|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
Граф ниже показывает количество циклов CPU, используемых SQLite на
стандартной рабочей нагрузке для версий SQLite давностью около 10 лет.
Последние версии SQLite используют приблизительно одну треть циклов
CPU по сравнению с более старыми версиями. Эта статья описывает, как разработчики SQLite измеряют использование CPU,
что те измерения на самом деле означают, и методы, используемые
разработчиками SQLite, чтобы далее уменьшить использование
CPU библиотекой SQLite. Короче говоря, производительность ЦП в SQLite
измерена следующим образом: Для исполнительного измерения SQLite собран приблизительно тем же самым
способом, как это было бы для использования в производственных системах.
Конфигурация времени компиляции "приблизительна" в том смысле, что
каждое производственное использование SQLite отличается.
Вариантами времени компиляции, используемыми одной системой, является не
обязательно те же самые, которые используются другими.
Ключевой пункт в том, что избегают вариантов, которые значительно влияют на
произведенный машинный код. Например, -DSQLITE_DEBUG
опущен, потому что тот выбор вставляет тысячи assert()
посреди работы критической части библиотеки SQLite. Опция -pg (в GCC)
опущена, потому что это заставляет компилятор создать дополнительный
вероятностный исполнительный код измерения, который вмешивается в
фактические исполнительные измерения. Для исполнительных измерений -Os используется (оптимизируйте для размера),
а не -O2, потому что -O2 создает такой код, что трудно связать определенные
инструкции CPU со строками исходного кода C. "Типичная" рабочая нагрузка произведена
speedtest1.c
в каноническом исходном дереве SQLite. Эта программа стремится осуществить
библиотеку SQLite способом, которая типична для реальных приложений.
Конечно, каждое применение отличается, и таким образом, никакая тестовая
программа не может точно отразить поведение всех запросов. speedtest1.c время от времени обновляется как понимание разработчиков
SQLite того, что составляет "типичное" использование. Скрипт
speed-check.sh, также в каноническом исходном дереве, используется,
чтобы управлять speedtest1.c. Чтобы копировать исполнительные измерения,
соберите следующие файлы в единственный каталог: Теперь выполните "sh speed-check.sh trunk". Cachegrind
используется, чтобы измерить уровень, потому что это дает ответы, которые
повторяемы до 7 или больше значащих цифр. В сравнении фактическое время
выполнения едва повторяемо вне одной значащей цифры.
Высокая воспроизводимость cachegrind позволяет разработчикам SQLite
осуществлять и измерять "микрооптимизацию".
Микрооптимизация это изменение кода, которое приводит к очень маленькому
исполнительному увеличению. Типичная микрооптимизация сокращает количество
циклов CPU на 0.1%, 0.05% или еще меньше.
Такие улучшения невозможно измерить с реальным временем. Но сотни или тысячи
микрооптимизации складываются, приводя к измеримому
реальному увеличению производительности. Поскольку разработчики SQLite редактируют исходный код SQLite, они
управляют скриптом оболочки
speed-check.sh,
чтобы отследить исполнительное воздействие изменений. Этот скрипт собирает
speedtest1.c, управляет ею под cachegrind, обрабатывает вывод cachegrind
через TCL-скрипт
cg_anno.tcl, затем пишет результаты в серии текстовых файлов.
Типичный вывод speed-check.sh: Важные части (части, на которые разработчики обращают большую часть
внимания) отображены красным. В основном разработчики хотят знать размер
собранной библиотеки SQLite и сколько циклов CPU было необходимо,
чтобы управлять тестом производительности. Вывод скрипта
cg_anno.tcl показывает количество циклов CPU, потраченных на каждую
строку кода. Отчет приблизительно в 80000 строк длиной.
Следующее это краткий отрывок, взятый из середины отчета, чтобы показать то,
на что это похоже: Числа слева это счетчик циклов CPU для конкретной строки. Скрипт cg_anno.tcl удаляет посторонние детали из аннотации вывода
cachegrind так, чтобы отчеты before-after могли быть сравнены, используя
side-by-side diff, чтобы посмотреть определенные детали того, как попытка
микрооптимизации затронула работу. Использование стандартизированной рабочей нагрузки speedtest1.c
и cachegrind позволило значительно повысить производительность.
Однако, важно признать ограничения этого подхода: Исполнительные измерения сделаны с единственным компилятором
(gcc 5.4.0), урегулированием оптимизации (-Os) и на единой платформе
(Ubuntu 16.04 LTS x64).
Исполнение других компиляторов и процессоров может измениться. Рабочая нагрузка speedtest1.c, которая измеряется, пытается быть
представительной для широкого спектра типичного использования SQLite.
