|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
Лучшая особенность SQL (во всех его внедрениях, не только SQLite)
это то, что это декларативный, а не процедурный язык.
Программируя на SQL, вы говорите системе что вы хотите вычислить, а не
как это сделать. Задача выяснения как делегирована подсистеме
планировщика запроса в движке базы данных SQL. Для любого данного SQL-оператора могли бы быть сотни,
тысячи или даже миллионы различных алгоритмов выполнения операции.
Все эти алгоритмы получат правильный ответ, хотя некоторые будут
быстрее, чем другие. Планировщик запроса это
AI,
который пытается выбрать самый быстрый и эффективный алгоритм для
каждого SQL-оператора. Большую часть времени планировщик запроса в SQLite делает хорошую работу.
Однако, планировщику запроса нужны индексы, чтобы работать.
Эти индексы должны обычно добавляться программистами. Редко планировщик
запроса сделает подоптимальный выбор алгоритма.
В тех случаях программисты могут хотеть обеспечить дополнительные намеки,
чтобы помочь планировщику запроса сделать лучшую работу. Этот документ обеспечивает справочную информацию о том, как SQLite
запрашивает планировщик. Программисты могут использовать эту информацию,
чтобы помочь создать лучшие индексы и обеспечить намеки, чтобы помочь
планировщику запроса при необходимости. Дополнительная информация предоставляется
здесь и
здесь. Большинство таблиц в SQLite состоит из ноля или большего количества строк
с уникальным ключом целого числа (rowid
или INTEGER PRIMARY KEY),
сопровождаемый содержанием. Исключение: таблицы
WITHOUT ROWID. Строки логически сохранены в порядке увеличения rowid.
Как пример, эта статья использует таблицу "FruitsForSale",
которая связывает различные фрукты со статусом, где они выращены и их ценой
за единицу товара на рынке. Схема: С некоторыми (произвольными) данными такая таблица могла бы быть логически
сохранена на диске как показано на рисунке 1: В этом примере rowid не последовательны, но их упорядочивают.
SQLite обычно создает начальный rowid и увеличивает на один с каждой
добавленной строкой. Но если строки удалены, промежутки могут появиться в
последовательности. И применение может управлять назначенным rowid при
желании так, чтобы строки были не обязательно вставлены в основании.
Но независимо от того, что происходит, rowid всегда уникальны и идут в
строгом порядке по возрастанию. Предположим, что вы хотите искать цену персиков.
Запрос был бы следующим: Чтобы удовлетворить этот запрос, SQLite читает каждую строку
из таблицы, проверяет, чтобы видеть, имеет ли колонка "fruit" значение
"Peach" и если это так, производит столбец "price" из этой строки.
Процесс иллюстрирован рис. 2.
Этот алгоритм, назван полным сканированием таблицы, так как все
содержание таблицы должно быть прочитано и исследовано, чтобы найти одну
строку. С таблицей из 7 строк полное сканирование таблицы приемлемо, но если
бы таблица содержала 7 миллионов строк, полное сканирование таблицы могло бы
прочитать мегабайты содержания, чтобы найти единственное 8-байтовое число.
По этой причине обычно пытаются избежать полного сканирования таблицы. Одна техника для предотвращения полного сканирования таблицы должна
сделать поиски rowid (или эквивалентного
INTEGER PRIMARY KEY).
Чтобы найти цену персиков, стоило бы запросить запись с rowid 4: Так как информация хранится в таблице в порядке rowid, SQLite
может найти правильную строку, используя двоичный поиск.
Если таблица содержит элементы N, время, требуемое, чтобы искать желаемую
строку, пропорционально logN вместо того, чтобы быть пропорциональным N,
как в полном сканировании таблицы. Если таблица содержит 10 миллионов
элементов, это означает, что запрос будет примерно на N/logN или
приблизительно в миллион раз быстрее. Проблема с поиском информации по rowid состоит в том, что вы, вероятно, не
заботитесь о том, что такое цена на "item 4", вы хотите знать цену персиков.
