Например, смещение термина "war" во фразе
"Ancestral voices prophesying war!" = 3.
Записи в doclist сортированы по docid. Позиции входа в рамках doclist
сохранены в порядке возрастания.
Содержание логического полнотекстового индекса найдено, слив содержание
всех b-деревьев сегмента. Если термин присутствует больше,
чем в одном b-дереве сегмента, то это отображается к объединению
каждого отдельного doclist. Если для единственного термина тот же самый docid
происходит больше, чем в одном doclist, то только doclist, который является
частью последний раз созданного b-дерева сегмента, считают действительным.
Многократные b-древовидные-структуры используются вместо единственного
b-дерева, чтобы уменьшить значение вставки записей в таблицы FTS. Когда новая
запись вставляется в таблицу FTS, которая уже содержит много данных,
вероятно, что многие термины в новой записи уже присутствуют в большом
количестве существующих записей. Если бы единственное b-дерево
использовалось, то большие doclist-структуры должны были бы быть загружены из
базы данных, исправленной, чтобы включать новый docid и список смещений
термина, написанные назад в базу данных.
Использование многократного b-дерева таблицы позволяет этого избежать,
создавая новое b-дерево, которое может быть слито с существующим b-деревом
(или b-деревьями) позже.
Слияние b-древовидных-структур может быть выполнено как фоновая задача, или
как только определенное число отдельных b-древовидных-структур было
накоплено. Конечно, эта схема делает запросы более дорогими (поскольку коду
FTS, вероятно, придется искать отдельные термины больше, чем в одном
b-дереве и сливать результаты), но было найдено, что на практике
издержки часто незначительны.
Значения Integer, сохраненные как часть узлов b-дерева сегмента,
закодированы, используя формат FTS varint.
Это кодирование подобно, но не идентично
формату SQLite varint.
Закодированный FTS varint потребляет от одного до десяти байт.
Число требуемых байтов определяется знаком и величиной закодированного
целочисленного значения. Более точно число байтов, используемых, чтобы
сохранить закодированное целое число, зависит от положения старшего значащего
бита 64-bit twos-complement представлении целочисленного значения.
Отрицательные величины всегда имеют установленный старший значащий
бит (знаковый бит) и всегда хранятся, используя полные десять байт.
Положительные целочисленные значения могут быть сохранены,
использовав меньше места.
Заключительному байту закодированного FTS varint очистили его старший
значащий бит. У всех предыдущих байтов есть установленный старший бит.
Данные хранятся в оставшихся семи младших значащих битах каждого байта.
Первый байт закодированного представления содержит младшие значащие семь
битов закодированного целочисленного значения. Второй байт закодированного
представления, если это присутствует, содержит семь следующих младших
значащих бит целочисленного значения и так далее. Следующая таблица содержит
примеры закодированных целочисленных значений:
| Decimal | Hexadecimal |
Закодированное представление |
|---|
| 43 |
0x000000000000002B | 0x2B |
| 200815 | 0x000000000003106F |
0xEF 0xA0 0x0C |
| -1 |
0xFFFFFFFFFFFFFFFF | 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF 0xFF
0xFF 0xFF 0x01 |
B-деревья сегмента сжаты префиксом b+-trees. Есть одно b-дерево сегмента
для каждой строки в таблице %_segdir. Корневой узел b-дерева сегмента
сохранен как blob в поле "root" соответствующей строки таблицы %_segdir.