Но каждое применение отличается. Рабочая нагрузка speedtest1.c
не могла бы быть хорошим полномочием для видов действий, выполненных
некоторыми запросами. Разработчики SQLite постоянно работают, чтобы улучшить
программу speedtest1.c, сделать ее лучше для фактического использования
SQLite. Обратная связь сообщества одобрена. Графы цикла, предоставленные cachegrind, являются хорошей
иллюстрацией для фактической работы, но они не на 100% точны. Только количество цикла CPU измеряется здесь. Графы цикла CPU это
хорошая иллюстрация для потребления энергии, но не делают необходимого
коррелята с реальным временем.
Время, проведенное, делая I/O, не отражено в количестве циклов CPU,
а именно время I/O преобладает во многих сценариях использования SQLite.
 Small. Fast. Reliable.
Small. Fast. Reliable.
Choose any three.
Измерение и сокращение использования CPU в SQLite
1. Обзор
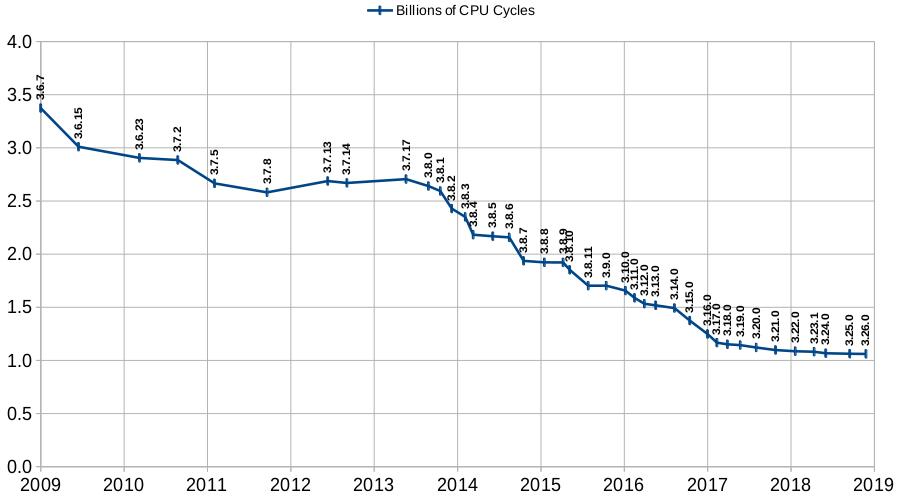
Измеренное использование cachegrind в Ubuntu 16.04 x64 с gcc 5.4.0 и -Os.
2. Измерение уровня
2.1. Опции компиляции
2.2. Рабочая нагрузка
2.3.
Исполнительное измерение
2.4. Микрооптимизация
3.
Исполнительный технологический процесс измерения
==8683==
==8683== I refs: 1,060,925,768
==8683== I1 misses: 23,731,246
==8683== LLi misses: 5,176
==8683== I1 miss rate: 2.24%
==8683== LLi miss rate: 0.00%
==8683==
==8683== D refs: 557,686,925 (361,828,925 rd + 195,858,000 wr)
==8683== D1 misses: 5,067,063 ( 3,544,278 rd + 1,522,785 wr)
==8683== LLd misses: 57,958 ( 16,067 rd + 41,891 wr)
==8683== D1 miss rate: 0.9% ( 1.0% + 0.8% )
==8683== LLd miss rate: 0.0% ( 0.0% + 0.0% )
==8683==
==8683== LL refs: 28,798,309 ( 27,275,524 rd + 1,522,785 wr)
==8683== LL misses: 63,134 ( 21,243 rd + 41,891 wr)
==8683== LL miss rate: 0.0% ( 0.0% + 0.0% )
text data bss dec hex filename
523044 8240 1976 533260 8230c sqlite3.o
220507 1007870 7769352 sqlite3.c
. SQLITE_PRIVATE int sqlite3BtreeNext(BtCursor *pCur, int *pRes){
. MemPage *pPage;
. assert( cursorOwnsBtShared(pCur) );
. assert( pRes!=0 );
. assert( *pRes==0 || *pRes==1 );
. assert( pCur->skipNext==0 || pCur->eState!=CURSOR_VALID );
369,648 pCur->info.nSize = 0;
369,648 pCur->curFlags &= ~(BTCF_ValidNKey|BTCF_ValidOvfl);
369,648 *pRes = 0;
739,296 if( pCur->eState!=CURSOR_VALID ) return btreeNext(pCur, pRes);
1,473,580 pPage = pCur->apPage[pCur->iPage];
1,841,975 if( (++pCur->aiIdx[pCur->iPage])>=pPage->nCell ){
4,340 pCur->aiIdx[pCur->iPage]--;
5,593 return btreeNext(pCur, pRes);
. }
728,110 if( pPage->leaf ){
. return SQLITE_OK;
. }else{
3,117 return moveToLeftmost(pCur);
. }
721,876 }
4. Ограничения