И таким образом, поиск по rowid не полезен. Чтобы сделать исходный запрос более эффективным, мы можем добавить индекс
на колонке "fruit" таблицы "fruitsforsale": Индекс это другая таблица, подобная оригинальной "fruitsforsale",
но с содержанием (колонка fruit в этом случае), сохраненным
перед rowid и со всеми строками в порядке контента.
Рисунок 4 высказывает логическое мнение индекса Idx1.
Колонка "fruit" это первичный ключ, используемый, чтобы упорядочить элементы
таблицы, "rowid" это вторичный ключ, используемый, чтобы сломать связь, когда
у двух или больше строк есть те же самые "fruit".
В примере rowid должен использоваться в качестве дополнительного параметра
для строк "Orange". Заметьте, что, так как rowid всегда уникален по всем
элементам оригинальной таблицы, составной ключ "fruit", сопровождаемый
"rowid", будет уникален по всем элементам индекса. Этот новый индекс может использоваться, чтобы осуществить более быстрый
алгоритм первоначального запроса "Price of Peaches". Запрос начинается, делая двоичный поиск на индексе Idx1 для записей, у
которых есть fruit='Peach'. SQLite может сделать этот двоичный поиск на
индексе Idx1, но не на оригинальной таблице FruitsForSale, потому что строки
в Idx1 сортированы колонкой "fruit". Найдя строку в индексе Idx1, у которой
есть fruit='Peach', ядро базы данных может извлечь rowid для той строки.
Тогда ядра базы данных делают второй двоичный поиск на оригинальной таблице
FruitsForSale, чтобы найти оригинальную строку с fruit='Peach'.
От строки в таблице FruitsForSale SQLite может тогда извлечь значение
столбца price. Эта процедура иллюстрирована рис. 5. SQLite должен сделать два двоичных поиска, чтобы найти цену персиков,
используя этот способ. Но для таблицы с большим количеством строк, это
намного быстрее, чем выполнение полного сканирования таблицы. В предыдущем запросе ограничение fruit='Peach'
сузило результат к единственной стрке.
Но та же самая техника работает, даже если получены многократные строки.
Предположим, что мы искали цену апельсинов вместо персиков: В этом случае SQLite все еще делает единственный двоичный поиск, чтобы
найти первый вход индекса, где fruit='Orange'.
Тогда это извлекает rowid из индекса, использует для поиска оригинальной
записи таблицы через двоичный поиск и производит цену от оригинальной
таблицы. Но вместо ухода ядро базы данных тогда продвигается к следующей
строке индекса, чтобы повторить процесс для следующей записи fruit='Orange'.
Продвижение к следующей строке индекса (или таблицы) намного менее
дорогостоящее, чем выполнение двоичного поиска, так как следующая строка
часто располагается на той же самой странице базы данных как текущая строка.
На самом деле стоимость продвижения к следующей строке
столь дешевая по сравнению с двоичным поиском, что мы обычно игнорируем ее.
Таким образом, наша оценка для общей стоимости этого запроса:
3 двоичных поиска. Если количество строк вывода
K, и количество строк в таблице N, то в целом стоимость выполнения запроса
пропорциональна (K+1)*logN. Затем предположите, что вы хотите искать цену не только любые
апельсины, а на определенно выращенные Калифорнией апельсины.
Соответствующий запрос был бы следующим: Один подход к этому запросу должен использовать термин fruit='Orange' в
WHERE, чтобы найти все строки, имеющие дело с апельсинами, затем
отфильтровать те строки, отклонив любые, которые имеют states не California.
Этот процесс показывает рис. 7.
Это совершенно разумный подход в большинстве случаев. Да, ядро базы данных
действительно должно было сделать дополнительный двоичный поиск строки с
апельсинами из Флориды, который был позже отклонен, таким образом, это не
было столь эффективно, как мы могли бы надеяться, хотя для многих
приложений это достаточно эффективно. Предположим, что в дополнение к индексу на "fruit"
был также индекс на "state". Индекс "state" действует точно так же, как индекс "fruit", в котором это
новая таблица с дополнительным столбцом перед rowid и отсортированная тем
дополнительным столбцом как первичным ключом.