Все другие узлы (если существуют) сохранены в колонке "blob" таблицы
%_segments. Узлы в таблице %_segments определяются целочисленным значением в
поле blockid соответствующей строки. Следующая таблица описывает
поля таблицы %_segdir:
| Столбец | Смысл
|
|---|
|
level | Содержание полей "level" и "idx" определяет относительный
возраст b-дерева сегмента. Чем меньше значение в поле "level",
тем позже b-дерево сегмента было создано. Если два b-дерева сегмента
имеют тот же самый "level", сегмент с большим значением "idx"
более свеж. Ограничение PRIMARY KEY на таблице %_segdir
препятствует тому, чтобы любые два сегмента имели то же самое
значение "level" и "idx". |
| idx | См. выше. |
| start_block |
blockid, который соответствует узлу с самым маленьким blockid, который
принадлежит этому b-дереву сегмента. Или ноль, если все b-дерево сегмента
помещается в корневом узле. Если это существует, этот узел всегда вершина.
| | leaves_end_block |
blockid, который соответствует вершине с самым большим blockid, который
принадлежит этому b-дереву сегмента. Или ноль, если все b-дерево
сегмента в корневом узле. |
| end_block |
Поле может содержать или целое число или текстовое поле, состоящее из двух
целых чисел, отделенных пробелом (unicode кодовая точка 0x20).
Первое или единственное целое число
blockid, который соответствует внутреннему узлу с самым большим blockid,
который принадлежит этому b-дереву сегмента.
Или ноль, если все b-дерево сегмента в корневом узле.
Если это существует, этот узел всегда внутренний узел.
Второе целое число, если это присутствует, является совокупным размером всех
данных, хранивших на страницах листа в байтах. Если значение отрицательно,
то сегмент это вывод незаконченной операции возрастающего слияния, и
абсолютное значение это текущий размер в байтах. |
| root |
Blob, содержащий корневой узел b-дерева сегмента. |
Кроме корневого узла, узлы, которые составляют единственное b-дерево
сегмента, всегда хранятся, используя смежную последовательность blockid.
Кроме того, узлы, которые составляют единственный уровень b-дерева,
самостоятельно сохранены как смежный блок в порядке b-дерева.
Смежная последовательность blockid, используемого, чтобы сохранить листья
b-дерева, ассигнуется, начиная со значения blockid, сохраненного в колонке
"start_block" соответствующей строки %_segdir,
и заканчивая значением blockid в поле "leaves_end_block"
той же самой строки. Поэтому возможно повторить через все листья b-дерева
сегмента, в ключевом порядке, проходя таблицу %_segments в порядке blockid
от "start_block" до "leaves_end_block".
9.3.1.
Вершины B-дерева сегмента
Следующая диаграмма изображает формат вершины b-дерева сегмента.
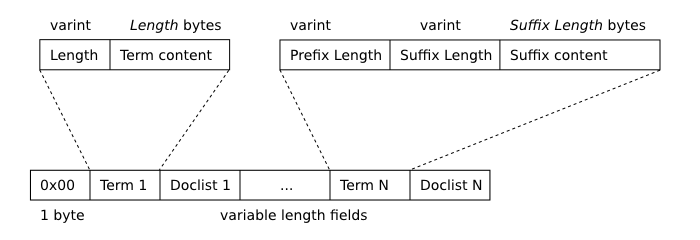
Формат вершины B-дерева сегмента
Первый термин, сохраненный в каждом узле ("Term 1" на рисунке выше)
сохранен дословно. Каждый последующий термин сжат префиксом относительно
его предшественника. Термины сохранены в странице в
сортированном (memcmp) порядке.
9.3.2. Узлы интерьера B-дерева сегмента
Следующая диаграмма изображает формат интерьера b-дерева
сегмента (нелист) узел.
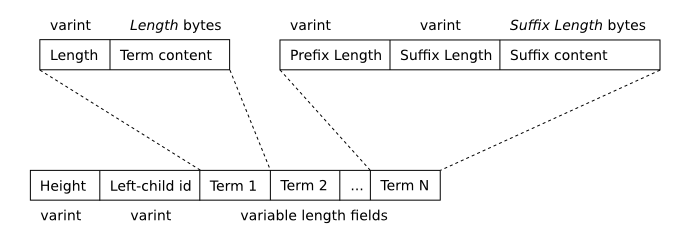
Формат узла интерьера B-дерева сегмента.
doclist состоит из множества 64-битных целых чисел со знаком,
преобразованного в последовательную форму с использованием формата FTS
varint. Каждый вход doclist составлен из серии из двух или больше целых
чисел следующим образом:
- docid. Первый вход в doclist содержит литеральное значение
docid. Первая область каждого последующего входа doclist содержит различие
между новым docid и предыдущим (всегда положительное число).
