|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
Важная особенность транзакционных баз данных это "атомные коммиты".
Это значит, что или все изменения базы данных в единственной транзакции
происходят, или ни одно из них не происходит. С атомным коммитом разные
записи в различные разделы файла базы данных происходят мгновенно и
одновременно. Реальные аппаратные средства преобразовывают в последовательную
форму и пишут, поскольку запись единственного сектора занимает конечное
количество времени. Таким образом, невозможно действительно написать много
различных секторов файла базы данных одновременно и/или мгновенно. У SQLite есть важное свойство, что транзакции атомные, даже если
транзакция прервана катастрофой операционной системы
или перебоем в питании. Эта статья описывает методы, используемые SQLite, чтобы создать
иллюзию атомных коммитов. Информация в этой статье применяется только, когда SQLite работает в
"способе обратной перемотки", или другими словами, когда SQLite не
использует журнал с упреждающей записью.
SQLite все еще поддерживает атомные коммиты, когда регистрация
позволена, но это достигает атомные коммитов иным путем, не так, как здесь
рассмотрено. Подробности см. здесь. Всюду по этой статье мы назовем устройство массового хранения
"диском" даже при том, что устройство массового хранения могло бы
действительно быть флэш-памятью. Мы предполагаем, что диск написан кусками, которые мы называем
"сектором". Невозможно изменить любую часть диска, меньшую, чем
сектор. Чтобы изменить часть диска, меньше сектора, необходимо прочитать
полный сектор, который содержит часть, которую вы хотите изменить, внести
изменение, затем написать полный сектор. На традиционном вращающем диске сектор это
минимальная единица передачи в обоих направлениях.
На флэш-памяти, однако, минимальный размер прочитанного типично намного
меньше, чем минимум записи. SQLite касается только минимума записи,
в рамках этой статьи, когда мы говорим "сектор", мы имеем в виду
минимальное количество данных, которые могут быть
написаны в единственном действии. До версии 3.3.14 SQLite размер сектора 512 байтов был принят во всех
случаях. Был выбор времени компиляции, чтобы изменить это, но код
никогда не проверялся с большим значением. 512-байтовое предположение сектора
казалось разумным, так как до самого последнего времени все дисководы
использовали 512-байтовый сектор внутренне. Однако, недавно были сделаны
усилия, чтобы увеличить размер сектора дисков до 4096 байт.
Также размер сектора для флэш-памяти обычно больше, чем 512 байтов.
По этим причинам у версий после 3.3.14 есть метод в слое интерфейса OS,
который опрашивает основную файловую систему, чтобы найти истинный размер
сектора. Как в настоящее время сделано (версия 3.5.0),
этот метод все еще возвращает 512 байт, так как нет никакого стандартного
способа обнаружить истинный размер сектора на Unix или на Windows.
Но метод доступен для производителей устройств, чтобы применить его, согласно
их собственным потребностям. И мы оставляем открытую возможность заполнения
более значащего внедрения на Unix и Windows в будущем. SQLite традиционно предполагает, что сектор пишется не атомно.
Однако, SQLite действительно всегда предполагает, что сектор пишется линейно.
Под "линейным" мы подразумеваем, что SQLite предполагает, что
записывая сектор, аппаратные средства начинают в одном конце данных и пишут
байт за байтом, пока это не добирается до другого конца.
Запись могла бы пойти с начала до конца или от конца до начала.
Если перебой в питании происходит посреди сектора, могло бы случиться так,
что часть сектора была изменена, но другая часть была оставлена без
изменений. Ключевое предположение SQLite в том, что если какая-либо часть
сектора будет изменена, то первые или последние байты будут изменены.
Таким образом, аппаратные средства никогда не будут начинать писать сектор в
середине. Мы не знаем, верно ли это предположение всегда, но
это кажется разумным. Предыдущий параграф указывает, что SQLite не предполагает, что сектор
пишется атомно. Это верно по умолчанию. Но с версии 3.5.0 SQLite есть новый
интерфейс, названный интерфейсом
Virtual File System (VFS).
VFS единственное, что подразумевает, как
SQLite обращается к основной файловой системе. Код внедрения VFS для Unix и
Windows и есть механизм для создания новых внедрений VFS во время выполнения.
В этом новом интерфейсе VFS есть метод xDeviceCharacteristics.
Этот метод опрашивает основную файловую систему, чтобы обнаружить различные
свойства и поведения, что файловая система может или не может.
Метод xDeviceCharacteristics мог бы указать, что записи сектора атомные
и если это действительно так, SQLite
попытается использовать в своих интересах тот факт. Но по умолчанию
xDeviceCharacteristics для Unix и для Windows не указывает, что запись
сектора атомная и таким образом, эта оптимизация обычно опускается. SQLite предполагает, что операционная система буферизует запись и что
запрос записи возвратится, прежде чем данные на самом деле сохранились в
устройстве. SQLite далее предполагает, что операции записи будут
переупорядочены операционной системой.
Поэтому SQLite делает операцию "fsync" в ключевых пунктах.
SQLite предполагает, что fsync не возвратят ничего, пока все
операции записи для файла, который сбрасывается, не закончены.
Нам говорят, что примитивы fsync
сломаны на некоторых версиях Windows и Linux. Это неудачно.
Это открывает SQLite возможность повреждения БД.
Однако, нет ничего, что SQLite может сделать, чтобы проверить это или
исправить ситуацию. SQLite предполагает, что операционная система
работает так, как описано. SQLite предполагает что, когда файл растет в длину, новое файловое
пространство первоначально содержит мусор и затем заполнено данными.
Другими словами, SQLite предполагает, что размер файла обновляется перед
содержанием файла. Это пессимистическое предположение, и SQLite должен
сделать некоторую дополнительную работу, чтобы удостовериться, что это не
вызывает повреждение БД, если произошел сбой
между временем, когда размер файла увеличен и когда новое содержание
написано. Метод xDeviceCharacteristics VFS
мог бы указать, что файловая система будет всегда писать данные прежде,
чем обновить размер файла. Это свойство SQLITE_IOCAP_SAFE_APPEND
для тех читателей, которые смотрят на код.
Когда метод xDeviceCharacteristics указывает, что содержание файлов написано
прежде, чем размер файла увеличен, SQLite может игнорировать некоторые свои
педантичные шаги по защите базы данных и таким образом
уменьшить дисковый I/O. Текущее внедрение, однако, не делает такие
предположения для VFS в Windows и Unix. SQLite предполагает, что удаление файла атомное с точки зрения
пользовательского процесса. Этим мы подразумеваем, что, если SQLite просит,
чтобы файл был удален, но питание отключилось во время удаления, как только
электроснабжение восстановлено, файл или будет существовать полностью со всем
оригинальным неизменным содержанием, или файл не будет замечен в файловой
системе вообще. Если после того, как электроснабжение восстановлено, файл
только частично удален, если некоторые его данные были изменены или стерты,
или файл был усечен, но не полностью удален, то повреждение БД вероятно. SQLite предполагает, что обнаружение и/или исправление битовых ошибок,
вызванных космическими лучами, тепловыми помехами, квантовыми колебаниями,
ошибками драйвера устройства или другими механизмами, является
ответственностью используемого оборудования и операционной системы.