Единственная разница в том, что в Idx2 первая колонка "state" вместо
"fruit", как в Idx1. В нашем наборе данных в качестве примера в "state"
есть больше избыточности и таким образом больше двойных записей.
Связи все еще решены, используя rowid. Используя новый индекс Idx2 на "state", у SQLite
есть другая возможность для поиска цены калифорнийских апельсинов: это
может искать каждую строку, которая содержит фрукты из Калифорнии, и
отфильтровать те строки, которые не являются апельсинами. Используя Idx2 вместо Idx1, SQLite будет
исследовать различный набор строк, но это получает тот же самый ответ в конце
(это очень важно: помните, что индексы никогда не должны изменять ответ,
только помочь SQLite добраться до ответа быстрее)
и это делает тот же самый объем работы. Таким образом, индекс Idx2 не помог
работе в этом случае. Последние два запроса занимают то же самое количество времени в нашем
примере. Таким образом, какой индекс, Idx1 или Idx2, будет выбирать SQLite?
Если командой ANALYZE
управляли на базе данных, так, чтобы у SQLite была возможность собрать
статистику вокруг доступных индексов, то SQLite будет знать, что индекс Idx1
обычно сужает поиск к единственному пункту (наш пример fruit='Orange'
является исключением из этого правила), тогда как индекс Idx2 будет обычно
сужать поиск только к двум строкам. Так, если все остальное будет равно,
SQLite выберет Idx1 с надеждой на сужение поиска к максимально маленькому
числу строк. Этот выбор возможен только из-за статистики, обеспеченной
ANALYZE, если
ANALYZE не управляли, тогда выбор, который
индекс использовать произволен. Чтобы вытащить максимальную производительность из запроса с
многочисленными условиями AND в WHERE,
вы действительно хотите многостолбцовый индекс с колонками для каждого из
условий AND. В этом случае мы создаем новый индекс на столбцах
"fruit" и "state" в FruitsForSale: Многостолбцовый индекс следует за тем же самым образцом, как индекс
отдельного столбца: индексированные столбцы добавляются перед rowid.
Единственная разница в том, что теперь многочисленные колонки добавляются.
Крайний левый столбец это первичный ключ, используемый для порядка строк в
индексе. Вторая колонка используется, чтобы
связывать крайний левый столбец. Если бы была третья колонка, она
использовалась бы, чтобы сломать связи для первых двух колонок.
И т. д. для всех колонок в индексе. Поскольку rowid, как гарантируют, будет
уникален, каждая строка индекса будет уникальна, даже если все колонки
содержания для двух строк будут тем же самым.
Такого случая не происходит в наших типовых данных, но есть один случай
(fruit='Orange'), где есть связь на первой колонке, которая должна быть
сломана второй колонкой. Учитывая новый многостолбцовый индекс Idx3, для SQLite теперь возможно
найти цену калифорнийских апельсинов, используя только 2 двоичных поиска: С индексом Idx3 на обеих колонках, которые ограничиваются оператором
Where, SQLite может сделать единственный двоичный поиск против Idx3, чтобы
найти один rowid для калифорнийских апельсинов,
затем сделать единственный двоичный поиск, чтобы найти цену за тот пункт в
оригинальной таблице. Нет никаких тупиков и никаких потраченных впустую
двоичных поисков. Это более эффективный запрос. Обратите внимание на то, что Idx3 содержит ту же информацию,
как оригинальный Idx1. И поэтому если у нас есть Idx3,
нам действительно больше не нужен Idx1. Запрос "price of peaches"
может быть удовлетворена, используя Idx3, просто игнорируя столбец
"state" в Idx3: Следовательно, хорошее эмпирическое правило:
ваша схема базы данных никогда не должна содержать два индекса, где один
индекс это префикс другого. Пропустите индекс с меньшим количеством колонок.