- Ноль или более списков смещений терминов. Список присутствует для каждой
колонки виртуальной таблицы FTS, которая содержит термин.
Список состоит из следующего:
ol>
- Постоянная величина 1. Эта область опущена для любого списка
смещений терминов, связанного с колонкой 0.
- Номер столбца (1 для второго крайнего левого столбца и т.д.).
Эта область опущена для любого списка смещений
терминов, связанного с колонкой 0.
- Список смещений термина, сортированных от самого маленького до самого
большого. Вместо того, чтобы хранить
значение буквально, каждое сохраненное целое число является различием между
текущим смещением термина и и предыдущим (или нолем, если текущее смещение
термина первое) + 2.
Постоянная величина 0.

Формат FTS3 Doclist
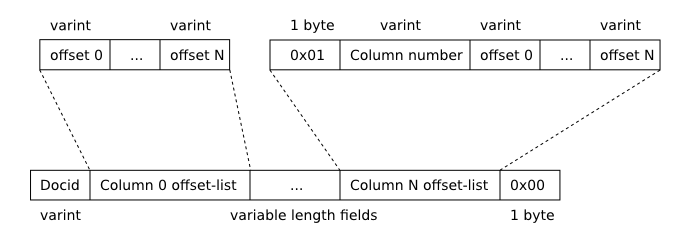
Формат записи FTS Doclist
Для doclist, для которого термин появляется больше, чем в одной колонке
виртуальной таблицы FTS, списки смещений термина в doclist сохранены в
порядке номера столбца. Это гарантирует, что список, связанный с колонкой 0
(если таковой имеется), всегда первый, позволяя первым двум областям
списка быть опущенными в этом случае.
10. Ограничения
10.1.
Проблема отметки порядка байтов UTF-16
Для баз данных UTF-16, используя токенизатор "simple",
возможно использовать уродливые последовательности unicode, чтобы заставить
команду integrity-check ложно сообщать о проблеме
или вспомогательным функциям возвращать неправильные
результаты. Более определенно ошибка может быть вызвана любым из следующего:
UTF-16 byte-order-mark (BOM) включен в начале
строкового литерала SQL, вставленного в таблицу FTS3. Например:
INSERT INTO fts_table(col) VALUES(char(0xfeff)||'text...');
Уродливый UTF-8, который SQLite преобразовывает в отметку порядка
байтов UTF-16, включен в начале значения
строкового литерала SQL, вставленного в таблицу FTS3. Текстовое значение, созданное из blob,
которое начинается с двух байтов 0xFF и 0xFE в любом возможном порядке,
вставляется в таблицу FTS3. Например:
INSERT INTO fts_table(col) VALUES(CAST(X'FEFF' AS TEXT));
Все работает правильно, если что-либо следующее верно:
-
Кодирование базы данных UTF-8.
- Все текстовые строки вставлены, используя одну из функций семейства
sqlite3_bind_text().
- Литеральные строки не содержат отметок порядка байтов.
- Токенизатор используется, который признает отметки порядка байтов как
пробелы (токенизатор по умолчанию "simple" для FTS3/4
не думает, что BOM это пробел, но токенизатор unicode это делает).
Все вышеупомянутые условия должны быть ложными для возникновения проблем.
Даже если все условия выше будут ложными, большинство вещей будет все еще
работать правильно. Только команда integrity-check
и вспомогательные функции могли бы
дать неожиданные результаты.