SQLite не добавляет избыточности к файлу базы данных в целях обнаружения
ошибки I/O. SQLite предполагает, что данные, которые он читает, являются
точно теми же самыми данными, которые он ранее написал. По умолчанию SQLite предполагает, что операционный системный вызов, чтобы
написать диапазон байтов не изменит любые байты за пределами того диапазона,
даже при сбое. Это свойство "powersafe overwrite".
До version 3.7.9 (2011-11-01) SQLite
не предполагал powersafe overwrite.
Но со стандартным размером сектора, увеличивающимся с 512 до 4096 байтов на
большинстве дисководов, стало необходимо предположить, что powersafe
overwrite, чтобы поддержать исторические исполнительные уровни, поэтому
powersafe overwrite предполагается по умолчанию
в последних версиях SQLite. Предположение о powersafe overwrite
может быть отключено во время компиляции или во время выполнения при желании.
Посмотрите описание powersafe overwrite.
Мы начинаем с обзора шагов, которые делает SQLite, чтобы выполнить
атомный коммит для файла единой базы данных. Детали форматов файлов раньше
принимали меры против повреждения от перебоев в питании, и методы для
выполнения атомного коммита во
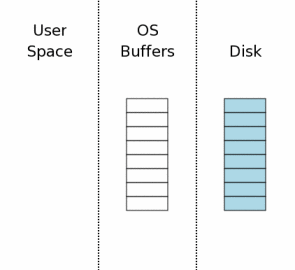
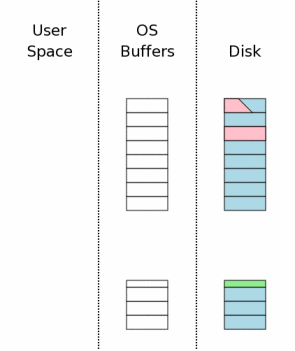
многие базы данных, обсуждены в более поздних секциях. Состояние компьютера, когда соединение с базой данных открыто, показывает
концептуально диаграмма справа. Область диаграммы с крайней правой стороны
(маркирована "Disk") представляет информацию
на устройстве массового хранения. Каждый прямоугольник это сектор.
Синий цвет представляет сектора, которые содержат оригинальные данные.
Средняя область это дисковый кэш операционных систем. В начале нашего примера
он холодный, и это представляется, оставляя прямоугольники дискового кэша
пустыми. Левая область диаграммы показывает содержание памяти для процесса,
который использует SQLite. Соединение с базой данных было просто открыто,
никакая информация еще не была прочитана, таким образом,
пространство пользователя пусто. Прежде чем SQLite может писать в БД, он должен сначала прочитать базу
данных, чтобы видеть то, что уже там.
Даже если это просто прилагает новые данные, SQLite все еще должен
читать схему базы данных из таблицы
"sqlite_schema", чтобы знать, как разобрать
операторы INSERT и обнаружить, где в файле базы данных новая
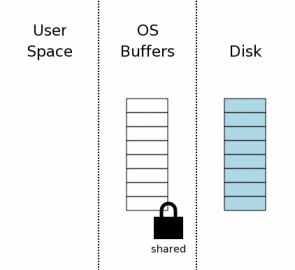
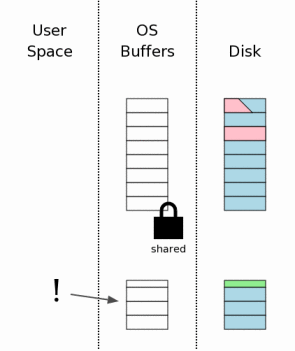
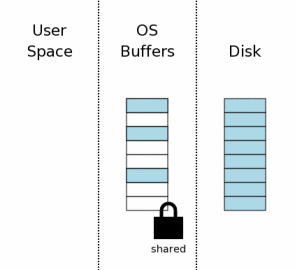
информация должна храниться. Первый шаг к чтению файла базы данных получает коллективную блокировку на
файле базы данных. Блокировка "shared" позволяет двум или больше соединениям
с базой данных читать из файла базы данных в то же время.
Но коллективная блокировка препятствует тому, чтобы другое соединение с базой
данных писало файл базы данных в то время, как мы читаем его.
Это необходимо, потому что, если другое соединение с базой данных писало
файл базы данных в то же время, когда мы читаем файл базы данных, мы могли бы
прочитать некоторые данные перед изменением и другие данные после изменения.
Это заставило бы изменение, внесенное другим процессом, быть не атомным. Заметьте, что коллективная блокировка находится на дисковом кэше
операционной системы, не на самом диске. Блокировки файла обычно
просто флаги в ядре операционной системы.
Детали зависят от определенного интерфейса слоя OS.
Следовательно, блокировка немедленно исчезнет, если операционная система
потерпит крах или если есть потеря питания.
Обычно также имеет место, что блокировка
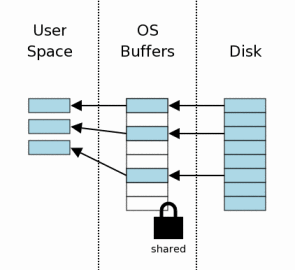
исчезнет, если процесс, который создал ее, завершается. После того, как коллективная блокировка приобретена, мы можем начать
читать информацию от файла базы данных. В этом сценарии мы принимаем холодный
кэш, таким образом, информация должна сначала быть прочитана из массового
хранения в кэш операционной системы, затем передана от кэша
операционной системы в пространство пользователя. Далее некоторая или вся
информация могла бы уже быть найдена в кэше
операционной системы, и поэтому только передача в пространство
пользователя будет требоваться. Обычно только подмножество страниц в файле базы данных прочитано.
В этом примере мы показываем три страницы из восьми прочитанных.
В типовом приложении у базы данных будут тысячи страниц, а запрос будет
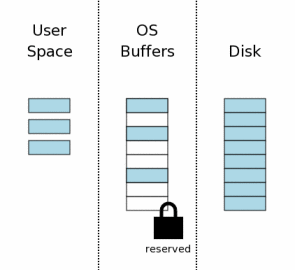
обычно касаться только небольшого процента тех страниц. Прежде, чем внести изменения в базу данных, SQLite сначала получает
"зарезервированную" блокировку на файл базы данных.
Зарезервированная блокировка подобна коллективной блокировке: обе
позволяют другим процессам читать от файла базы данных. Единственная
зарезервированная блокировка может сосуществовать с многократными
коллективными блокировками от других процессов. Однако, может быть только
одна зарезервированная блокировка на файл базы данных.
Следовательно, только единственный процесс может пытаться
писать базу данных. Идея зарезервированной блокировки в том, что она сигнализирует, что
процесс намеревается изменить файл базы данных в ближайшем будущем, но еще не
начал делать модификации. И потому что модификации еще не начались, другие
процессы могут продолжить читать из базы данных. Однако, никакой другой
процесс не должен пытаться писать базу данных. До внесения любых изменений в файл базы данных SQLite сначала создает
отдельный файл журнала обратной перемотки и пишет в журнал обратной перемотки
оригинальное содержание страниц базы данных, которые должны быть изменены.
Идея журнала обратной перемотки состоит в том, что он содержит всю
информацию, чтобы вернуть базу данных назад к ее исходному состоянию. Журнал обратной перемотки содержит маленький заголовок
(отображен зеленым на диаграмме), который делает запись первоначального
размера файла базы данных. Таким образом, если изменение заставит файл базы
данных расти, мы будем все еще знать первоначальный размер базы данных.
Номер страницы сохранен вместе с каждой страницей базы данных, которая
написана в журнал обратной перемотки. Когда новый файл будет создан, большинство настольных операционных систем
(Windows, Linux, Mac OS X) ничего на самом деле не напишет на диск.