SQLite все еще будет в состоянии сделать эффективные поиски с
более длинным индексом. Запрос "price of California oranges" был сделан более эффективным с
помощью двух индексов столбца. Но SQLite может сделать еще лучше с тремя
индексами столбца, которые также включают столбец "price": Этот новый индекс содержит все колонки оригинальной таблицы FruitsForSale,
которые используются запросом: критерии поиска и вывод.
Мы называем это "покрывающим индексом". Поскольку вся необходимая
информация находится в покрывающем индексе, SQLite никогда не должен
консультироваться с оригинальной таблицей, чтобы найти цену. Следовательно, добавляя дополнительные колонки "output"
в конец индекса, можно избежать необходимости сослаться на оригинальную
таблицу и таким образом сократить количество двоичных поисков запроса вдвое.
Это улучшение постоянного множителя работы (примерно удвоение скорости).
Но с другой стороны, это также просто обработка:
двойное исполнительное увеличение не почти столь же существенное, как один
миллион увеличений, замеченных, когда таблица была сначала проиндексирована.
И для большинства запросов, вряд ли будет замечено различие
между 1 микросекундой и 2 микросекундами. Многостолбцовые индексы работают только, если ограничительные условия в
операторе Where запроса связаны AND. Таким образом, Idx3 и Idx4 полезны,
когда идет поиск для пунктов, которые являются оба апельсинами и выращены в
Калифорнии, но никакой индекс не был бы настолько полезен, если бы мы хотели
все пункты, которые были апельсинами или выращены в Калифорнии. Когда работаем с OR-условиями в WHERE, SQLite
исследует каждый термин OR отдельно и пытается использовать индекс, чтобы
найти rowid, связанные с каждым термином.
Это тогда берет союз получающихся наборов rowid, чтобы найти конечный
результат. Следующее иллюстрирует этот процесс: Диаграмма выше подразумевает, что SQLite вычисляет все rowid
сначала и затем объединяет их с операцией объединения прежде, чем
начать делать rowid-поиски на оригинальной таблице.
В действительности rowid поиски вкраплены rowid вычислениями.
SQLite использует один индекс за один раз, чтобы найти rowid,
помня, какой rowid это видело прежде, чтобы избежать дубликатов. Для метода OR UNION, показанного выше, чтобы быть полезным, должен быть
доступный индекс, который помогает решить каждый OR-термин в WHERE.
Если бы даже единственный OR-термин не внесен в указатель, то полное
сканирование таблицы должно было бы быть сделано, чтобы найти
rowid, произведенные одним термином, и если SQLite должен сделать полное
сканирование таблицы, он мог бы также сделать это на оригинальной таблице и
получить все результаты в единственном проходе,
не имея необходимость связываться с операциями объединения и
последующими двоичными поисками. Каждый видит, как метод OR UNION мог также быть усилен,
чтобы использовать многократные индексы на запросах, где у оператора Where
есть условия, связанные AND, при помощи оператора пересечения
вместо союза. Много систем базы данных SQL сделают просто это. Но увеличение
производительности от использования единственного индекса небольшое и таким
образом, SQLite не осуществляет эту технику сейчас. Однако, будущая версия
SQLite могла бы быть увеличена, чтобы поддержать AND-by-INTERSECT. SQLite (как все другие движки базы данных SQL) может также использовать
индексы, чтобы удовлетворить пункты ORDER BY в запросе, в дополнение к
ускорению поиска. Другими словами, индексы могут использоваться, чтобы
ускорить сортировку, а также поиск. Когда никакие соответствующие индексы не доступны, запрос с пунктом ORDER
BY должен быть сортирован как отдельный шаг. Рассмотрите этот запрос: SQLite обрабатывает это, собирая весь вывод запроса и затем
выполняя вывод через сортировщика. Если количество строк вывода K, то время сортировки
пропорционально KlogK. Если K маленький, время сортировки обычно
не фактор, но в большом запросе, как вышеупомянутый,
где K = N, время сортировки может быть намного больше, чем время, чтобы
сделать полное сканирование таблицы.