Приложение A. Подсказки поискового приложения
FTS, прежде всего, разработан, чтобы поддержать Boolean
полнотекстовые запросы, то есть запросы, чтобы найти набор документов,
которые соответствуют указанным критериям. Однако многие (большинство?)
поисковых приложений требуют, чтобы результаты были так или иначе оценены в
порядке "уместности", где "уместность" определяется как
вероятность, что пользователь, который выполнил поиск, интересуется
определенным элементом возвращенного набора документов.
Используя поисковую систему, чтобы найти документы во Всемирной паутине,
пользователь ожидает, что самые полезные или "соответствующие",
документы будут возвращены как первая страница результатов,
и что каждая последующая страница содержит прогрессивно менее соответствующие
результаты. Как машина может определить уместность документа на
основе пользовательского запроса это
сложная проблема и предмет большого продолжающегося исследования.
Одна очень простая схема могла бы состоять в том, чтобы посчитать
количество случаев пользовательских критериев поиска в каждом документе
результата. Те документы, которые содержат много случаев термина, считают
более релевантными, чем те, которые с небольшим количеством случаев каждого
термина. В применении FTS количество случаев термина в каждом результате
могло быть определено, считая количество целых чисел в возвращаемом значении
функции offsets. Следующий пример показывает
запрос, который мог использоваться, чтобы получить десять самых
соответствующих результатов для запроса, введенного пользователем:
-- This example (and all others in this section) assumes the following schema
CREATE VIRTUAL TABLE documents USING fts3(title, content);
-- Assuming the application has supplied an SQLite user function named "countintegers"
-- that returns the number of space-separated integers contained in its only argument,
-- the following query could be used to return the titles of the 10 documents that contain
-- the greatest number of instances of the users query terms. Hopefully, these 10
-- documents will be those that the users considers more or less the most "relevant".
SELECT title FROM documents WHERE documents MATCH <query>
ORDER BY countintegers(offsets(documents)) DESC LIMIT 10 OFFSET 0
Запрос выше мог быть сделан быстрее при помощи FTS
matchinfo, чтобы определить количество
случаев термина запроса, которые появляются в каждом результате.
Функция matchinfo намного более эффективна, чем функция offsets.
Кроме того, функция matchinfo предоставляет дополнительную информацию
относительно общего количества случаев каждого термина запроса во всем наборе
документов (не только текущей строке) и количества документов, в которых
появляется каждый термин запроса. Это может использоваться (например), чтобы
приложить более высокий вес к меньшему количеству распространенных слов,
которые могут увеличить полную вычисленную уместность тех результатов,
которые пользователь считает более интересными.
-- If the application supplies an SQLite user function called "rank" that
-- interprets the blob of data returned by matchinfo and returns a numeric
-- relevancy based on it, then the following SQL may be used to return the
-- titles of the 10 most relevant documents in the dataset for a users query.
SELECT title FROM documents WHERE documents MATCH <query>
ORDER BY rank(matchinfo(documents)) DESC LIMIT 10 OFFSET 0
SQL-запрос в примере выше использует меньше CPU, чем первый пример в этой
секции, но все еще имеет неочевидную исполнительную проблему.
SQLite удовлетворяет этот запрос, получая значение колонки "title"
и данные matchinfo из модуля FTS для каждой строки,
соответствующей пользовательскому запросу, прежде чем это сортирует и
ограничит результаты. Из-за работы интерфейса виртуальной таблицы SQLITE,
получение значения столбца "title" требует загрузки всей строки с диска
(включая поле "content", которое может быть довольно большим). Это означает,
что, если пользователи запрашивают соответствие
несколько тысяч документов, много мегабайтов данных данных "title" и
"content" могут быть загружены с диска в память даже при том, что они никогда
не будут использоваться ни для какой цели.