Новый файл создается только в дисковом кэше операционных систем.
Файл не создается на диске,
пока у операционной системы не появится свободный момент.
Это создает впечатление пользователям, что I/O происходит намного
быстрее, чем возможно. Мы иллюстрируем эту идею в диаграмме справа,
показывая, что новый журнал обратной перемотки появляется только в дисковом
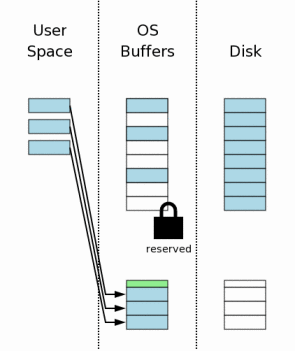
кэше операционной системы, а не на самом диске. После того, как оригинальное содержание страницы было сохранено
в журнале обратной перемотки, страницы могут быть изменены в пользовательской
памяти. У каждого соединения с базой данных есть своя собственная частная
копия пространства пользователя, таким образом, изменения, которые внесены в
пространстве пользователя, видимы только соединению с базой данных, которое
вносит изменения. Другие соединения с базой данных все еще видят информацию в
буферах дискового кэша операционной системы,
которые еще не были изменены. И поэтому даже при том, что один процесс занят,
изменяя базу данных, другие процессы могут продолжить читать свои собственные
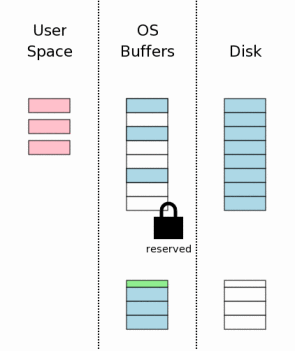
копии оригинального содержания базы данных. Следующий шаг должен сбросить содержание файла журнала обратной перемотки
к энергонезависимой памяти. Как мы будем видеть позже, это критический шаг в
страховании, что база данных может пережить неожиданные потери питания.
Этот шаг также занимает много времени, начиная с записи
памяти, обычно это медленная операция. Этот шаг обычно более сложен, чем простой сброс
журнала обратной перемотки на диск. На большинстве платформ два отдельных
потока (или fsync()) требуются. Первый поток выписывает основное содержание
журнала обратной перемотки. Тогда заголовок журнала обратной перемотки
изменяется, чтобы показать число страниц в журнале обратной перемотки.
Тогда заголовок сбрасывается на диск. Подробная информация о том, почему мы
делаем эту модификацию заголовка и дополнительный сброс
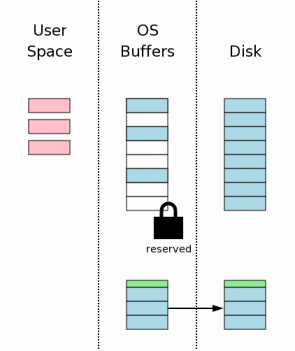
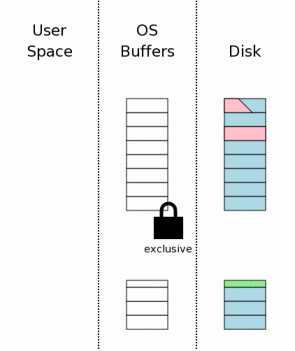
предоставлена в более поздней части этой главы. До внесения изменений в сам файл базы данных мы должны получить
монопольную блокировку на файле базы данных. Получение монопольной блокировки
является двухступенчатым процессом.
Сначала SQLite получает отложенную блокировку. Тогда это наращивает
блокировку до монопольной. Отложенная блокировка позволяет другим процессам, у которых уже есть
коллективная блокировка, продолжить читать файл базы данных.
Но это препятствует тому, чтобы были установлены новые коллективные
блокировки. Идея отложенной блокировки состоит в том, чтобы предотвратить
паузу записи, вызванную большим пулом читателей. Могли бы быть десятки, даже
сотни, других процессов, пытающихся прочитать файл базы данных.
Каждый процесс приобретает коллективную блокировку, прежде чем он начнет
читать, читает то, что ему надо, затем выпускает коллективную блокировку.
Если, однако, есть много различных процессов чтения от той же самой базы
данных, могло бы произойти, что новый процесс всегда приобретает свою
коллективную блокировку, прежде чем предыдущий процесс выпустит свою
коллективную блокировку. Таким образом, никогда нет момента, когда нет
никаких коллективных блокировок на файле базы данных и следовательно никогда
нет возможности захватить монопольную блокировку.
Отложенная блокировка разработана, чтобы предотвратить этот цикл, позволив
существующим коллективным блокировкам продолжиться, но блокируя
новые коллективные блокировки. В конечном счете все коллективные блокировки
очистятся, и отложенная блокировка тогда будет в состоянии
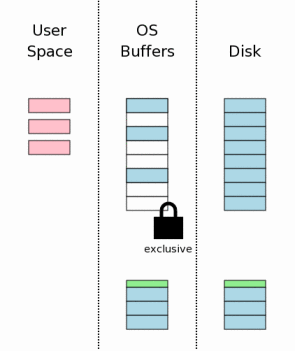
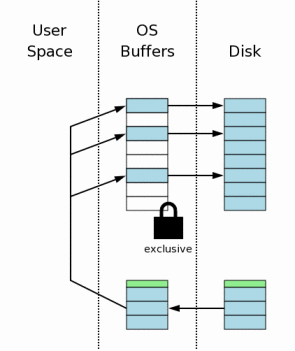
перейти в монопольную блокировку. Как только монопольная блокировка получена, мы знаем, что никакие другие
процессы не читают файл базы данных, и безопасно можно писать изменения в
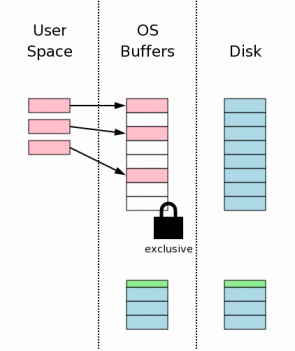
файл базы данных. Обычно эти изменения идут только до дискового
кэша операционных систем. Другой сброс должен произойти, чтобы удостовериться, что
все изменения базы данных записаны в энергонезависимую память.
Это критический шаг, чтобы гарантировать, что база данных переживет потери
питания без повреждения. Однако из-за врожденной медлительности
записи на дисках или флэш-памяти, этот шаг вместе со сбросом
файла журнала обратной перемотки в разделе 3.7 выше занимает большую часть
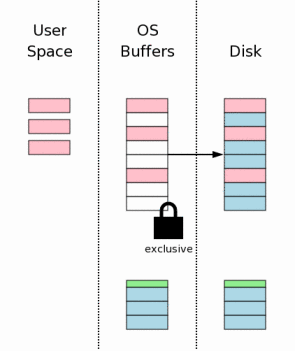
времени, чтобы закончить транзакцию в SQLite. После того, как изменения базы данных сохранены, файл журнала обратной
перемотки удален. Это момент коммита транзакции.
Если катастрофа перебоя в питании или системы происходит до этого пункта, то
процессы восстановления, которые будут описаны позже, приходят к состоянию,
как будто никакие изменения никогда не вносились в файл базы данных.
Если катастрофа перебоя в питании или системы происходит после того, как
журнал обратной перемотки удален, то все будет
как будто все изменения были написаны на диск.