Кроме того, вывод накоплен во временном хранении (который мог бы быть в
оперативной памяти или на диске, в зависимости от различного времени
компиляции и параметров настройки во время выполнения), это
может означать, что много временного хранения требуется,
чтобы заканчивать запрос. Поскольку сортировка может быть дорогой, SQLite упорно работает, чтобы
игнорировать пункты ORDER BY. Если SQLite решит, что вывод естественно
появится в определенном порядке, то никакая сортировка не сделана.
Так, например, если вы будете просить вывод
в порядке rowid, никакая сортировка не будет сделана: Можно также просить сортировку обратного порядка: SQLite все еще опустит шаг сортировки. Но для вывода, чтобы появиться в
правильном порядке, SQLite сделает сканирование таблицы, начинающееся в конце
и работающее к началу, вместо того, чтобы начаться вначале и работать к концу
как показано на рис. 17. Конечно, порядок вывода запроса rowid редко полезен.
Обычно каждый хочет упорядочить вывод некоторой другой колонкой. Если индекс доступен на колонке ORDER BY, тот индекс может использоваться
для сортировки. Считайте запрос обо всех пунктах сортированным по "fruit": Индекс Idx1 просматривается сверху донизу (или от основания до вершины,
если использовано "ORDER BY fruit DESC"), чтобы найти rowid для каждого
пункта в порядке fruit. Тогда для каждого rowid, двоичный поиск сделан
и выведена нужная строка. Таким образом вывод появляется в требуемом порядке
без потребности собрать весь вывод и сортировать его,
используя отдельный шаг. Но это действительно экономит время? Количество шагов в
оригинальной сортировке
пропорционально NlogN, именно так много времени это берет для сортировки N
строк. Но когда мы используем Idx1 как показано здесь, мы должны сделать
поисков rowid, которые занимают logN время каждый, таким образом, полное
время NlogN, то же самое! SQLite использует планировщика запроса на основе издержек.
Когда есть два или больше способа решить тот же самый запрос, SQLite пытается
оценить общую сумму времени на запрос, используя каждый план, а затем
использует план с самой низкой предполагаемой стоимостью.
Стоимость вычисляется главным образом с предполагаемого времени, и таким
образом, этот случай мог пойти так или иначе в зависимости от размера
таблицы, ограничений оператора Where и т. д. Но вообще говоря, индексируемая
сортировка была бы, вероятно, выбрана потому, что это не должно накапливать
весь набор результатов во временном хранении прежде, чем сортировать, и таким
образом использует намного меньше временного хранения. Если закрывающий индекс может использоваться для запроса, то многократных
rowid поисков можно избежать, и стоимость запроса понижается существенно. С закрывающим индексом SQLite может просто идти по
индексу от одного конца до другого и обеспечить вывод за
время, пропорциональное N, без наличия большого буфера, чтобы
держать набор результатов. Предыдущее обсуждение рассматривало поиск и сортировку как отдельные темы.
Но на практике, часто имеет место, что надо искать и сортировать в то же
время. К счастью, возможно сделать это с
использованием единственного индекса. Предположим, что мы хотим найти цены всех видов апельсинов,
отсортированные в порядке места, где они выращены. Запрос: Запрос содержит ограничение поиска в операторе Where и порядок сортировки
в пункте ORDER BY. Поиск и сортировка могут быть достигнуты в то же время,
используя Idx3 с двумя индексами столбца. Запрос делает двоичный поиск на индексе, чтобы найти подмножество строк, у
которых есть fruit='Orange'. Поскольку фруктовая колонка это крайний левый
столбец индекса, и строки индекса находятся в сортированном порядке, все
такие строки будут смежными. Тогда это просматривает соответствующие строки
индекса сверху донизу, чтобы получить rowid
для оригинальной таблицы, а для каждого rowid делает двоичный поиск на
оригинальной таблице, чтобы найти цену. Вы заметите, что нет никакого блока сортировки
нигде на вышеупомянутой диаграмме. Пункт ORDER BY запроса исчез.