SQL-запрос в следующем блоке в качестве примера это одно из решений этой
проблемы. В SQLite, когда подзапрос,
используемый в соединении, содержит пункт LIMIT,
результаты подзапроса вычислены и сохранены во временной таблице, прежде чем
главный запрос будет выполнен. Это означает, что SQLite загрузит только
данные docid и matchinfo для каждой строки, соответствующей запросу
пользователя, в память, определяет значения docid, соответствующие десяти
самым соответствующим документам, затем загружает только название и
информацию о содержании только для тех 10 документов.
Поскольку значения matchinfo и docid подбираются полностью из полнотекстового
индекса, это приводит к существенно меньшему количеству данных, загружаемых
от базы данных в память.
SELECT title FROM documents JOIN (
SELECT docid, rank(matchinfo(documents)) AS rank
FROM documents WHERE documents MATCH <query>
ORDER BY rank DESC LIMIT 10 OFFSET 0) AS ranktable USING(docid)
ORDER BY ranktable.rank DESC
Следующий блок SQL увеличивает запрос с решениями двух других проблем,
которые могут возникнуть в развитии поисковых приложений, используя FTS:
Функция snippet
не может использоваться с вышеупомянутым запросом. Поскольку внешний запрос
не включает "WHERE ... MATCH", snippet не может использоваться с ним.
Одно решение состоит в том, чтобы дублировать оператор Where, используемый
подзапросом во внешнем запросе. Издержки этого обычно незначительны. Уместность документа может зависеть от чего-то другого, чем просто
доступные данные в возвращаемом значении matchinfo. Например, каждому
документу в базе данных можно назначить статический вес на основе факторов,
не связанных с его содержанием (происхождение, автор, возраст, количество
ссылок и т.д.). Эти значения могут быть сохранены применением в отдельной
таблице, к которой можно присоединиться для уточнения таблицы документов в
подзапросе так, чтобы функция rank могла получить доступ к ним.
Эта версия запроса очень похожа на используемый поиск по документации
на sqlite.org.
-- This table stores the static weight assigned to each document in FTS table
-- "documents". For each row in the documents table there is a corresponding row
-- with the same docid value in this table.
CREATE TABLE documents_data(docid INTEGER PRIMARY KEY, weight);
-- This query is similar to the one in the block above, except that:
--
-- 1. It returns a "snippet" of text along with the document title for display. So
-- that the snippet function may be used, the "WHERE ... MATCH ..." clause from
-- the sub-query is duplicated in the outer query.
--
-- 2. The sub-query joins the documents table with the document_data table, so that
-- implementation of the rank function has access to the static weight assigned
-- to each document.
SELECT title, snippet(documents) FROM documents JOIN (
SELECT docid, rank(matchinfo(documents), documents_data.weight)
AS rank FROM documents JOIN documents_data USING(docid)
WHERE documents MATCH <query>
ORDER BY rank DESC LIMIT 10 OFFSET 0) AS ranktable USING(docid)
WHERE documents MATCH <query> ORDER BY ranktable.rank DESC
Все запросы в качестве примера выше возвращают десять самых
соответствующих результатов запроса. Изменяя значения, используемые с
пунктами OFFSET и LIMIT, запрос возвращает (например)
следующие десять самых соответствующих результатов.
Это может использоваться, чтобы получить данные, требуемые для второй и
последующих страниц результатов в поисковых приложениях.
Следующий блок содержит функцию rank
в качестве примера, которая использует данные matchinfo, осуществленную на C.
Вместо одного веса это позволяет весу быть внешне назначенным на каждую
колонку каждого документа. Это может быть зарегистрировано в SQLite как любая
другая функция пользователя через
sqlite3_create_function.
Предупреждение системы безопасности:
Поскольку это просто обычная функция SQL, rank()
может быть вызвана как часть любого SQL-запроса в любом контексте.
Это означает, что первым переданным аргументом может не быть корректный
matchinfo blob. Разработчики должны озаботиться, чтобы обращаться с этим
случаем, не вызывая переполнение буфера или другие возможные проблемы защиты.