Таким образом SQLite имеет понимание того, внес он или нет изменения в файл
базы данных в зависимости от того, существует ли файл
журнала обратной перемотки. Удаление файла не является действительно атомной операцией, но так
кажется с точки зрения пользовательского процесса.
Процесс всегда в состоянии спросить операционную систему
"этот файл существовует?", и процесс получит ответ. После того, как
перебой в питании, который происходит во время передачи транзакции,
устранен, SQLite спросит операционную систему, существует ли файл журнала
обратной перемотки. Если ответ "да" тогда
транзакция неполная и отменена. Если ответ "нет", это означает, что
транзакция действительно передавалась. Существование транзакции зависит от того, существует ли файл журнала
обратной перемотки, удаление файла атомная операция с точки зрения процесса
пространства пользователя. Поэтому транзакция это атомная операция. Акт удаления файла дорогой на многих системах. Как оптимизация, SQLite
может формироваться, чтобы усечь файл журнала к нулю байт в длину или
переписать заголовок файла журнала нолями.
В любом случае получающийся файл журнала больше не способен к откатыванию
назад и таким образом транзакция все еще передается. Усечение файла к нулевой
длине, как удаление файла предполагается является атомной операцией с точки
зрения пользовательского процесса. Переписывание заголовка журнала нолями не
атомное, но если какая-либо часть заголовка будет повреждена, то журнал не
откатится назад. Следовательно, можно сказать, что передача происходит, как
только заголовок достаточно изменяется, чтобы сделать его некорректным.
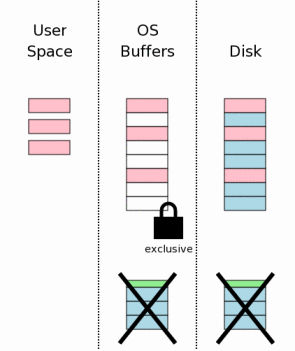
Как правило, это происходит, как только первый байт заголовка обнулен. Последний шаг процесса передачи должен выпустить монопольную блокировку
так, чтобы другие процессы могли получить доступ к файлу базы данных. В диаграмме справа, мы показываем, что информация, которая содержалась в
пространстве пользователя, очищена, когда блокировка снята.
Это раньше было буквально верно для более старых версий SQLite.
Но более свежие версии SQLite хранят информацию пространства пользователя в
памяти в случае, если это могло бы быть необходимо снова в начале следующей
транзакции. Более дешево снова использовать информацию, которая уже находится
в локальной памяти, чем возвратить информацию от дискового кэша операционной
системы или прочитать диск снова.
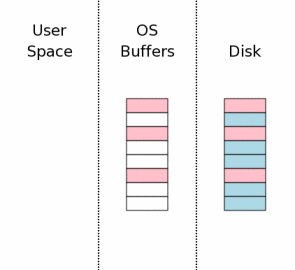
До многократного использования информации в пространстве пользователя мы
должны сначала повторно приобрести коллективную блокировку, затем мы должны
проверить, чтобы удостовериться, что никакой другой процесс не изменил файл
базы данных, в то время как мы не его не блокировали.
Есть счетчик на первой странице базы данных, который увеличена каждый раз,
когда файл базы данных изменяется. Мы можем узнать, изменил ли другой процесс
базу данных, проверив это значение.
Если бы база данных была изменена, то кэш пространства пользователя должен
быть очищен и перечитан. Но обычно имеет место ситуация, когда никакие
изменения не были внесены, и кэш пространства пользователя может
быть снова использован. Атомный коммит, как предполагается, происходит мгновенно.
Но обработка, описанная выше, занимает конечное количество времени.
Предположим, что питание отключилось в ходе описанного выше процесса.
Чтобы поддержать иллюзию, что изменения были мгновенны, мы имеем
"обратную перемотку" любых частичных изменений и вернем базу данных
к состоянию, в котором это было до начала транзакции. Предположим, что потеря питания была во время
шага 3.10,
в то время как изменения базы данных писались на диск.
После того, как электроснабжение восстановлено, ситуация могла бы быть чем-то
как то, что показывают справа. Мы пытались изменить три страницы файла базы
данных, но только одна страница была успешно написана.
Другая страница была частично написана,
третья страница не была написана вообще. Журнал обратной перемотки полон и неповрежден на диске, когда
электроснабжение восстановлено. Это ключевой пункт. Причина операции сброса
на шаге 3.7 в том, чтобы быть абсолютно уверенным,
что весь журнал обратной перемотки безопасно записан в энергонезависимую
память до внесения любых изменений в сам файл базы данных. В первый раз, когда любой процесс SQLite пытается получить доступ к файлу
базы данных, он получает коллективную блокировку, как описано в
разделе 3.2.
Но тогда это замечает, что есть существующий файл журнала обратной перемотки.
SQLite тогда проверяет, является ли журнал обратной перемотки "горячим
журналом". Горячий журнал это журнал обратной перемотки, который должен
быть воспроизведен, чтобы вернуть базу данных к нормальному состоянию.
Горячий журнал существует только, когда более ранний процесс был посреди
совершения транзакции в момент сбоя. Журнал обратной перемотки это
"горячий" журнал, если все следующее верно: Присутствие горячего журнала это наш признак, что предыдущий процесс
пытался передать транзакцию, но это прервалось по некоторым причинам до
завершения. Горячий журнал означает, что файл базы данных находится в
непоследовательном статусеи должен быть
восстановлен (обратной перемоткой). Первый шаг к контакту с горячим журналом должен получить монопольную
блокировку на файле базы данных. Это препятствует тому, чтобы два или больше
процесса пробовали к обратной перемотке тот же самый горячий журнал
в то же время. Как только процесс получает монопольную блокировку, разрешено
писать файл базы данных. Тогда процесс продолжает читать оригинальное
содержание страниц из журнала обратной перемотки и писать это содержание
туда, где это должно быть в файле базы данных.
Вспомните, что заголовок журнала обратной перемотки делает запись
первоначального размера файла базы данных до начала прерванной транзакции.
SQLite использует эту информацию, чтобы усечь файл базы данных назад к его
первоначальному размеру в случаях, когда незавершенная транзакция заставила
базу данных расти. В конце этого шага база данных должна быть того же
размера и содержать ту же самую информацию, как перед
началом прерванной транзакции. После того, как вся информация в журнале обратной перемотки была
воспроизведена в файл базы данных (и сброшена на диск в случае, если мы
сталкиваемся с еще одним перебоем в питании), горячий журнал обратной
перемотки может быть удален. Как в разделе 3.11,
файл журнала мог бы быть усечен к нулевой длине, или заголовок мог быть
переписан нолями как оптимизация на системах, где удаление файла дорогое.
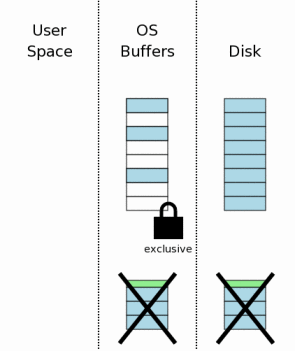
Так или иначе журнал больше не горячий после этого шага. Заключительный шаг восстановления должен уменьшить монопольную блокировку
назад до коллективной блокировки.