Никакая сортировка не должна быть сделана здесь, потому что порядок вывода
определен колонкой state, а она также, оказывается, первая колонка после
фруктовой колонки в индексе. Так, если мы просмотрим записи индекса, у
которых есть та же самая стоимость для фруктовой колонки сверху донизу, те
элементы индекса, как гарантируют, будут упорядочены колонкой state. Закрывающий индекс может также
использоваться, чтобы искать и сортировать в то же время.
Рассмотрите следующее: Как прежде, SQLite делает единственный двоичный поиск диапазона строк в
покрывающем индексе, которые удовлетворяют оператор Where, просмотры, которые
располагаются сверху донизу, чтобы получить желаемые результаты.
Строки, которые удовлетворяют оператор Where, как гарантируют, будут
смежными, так как оператор WHERE это
ограничение равенства на крайний левый столбец индекса.
Просматривая соответствующие строки индекса сверху донизу, вывод, как
гарантируют, будет упорядочен state, так как колонка state
следующая колонка направо от fruit.
И таким образом, получающийся запрос очень эффективен. SQLite может потянуть подобную уловку для сортировки по
убыванию ORDER BY: Тот же самый основной алгоритм сопровождается, кроме того, соответствующие
строки индекса просматриваются от основания до вершины вместо
сверху донизу, так, чтобы state появились в порядке убывания. Иногда только часть пункта ORDER BY может быть удовлетворена, используя
индексы. Рассмотрите, например, следующий запрос: Если закрывающий индекс будет использоваться для просмотра, столбец
"fruit" появится естественно в правильном порядке, но когда будет две
или больше строки с теми же самыми фруктами, цена не могла бы работать.
Когда это происходит, SQLite делает много маленьких сортировок, по одной
для каждой отличной ценности фруктов, а не одну общую.
Рисунок 22 ниже иллюстрирует понятие. В примере, вместо единственноой сортировки 7 элементов, есть 5 сортировок
одного элемента каждая и 1 сортировка 2 элементов для fruit='Orange'. Преимущества выполнения многих меньших сортировок
вместо единственной общей: Из-за этих преимуществ SQLite всегда пытается сделать частичную
сортировку, используя индекс, даже если полная
сортировка индексом невозможна. Основные принципы, описанные выше, обращаются к обычным таблицам rowid и к
таблицам WITHOUT ROWID.
Единственная разница в том, что колонка rowid, которая служит ключом для
таблиц и появляется как самый правый термин в индексах
заменяется PRIMARY KEY.
 Small. Fast. Reliable.
Small. Fast. Reliable.
Choose any three.
Планирование запроса
Обзор
1. Поиск
1.1. Таблицы без индексов
CREATE TABLE FruitsForSale(Fruit TEXT, State TEXT, Price REAL);

Рис. 1: Логическое расположение таблицы "FruitsForSale"
SELECT price FROM fruitsforsale WHERE fruit='Peach';
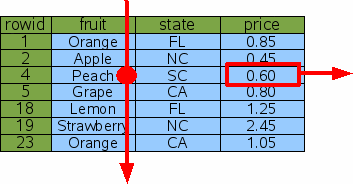
Рис. 2: полное сканирование таблицы1.2. Поиск Rowid
SELECT price FROM fruitsforsale WHERE rowid=4;
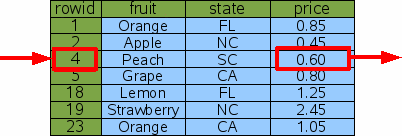
Рис. 3: Поиск Rowid1.3. Поиск индексом
CREATE INDEX Idx1 ON fruitsforsale(fruit);
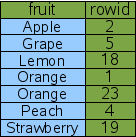
Рис. 4: индекс на столбце Fruit
SELECT price FROM fruitsforsale WHERE fruit='Peach';
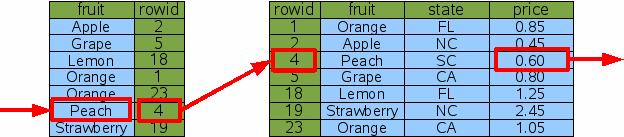
Рис. 5: индексируемый поиск цены персиков1.4.