/*
** SQLite user defined function to use with matchinfo() to calculate the
** relevancy of an FTS match. The value returned is the relevancy score
** (a real value greater than or equal to zero). A larger value indicates
** a more relevant document.
**
** The overall relevancy returned is the sum of the relevancies of each
** column value in the FTS table. The relevancy of a column value is the
** sum of the following for each reportable phrase in the FTS query:
**
** (<hit count> / <global hit count>) * <column weight>
**
** where <hit count> is the number of instances of the phrase in the
** column value of the current row and <global hit count> is the number
** of instances of the phrase in the same column of all rows in the FTS
** table. The <column weight> is a weighting factor assigned to each
** column by the caller (see below).
**
** The first argument to this function must be the return value of the FTS
** matchinfo() function. Following this must be one argument for each column
** of the FTS table containing a numeric weight factor for the corresponding
** column. Example:
**
** CREATE VIRTUAL TABLE documents USING fts3(title, content)
**
** The following query returns the docids of documents that match the full-text
** query <query> sorted from most to least relevant. When calculating
** relevance, query term instances in the 'title' column are given twice the
** weighting of those in the 'content' column.
**
** SELECT docid FROM documents
** WHERE documents MATCH <query>
** ORDER BY rank(matchinfo(documents), 1.0, 0.5) DESC
*/
static void rankfunc(sqlite3_context *pCtx, int nVal, sqlite3_value **apVal){
int *aMatchinfo; /* Return value of matchinfo() */
int nMatchinfo; /* Number of elements in aMatchinfo[] */
int nCol = 0; /* Number of columns in the table */
int nPhrase = 0; /* Number of phrases in the query */
int iPhrase; /* Current phrase */
double score = 0.0; /* Value to return */
assert( sizeof(int)==4 );
/* Check that the number of arguments passed to this function is correct.
** If not, jump to wrong_number_args. Set aMatchinfo to point to the array
** of unsigned integer values returned by FTS function matchinfo. Set
** nPhrase to contain the number of reportable phrases in the users full-text
** query, and nCol to the number of columns in the table. Then check that the
** size of the matchinfo blob is as expected. Return an error if it is not.
*/
if( nVal<1 ) goto wrong_number_args;
aMatchinfo = (unsigned int *)sqlite3_value_blob(apVal[0]);
nMatchinfo = sqlite3_value_bytes(apVal[0]) / sizeof(int);
if( nMatchinfo>=2 ){
nPhrase = aMatchinfo[0];
nCol = aMatchinfo[1];
}
if( nMatchinfo!=(2+3*nCol*nPhrase) ){
sqlite3_result_error(pCtx,
"invalid matchinfo blob passed to function rank()", -1);
return;
}
if( nVal!=(1+nCol) ) goto wrong_number_args;
/* Iterate through each phrase in the users query. */
for(iPhrase=0; iPhrase<nPhrase; iPhrase++){
int iCol;/* Current column */
/* Now iterate through each column in the users query. For each column,
** increment the relevancy score by:
**
** (<hit count> / <global hit count>) * <column weight>
**
** aPhraseinfo[] points to the start of the data for phrase iPhrase. So
** the hit count and global hit counts for each column are found in
** aPhraseinfo[iCol*3] and aPhraseinfo[iCol*3+1], respectively.
*/
int *aPhraseinfo = &aMatchinfo[2 + iPhrase*nCol*3];
for(iCol=0; iCol<nCol; iCol++){
int nHitCount = aPhraseinfo[3*iCol];
int nGlobalHitCount = aPhraseinfo[3*iCol+1];
double weight = sqlite3_value_double(apVal[iCol+1]);
if( nHitCount>0 ){
score += ((double)nHitCount / (double)nGlobalHitCount) * weight;
}
}
}
sqlite3_result_double(pCtx, score);
return;
/* Jump here if the wrong number of arguments are passed to this function */
wrong_number_args:
sqlite3_result_error(pCtx, "wrong number of arguments to function rank()", -1);
}
|