Как только это происходит, база данных вернулась в состояние,
в котором это было бы, если бы прерванная транзакция
никогда не начиналась. Так как вся эта деятельность восстановления
происходит полностью автоматически и прозрачно,
программа, использующапя SQLite, ведет себя так, как будто прерванная
транзакция никогда не начиналась. SQLite позволяет
связи единой базы данных, чтобы работать
с двумя или больше файлами базы данных одновременно с помощью
команды ATTACH DATABASE.
Когда многократные файлы базы данных изменяются в единственной
транзакции, все файлы обновляются атомарно. Другими словами, или все файлы
базы данных обновляются, или ни один из них.
Достижение атомной передачи с многократными файлами базы данных более сложно.
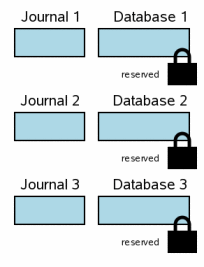
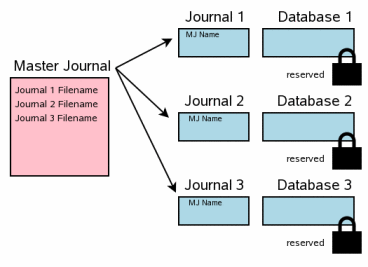
Эта секция описывает как это делается в SQLite. Когда многие файлы базы данных вовлечены в транзакцию, у каждой базы
данных есть свой собственный журнал обратной перемотки, и каждая база данных
блокирована отдельно. Диаграмма показывает сценарий, где три различных файла
базы данных были изменены в одной транзакции.
Ситуация в этом шаге походит на сценарий транзакции с единственным файлом в
шаге 3.6.
У каждого файла базы данных есть зарезервированная блокировка.
Для каждой базы данных оригинальное содержание страниц, которые изменяются,
было написано в журнал обратной перемотки для той базы данных, но содержание
журналов еще не сброшено на диск.
Никакие изменения еще не были внесены в сам файл базы данных, хотя
по-видимому есть изменения, проводимые в пользовательской памяти. Для краткости диаграммы в этой секции упрощены от тех, которые
были раньше. Синий цвет все еще имеет значение оригинального контента, а
розовый все еще показывает новое содержание. Но отдельные страницы в
журнале обратной перемотки и файле базы данных не показываются,
и мы не делаем различие между информацией в кэше
операционной системы и информацией, которая находится на диске.
Все эти факторы все еще применяются в сценарии.
Они просто занимают много пространства в диаграммах, и они не добавляют новой
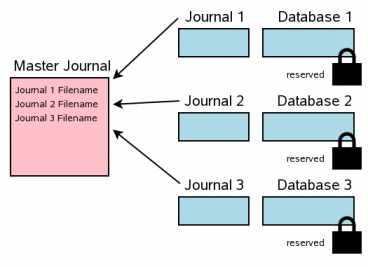
информации, таким образом, они опущены здесь. Следующий шаг в мультифайловом коммите
это создание файла "супержурнала". Название файла супержурнала то
же самое имя, как оригинальное имя файла базы данных (база данных, которая
была открыта, используя интерфейс
sqlite3_open(), а не одна из
ATTACHed БД) с добавленным текстом
"-mjHHHHHHHH", где HHHHHHHH это случайное 32-bit
шестнадцатеричное число. Случайный суффикс HHHHHHHH
изменяется для каждого нового супержурнала. Формула для вычисления имени файла супержурнала, данного в
предыдущем параграфе, соответствует внедрению с версии 3.5.0.
Но эта формула не часть спецификации SQLite и подвержена
изменениям в будущих выпусках. В отличие от журналов обратной перемотки, супержурнал не содержит
оригинального содержания страницы базы данных. Вместо этого супержурнал
содержит полные пути для журналов обратной перемотки для каждой базы данных,
которая участвует в транзакции. После того, как супержурнал построен, его содержание сбрасывается на
диск прежде, чем дальнейшие шаги будут предприняты.
В Unix также синхронизируется каталог, который содержит супержурнал, чтобы
удостовериться, что файл супержурнала появится в нем после сбоя в питании. Цель супержурнала состоит в том, чтобы гарантировать, что транзакции с
несколькими файлами атомные при потере питания.
Но если у файлов базы данных есть другие параметры настройки, которые
ставят под угрозу целостность через событие потери питания (например,
PRAGMA synchronous=OFF или
PRAGMA journal_mode=MEMORY),
тогда создание супержурнала опущено как оптимизация.
Следующий шаг должен сделать запись полного пути файла супержурнала в
заголовке каждого журнала обратной перемотки. Пространство, чтобы хранить
имя файла супержурнала было зарезервировано в начале каждого журнала обратной
перемотки, когда журналы обратной перемотки были созданы. Содержание каждого журнала обратной перемотки сбрасывается на диск
прежде и после того, как имя файла супержурнала будет написано в заголовок
журнала обратной перемотки. Важно сделать оба этих сброса.
К счастью, второй сброс обычно недорог, так как типично только единственная
страница файла журнала (первая страница) изменилась. Этот шаг походит на
шаг 3.7 в
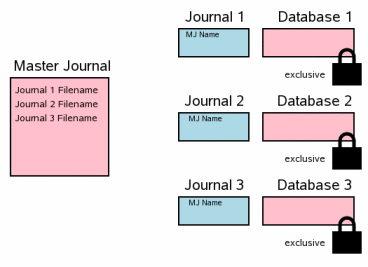
однофайловом сценарии коммита. Как только все файлы журнала обратной перемотки сброшены на диск,
безопасно начать обновлять файлы базы данных. Мы должны получить монопольную
блокировку на всех файлах базы данных прежде, чем писать изменения.
После того, как все изменения записаны, важно сбросить
изменения диска так, чтобы они были сохранены в случае катастрофы
операционной системы или перебоя в питании. Этот шаг соответствует шагам
3.8, 3.9 и
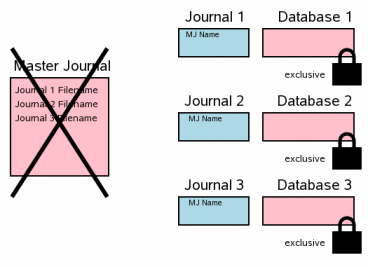
3.10 в однофайловом сценарии коммита. Следующий шаг должен удалить файл супержурнала. Это пункт, где
транзакция передается. Этот шаг соответствует шагу
3.11 в однофайловом сценарии коммита, где
журнал обратной перемотки удален. Если катастрофа перебоя в питании или операционной системы
произойдет в этом пункте, транзакция не будет отменена, когда система
перезагрузится даже при том, что есть существующие журналы обратной
перемотки. Различие: путь супержурнала в заголовке журнала обратной
перемотки. После перезапуска SQLite только полагает, что журнал горячий и
будет воспроизведить журнал только, если не будет никакого имени файла
супержурнала в заголовке (что имеет место для коммита единственного файла)
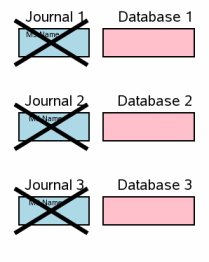
или если файл супержурнала все еще существует на диске. Заключительный шаг в мультифайловом коммите
должен удалить отдельные журналы обратной перемотки и снять
монопольные блокировки на файлах базы данных так, чтобы другие процессы
видели изменения. Это соответствует шагу 3.12. Транзакция уже передана в этом пункте, так что тайминг
не очень важен в удалении журналов обратной перемотки.