Многократные строки результата
SELECT price FROM fruitsforsale WHERE fruit='Orange'
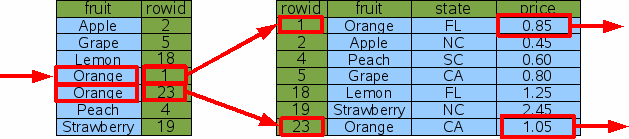
Рис. 6: индексируемый поиск цены апельсинов
1.5. Многочисленные связанные AND термины WHERE
SELECT price FROM fruitsforsale WHERE fruit='Orange' AND state='CA'
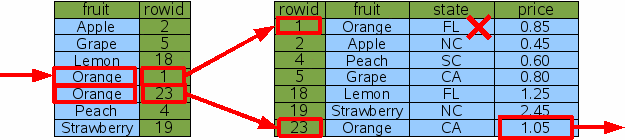
Рис. 7: индексируемый поиск калифорнийских апельсинов
CREATE INDEX Idx2 ON fruitsforsale(state);
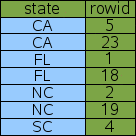
Рис. 8: индекс на столбце State
Рис. 9: индексируемый поиск калифорнийских апельсинов1.6. Многостолбцовые индексы
CREATE INDEX Idx3 ON FruitsForSale(fruit, state);
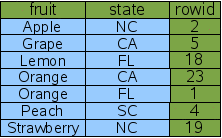
Рис. 10: два индекса столбца
SELECT price FROM fruitsforsale WHERE fruit='Orange' AND state='CA'
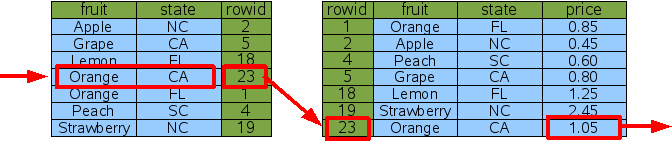
Рис. 11: поиск, используя два индекса столбца
SELECT price FROM fruitsforsale WHERE fruit='Peach'
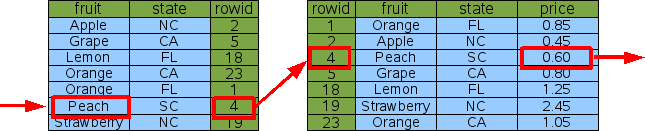
Рис. 12: поиск отдельного столбца на многостолбцовом индексе1.7. Покрытие индексов
CREATE INDEX Idx4 ON FruitsForSale(fruit, state, price);
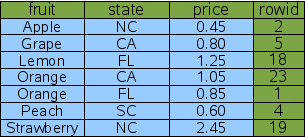
Рис. 13: закрывающий индекс
SELECT price FROM fruitsforsale WHERE fruit='Orange' AND state='CA';
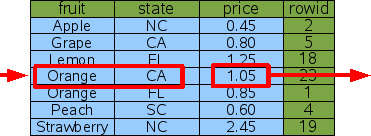
Рис. 14: запрос, используя покрывающий индекс
1.8. OR-связанные термины в WHERE
SELECT price FROM FruitsForSale WHERE fruit='Orange' OR state='CA';