Текущее внедрение удаляет единственный журнал обратной перемотки,
затем открывает соответствующий файл базы данных прежде, чем перейти к
следующему журналу обратной перемотки.
Но в будущем мы могли бы изменить это так, чтобы все журналы обратной
перемотки были удалены, прежде чем любые файлы базы данных разблокируются.
Пока журнал обратной перемотки удален, прежде чем соответствующий файл
базы данных разблокируется, не имеет значения, в каком порядке удалены
журналы обратной перемотки, или разблокируются файлы базы данных. Раздел 3.0предоставляет обзор того, как атомный
коммит работает в SQLite. Но это пропускает много важных деталей.
Следующие подразделы попытаются заполнить промежутки. Когда оригинальное содержание страницы базы данных написано в журнал
обратной перемотки (как показано в разделе 3.5),
SQLite всегда пишет полный сектор данных, даже если размер страницы базы
данных меньше, чем размер сектора. Исторически, размер сектора в SQLite был
строго 512 байт и так как минимальный размер страницы также 512 байтов, это
никогда не было проблемой. Но начиная с версии 3.3.14,
для SQLite возможно использовать устройства массового хранения с размером
сектора больше 512 байт. Так, начиная с версии 3.3.14, каждый раз, когда
любая страница в секторе написана в файл журнала, все страницы в том же самом
секторе тоже сохранены. Важно сохранить все страницы сектора в журнале обратной перемотки, чтобы
предотвратить повреждение базы данных после потерь питания при записи.
Предположим, что страницы 1, 2, 3 и 4 сохранены в секторе 1 и что страница 2
изменяется. Чтобы написать изменения страницы 2, используемое оборудование
должно также переписать содержание страниц 1, 3 и 4, так как аппаратные
средства должны написать полный сектор.
Если эта операция записи прервана отключением электроэнергии, одна или больше
страниц 1, 3 или 4 могли бы оказаться с неправильными данными.
Следовательно, чтобы избежать повреждения
базы данных, оригинальное содержание всех тех страниц должно содержаться в
журнале обратной перемотки. Когда данные дописаны в конце журнала обратной перемотки, SQLite обычно
делает пессимистическое предположение, что файл сначала расширен с
недействительными данными и что впоследствии правильные данные заменяют
мусор. Другими словами, SQLite предполагает, что размер файла увеличен
сначала, а затем впоследствии содержание написано в файл.
Если перебой в питании происходит после того, как размер файла был увеличен,
но прежде, чем содержание файла было написано, журнал обратной перемотки
будет содержать не те данные.
Если после того, как электроснабжение восстановлено, другой процесс SQLite
видит, что журнал обратной перемотки содержит неправильные данные
и пытается его откатить в оригинальный файл базы данных,
это могло бы скопировать часть мусора в файл базы данных и таким образом
испортить файл базы данных. SQLite использует две защиты против этой проблемы. Во-первых, SQLite
делает запись числа страниц в журнале обратной перемотки в заголовке журнала
обратной перемотки. Это число первоначально нулевое.
Таким образом во время попытки обратной перемотки неполного (и возможно
ошибочного) журнала обратной перемотки,
процесс, делающий обратную перемотку, будет видеть, что журнал содержит
нулевые страницы и таким образом не внесет изменений в базу данных.
До передачи журнал обратной перемотки сбрасывается на диск, чтобы
гарантировать, что все содержание синхронизировалось
и нет никакого "мусора", оставленного в файле, и только тогда
количество страниц в заголовке изменено от ноля до истинного числа страниц в
журнале обратной перемотки.
Заголовок журнала обратной перемотки всегда сохраняется в отдельном секторе
от любых данных страниц так, чтобы это могло быть переписано и сброшено, не
рискуя повреждением страницы данных, если отключение электроэнергии
происходит. Заметьте, что журнал обратной перемотки сбрасывается дважды:
однажды, чтобы написать содержание страницы и во второй раз, чтобы написать
этот счетчик в заголовке. Предыдущий параграф описывает то, что происходит, когда
прагма синхронизации = "full". По умолчанию это обычно происходит. Однако, если синхронное урегулирование
понижено к "normal", SQLite сбросит журнал обратной перемотки только
однажды, после того, как количество страниц было написано. Это несет риск
повреждения, потому что могло бы произойти, что измененное количество
страниц (отличное от нуля) достигает диска, прежде чем все данные записаны.
Данные будут написаны сначала, но SQLite предполагает, что основная файловая
система может переупорядочить запросы, и что количество страниц
может быть записано сначала даже при том, что запрос записи произошел позже.
Таким образом, как второй оборонительный рубеж, SQLite также использует
32-битную контрольную сумму на каждой странице данных в журнале обратной
перемотки. Эта контрольная сумма оценена для каждой страницы во время
обратной перемотки, откатывая журнал до прежнего уровня, как описано в
разделе 4.4.
Если неправильная контрольная сумма замечена, обратная перемотка оставлена.
Обратите внимание на то, что контрольная сумма не гарантирует, что данные
страницы правильны, так как есть маленькая, но конечная вероятность, что
контрольная сумма могла бы быть правильной, даже если данные повреждены. Обратите внимание на то, что контрольные суммы в журнале обратной
перемотки не необходимы, если синхронное урегулирование FULL.
Мы зависим от контрольных сумм только когда это NORMAL.
Тем не менее контрольные суммы включены в журнал обратной перемотки
независимо от синхронного урегулирования. Процесс, показанный в разделе 3.0,
предполагает, что все изменения базы данных умещаются в памяти, пока их не
надо передать. Но иногда большое изменение будет переполнять
кэш пространства пользователя до передачи транзакции.
В тех случаях кэш должен сбрасываться к базе данных, прежде чем
транзакция будет полной. В начале сброса кэша статус соединения с базой данных
показан в шаге 3.6.
Оригинальное содержание страницы было сохранено в журнале обратной перемотки,
модификации страниц существуют в пользовательской памяти.
Чтобы сбросить кэш, SQLite выполняет шаги с 3.7
по 3.9.
Другими словами, журнал обратной перемотки сбрасывается на диск, монопольная
блокировка получена и изменения написаны в базу данных. Но остающиеся шаги
отсрочены, пока транзакция действительно не передается. Новый заголовок
журнала добавлен к концу журнала обратной перемотки (в его собственном
секторе), и исключительная блокировка базы данных сохраняется, но
прочая обработка возвращается к шагу 3.6.
Когда транзакция передается, или если другой сброс кэша происходит,
повторяются шаги 3.7 и
3.9. Шаг 3.8
пропущен на вторых и последующих проходах, так как исключительная блокировка
базы данных уже проведена из-за первого прохода. Это заставляет блокировку на файле базы данных возрастать от
зарезервированной до исключительной. Это уменьшает параллелизм.
Это также заставляет происходить дополнительные операции fsync,
и эти операции медленные, следовательно сброс кэша
может серьезно уменьшить производительность. По этим причинам его
избегают, когда это возможно. Профилирование указывает, что для большинства систем и при большинстве
обстоятельств SQLite проводит большую часть своего времени, делая дисковый
I/O. Эта секция описывает некоторые методы, используемые SQLite, чтобы
попытаться уменьшить работу с диском, все еще сохраняя атомность. Шаг 3.12
показывает, что, как только коллективная блокировка была снята, от всех
кэшей содержания базы данных пространства пользователя нужно отказаться.
Это сделано, потому что без коллективной блокировки другие процессы
могут изменить содержание файла базы данных и таким образом, любой кэш
пространства пользователя мог бы стать устаревшим.
Следовательно, каждая новая транзакция
началась бы, перечитав данные, которые были ранее прочитаны. Это не настолько
плохо, как это звучит сначала, так как прочитанные данные все еще вероятно в
кэше файла операционных систем. Таким образом, "прочитанной"
является действительно просто копия данных из ядерного пространства в
пространство пользователя. Но несмотря на это, это все еще занимает время. Начиная с SQLite 3.3.14 был добавлен метод, чтобы попытаться уменьшить
бесполезное перечитывание данных. В более новых версиях SQLite сохраняются
данные в кэше страниц пространства пользователя, когда блокировка
на файле базы данных снята.
Позже, после того, как коллективная блокировка приобретена в начале следующей
транзакции, SQLite проверяет, изменил ли какой-либо другой процесс файл базы
данных. Если база данных была изменена в каком-либо случае, после того, как
блокировка была в последний раз снята кэш пространства пользователя стерт.
Но обычно файл базы данных неизменен, и кэш пространства пользователя может
быть сохранен, поэтому можно избежать некоторых ненужных операций чтения. Чтобы определить, изменился ли файл базы данных, SQLite использует
счетчик в заголовке базы данных (в байтах 24-27), который увеличен во время
каждой операции по изменению. SQLite сохраняет копию этого счетчика
до снятия блокировки базы данных. Тогда после приобретения следующей
блокировки базы данных это сравнивает сохраненное значение с текущим и
стирает кэш, если они отличаются, или снова использует кэш,
если они совпадут. SQLite 3.3.14 добавляет концепцию "Exclusive Access Mode".
В способе эксклюзивного доступа SQLite сохраняет исключительную
блокировку базы данных в конце каждой транзакции. Это препятствует тому,
чтобы другие процессы получили доступ к базе данных, но во многих
случаях только единственный процесс использует базу данных, таким образом,
это не серьезная проблема. Преимущество способа эксклюзивного доступа состоит
в том, что дисковый I/O может быть уменьшен тремя способами: Не надо увеличивать счетчик
изменения в заголовке базы данных для транзакций после первой.
Это будет часто экономить запись страницы к журналу обратной перемотки и к
главному файлу базы данных. Никакие другие процессы не могут изменить базу данных, таким
образом, никогда нет потребности проверять счетчик изменения и очистить кэш
пространства пользователя в начале транзакции. Каждая транзакция может быть передана, переписав заголовок журнала
обратной перемотки нолями вместо того, чтобы удалить файл журнала.
Это избегает необходимости изменять запись каталога для файла журнала,
и это избегает необходимости освобождать секторы диска, связанные с журналом.
Кроме того, следующая транзакция перепишет существующее содержание файла
журнала, а не добавит
новое содержание, и на большинстве систем переписывание намного
быстрее, чем добавление. Третья оптимизация, установка в ноль заголовка файла журнала вместо того,
чтобы удалить файл журнала обратной перемотки, не зависит от удерживания
монопольной блокировки в любом случае.
Эта оптимизация может быть установлена независимо от способа
монопольной блокировки, используя
journal_mode pragma,
см. раздел 7.6. Когда информация удалена из базы данных SQLite, страницы, используемые,
чтобы содержать удаленную информацию, добавляются к
"свободному списку".
Последующие вставки снимут страницы из этого списка вместо того, чтобы
расширить файл базы данных. Некоторые свободные страницы содержат критические данные.
Но большинство свободных страниц не содержит ничего полезного.
Эти последние страницы называют страницами "листа".
Мы свободны изменить содержание страниц листа
в базе данных, не изменяя значение базы данных ни в каком случае. Поскольку содержание страниц листа неважно, SQLite избегает хранить
содержание такой страницы в журнале обратной перемотки на шаге
3.5 коммита.
Если страница листа изменяется, и то изменение не отменено
во время восстановления транзакции, база данных не повреждена из-за
упущения. Точно так же содержание новой свободной
страницы никогда не написано в базу данных на шаге
3.9 и не читается из базы данных на шаге
3.3.
Эта оптимизация может значительно уменьшить I/O,
который происходит, внося изменения в файл базы данных, который
содержит свободное пространство. С SQLite 3.5.0, новый интерфейс Virtual File System (VFS)
содержит метод, названный xDeviceCharacteristics, который сообщает
относительно специальных свойств, которые устройство
хранения могло бы иметь. Среди специальных свойств, о которых мог бы сообщить
способность сделать атомную запись сектора. Вспомните, что по умолчанию SQLite предполагает, что записи сектора
линейные, но не атомные. Линейное запись начинается в одном конце сектора и
пишет информацию об изменениях, пока это не добирается до другого конца
сектора. Если сбои происходят посреди записи тогда возможно, что часть
сектора могла бы быть изменена, в то время как другой конец неизменен.
В атомной записи сектора весь сектор переписан или
ничто в секторе не изменяется. Мы полагаем, что самые современные дисководы осуществляют атомную
запись сектора. Когда питание выключено, механизм
использует энергию, сохраненную в конденсаторах и/или угловом моменте диска,
чтобы правильно закончить любую происходящую операцию.
Тем не менее, есть столько слоев между системным вызовом и бортовой
электроникой дисковода, что мы проявляем безопасный подход в Unix и в w32 VFS
и предполагаем, что запись сектора не атомная. С другой стороны,
производители устройств с большим контролем над их файловыми системами могли
бы включить свойство атомной записи в xDeviceCharacteristics, если их
аппаратные средства действительно это делают. Когда сектор пишется атомно, размер страницы базы данных совпадает с
размером сектора и когда есть изменение базы данных, которое касается только
страницы единой базы данных, тогда SQLite пропускает процессы журналирования
и синхронизации и просто пишет измененную страницу непосредственно в файл
базы данных. Счетчик изменения на первой странице файла базы данных
изменяется отдельно, так как никакой вред не причинен, если
питание потеряно, прежде чем счетчик изменения может быть обновлен. Другая оптимизация, введенная в версии 3.5.0 SQLite, использует
"безопасные дополнения" базового диска.
Вспомните, что SQLite предполагает что, когда данные добавлены
к файлу (допустим, к журналу обратной перемотки), размер файла увеличен
сначала, а содержание написано позже.
Таким образом, если питание навернется
после того, как размер файла увеличен, но прежде чем содержание написано,
файл содержит недействительные данные "о мусоре".
Метод xDeviceCharacteristics в VFS мог бы, однако, указать, что
файловая система реализует "безопасные дополнения".
Это означает, что содержание написано, прежде чем размер файла увеличен так,
чтобы для мусора было невозможно попасть в журнал обратной перемотки. Когда безопасные дополнения
обозначаются для файловой системы, SQLite всегда хранит специальное значение
-1 для счетчика страницы в заголовке журнала обратной перемотки.
Это говорит любому процессу, пытающемуся обработать журнал обратной
перемотки, что число страниц в журнале должно быть вычислено из размера
журнала. Значение -1 никогда не изменяется. Так, чтобы, когда передача
происходит, мы сохранили единственную операцию сброса и записали сектор с
первой страницей файла журнала.
Кроме того, когда сброс кэша происходит, мы больше не должны писать новый
заголовок журнала в конце журнала, мы можем просто продолжить добавлять
новые страницы до конца существующего журнала. Удаление файла является дорогой операцией на многих системах.