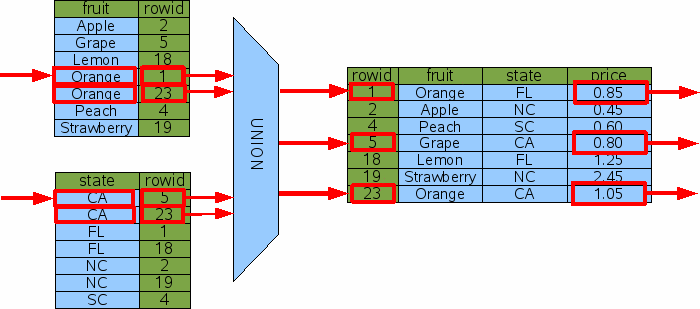
Рис. 15: запрос с ограничениями OR2. Сортировка
SELECT * FROM fruitsforsale ORDER BY fruit;
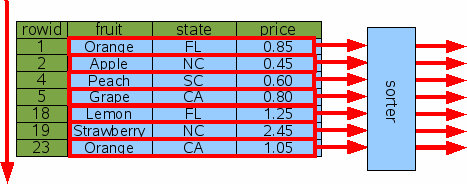
Рис. 16: сортировка без индекса2.1. Сортировка по Rowid
SELECT * FROM fruitsforsale ORDER BY rowid;
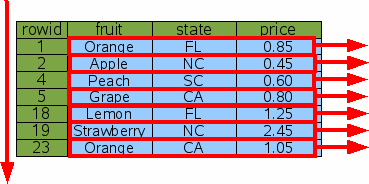
Рис. 17: Сортировка по Rowid
SELECT * FROM fruitsforsale ORDER BY rowid DESC;
2.2. Сортировка индексом
SELECT * FROM fruitsforsale ORDER BY fruit;
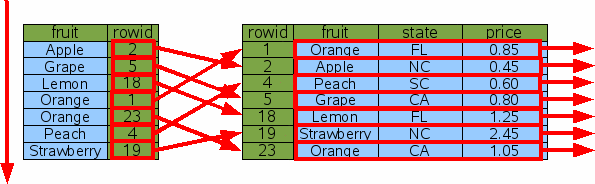
Рис. 18: сортировка с индексом
2.3. Сортировка, покрывая индекс
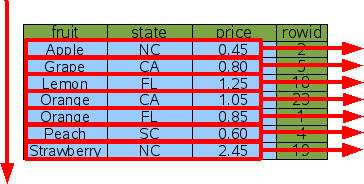
Рис. 19: сортировка с закрывающим индексом
3. Поиск и сортировка в то же время
3.1. Поиск и сортировка с многостолбцовым индексом
SELECT price FROM fruitforsale WHERE fruit='Orange' ORDER BY state
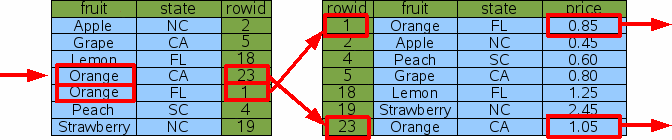
Рис. 20: поиск и сортировка многостолбцовым индексом
3.2. Поиск и сортировка с закрывающим индексом
SELECT * FROM fruitforsale WHERE fruit='Orange' ORDER BY state
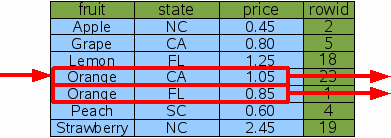
Рис. 21: поиск и сортировка, покрывая индекс
SELECT * FROM fruitforsale WHERE fruit='Orange' ORDER BY state DESC
3.3. Частичная сортировка, используя индекс
(иначе блочная сортировка)
SELECT * FROM fruitforsale ORDER BY fruit, price
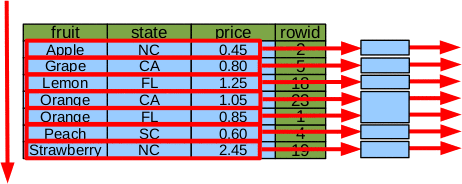
Рис. 22: частичная сортировка индексом4. Таблицы WITHOUT ROWID