Таким образом, как оптимизация, SQLite может формироваться, чтобы избежать
операции удаления в разделе 3.11.
Вместо того, чтобы удалить файл журнала, чтобы передать транзакцию, файл
усечен до нуля байт в длину или его заголовок переписан нолями.
Усечение файла к нулевой длине экономит необходимость сделать модификацию
каталога, содержащего файл, так как файл не удален из него.
У переписывания заголовка есть дополнительные плюсы: нет необходимости
обновить длину файла (в "inode" на многих системах) и нет
необходимость иметь дело с недавно освобожденными секторами диска.
Кроме того, в следующей транзакции
журнал будет создан, переписывая существующее содержание вместо того, чтобы
дописать новое содержание в
конец файла, и переписать часто намного быстрее, чем добавление. SQLite может формироваться, чтобы передать транзакции, переписывая
заголовок журнала нолями вместо того, чтобы удалить файл журнала,
устанавливая journal_mode
PRAGMA: Использование постоянного журнала обеспечивает значимое повышение
производительности на многих системах. Конечно, недостаток состоит в том, что
файлы журнала остаются на диске, используя дисковое пространство и
загромождая каталоги еще долго после того, как транзакция закрыта.
Единственный безопасный способ удалить постоянный файл журнала состоит в том,
чтобы передать транзакцию с journaling = DELETE: Остерегайтесь удаления постоянных файлов журнала любыми другими
средствами, так как файл журнала мог бы быть горячим, в этом случае удаление
его испортит соответствующий файл базы данных. Начиная с SQLite 3.6.4
(2008-10-15), также поддерживается режим журнала TRUNCATE: В этом режиме журнала транзакция
передается, усекая файл журнала к нулевой длине вместо того, чтобы удалить
файл журнала (как в режиме DELETE) или установкой заголовка в нули (как в
способе PERSIST). Способ TRUNCATE разделяет преимущество способа PERSIST, что
каталог, который содержит файл журнала и базу данных, не должен быть
обновлен. Следовательно усечение файла часто быстрее, чем удаление его.
У TRUNCATE есть дополнительное преимущество, что это не сопровождается
системным вызовом (например, fsync()), чтобы синхронизировать изменение с
диском. Могло бы быть более безопасно, если бы это было сделано. Но во многих
современных файловых системах, усеченной является атомным и таким образом мы
думаем, что TRUNCATE обычно будет безопасен перед лицом перебоев в питании.
Если вы не уверены в том, будет ли TRUNCATE синхронным и атомным в вашей
файловой системе, и для вас важно, чтобы ваша база данных пережила
сбой во время операции по усечению, то вы могли бы рассмотреть использование
иного режима journaling. Во встроенных системах с синхронными файловыми системами TRUNCATE
приводит к более медленному поведению, чем PERSIST.
Но последующие транзакции медленнее следуют за TRUNCATE, потому что это
быстрее, чтобы переписать существующее содержание, чем дописать
в конец файла. Новые записи файла журнала будут всегда прилагаться после
TRUNCATE, но будут обычно переписывать с PERSIST. Разработчики SQLite уверены, что это надежно
перед лицом перебоев в питании и системных катастроф, потому что
автоматические процедуры тестирования делают обширные проверки способности
SQLite прийти в себя после моделируемых потерь питания.
Мы называем их "краш-тестами". Краш-тесты в SQLite используют измененный VFS, который может моделировать
виды повреждения файловой системы, которые происходят во время катастрофы
потерь питания или сбоя операционной системы. Краш-тест VFS может
моделировать неполный сектор, страницы, заполненные мусором, потому что
запись не закончилась, при изменении порядка во время запуска сценария
тестирования. Краш-тесты выполняют транзакции
много раз, изменяя время, в которое моделируемые потери питания
происходят и свойства причиненного ущерба. Каждый тест тогда вновь открывает
базу данных после моделируемой катастрофы и проверяет, что транзакция
прошла полностью или нет, и что база данных находится в
абсолютно последовательном состоянии. Краш-тесты в SQLite обнаружили много очень тонких ошибок (теперь
исправлены) в механизме восстановления. Некоторые из этих ошибок были
очень неясны и маловероятны. На основе этого опыта разработчики SQLite
уверены, что любая другая система баз данных, которая не использует подобную
систему краш-теста, вероятно, содержит необнаруженные ошибки,
которые приведут к повреждению
базы данных после системной катастрофы или перебоя в питании. Атомные транзакции в SQLite надежны, но ничто не прочно.
Эта секция описывает несколько путей, которыми база данных SQLite могла бы
быть испорчена системной катастрофой или перебоем в питании.
См. также: здесь. SQLite использует блокировки файловой системы, чтобы удостовериться, что
только один процесс и соединение с базой данных пытаются изменить базу данных
за один раз. Механизм захвата файловой системы осуществляется в слое VFS и
отличается для каждой операционной системы. SQLite зависит от этого
внедрения, являющегося правильным. Если что-то идет не так, как надо, и два
или больше процесса в состоянии писать тот же самый файл базы данных в то же
время, серьезное повреждение может произойти. Мы получили сообщения о внедрениях и сетевых файловых системах Windows и
NFS, в котором была тонко сломана блокировка.
Мы не можем проверить эти отчеты, но поскольку в блокировке
трудно разобраться в сетевой файловой системе, у нас нет причины сомневаться
относительно них. Рекомендуется избегать использования SQLite в сетевой
файловой системе, так как работа будет медленной.
Но если необходимо использовать сетевую файловую систему, чтобы хранить файлы
базы данных SQLite, надо рассмотреть использование вторичного механизма
блокировки, чтобы предотвратить одновременную запись
той же самой базы данных, даже если родная файловая система
работает со сбоями. Версии SQLite, которые предварительно установлены в Apple Mac OS X,
содержат версию SQLite, который был расширен, чтобы использовать
альтернативные стратегии блокировки, которые работают со всеми сетевыми
файловыми системами, которые поддерживает Apple. Эти расширения, используемые
Apple, работают отлично, пока все процессы получают доступ к файлу базы
данных таким же образом. К сожалению, механизмы блокировки
не исключают друг друга, поэтому если один процесс получает доступ к файлу,
использующему (например) блокировку AFP и другой процесс (возможно, на иной
машине) использует блокировку
точечного файла, два процесса могли бы столкнуться, потому что AFP
не исключает блокировку точечного файла или наоборот. SQLite использует fsync() в Unix и FlushFileBuffers() в w32, чтобы
синхронизировать буфера файловой системы на диске, как показано в шагах
3.7 и 3.10.
К сожалению, мы получили отчеты, что ни один из этих интерфейсов не работает,
как рекламируется со многими системами. Мы слышим, что
FlushFileBuffers() может быть полностью выключен, используя параметры
настройки реестра на некоторых версиях Windows. Некоторые исторические версии
Linux содержат версии fsync(), которые не работают в некоторых файловых
системах. Даже на системах, где FlushFileBuffers() и fsync(), как говорят,
работают, часто дисковый контроллер IDE говорит, что данные достигли
диска в то время как это все еще проводится только в
изменчивом кэше контроллера. В Mac можно установить прагму: Установка fullfsync в Mac гарантирует, что данные действительно
записаны на диск при сбросе.
Но внедрение fullfsync включает сброс дискового контроллера.
Это также замедляет другой несвязанный дисковый I/O.
Таким образом, его использование не рекомендуется. SQLite предполагает, что удаление файла это атомная операция с точки
зрения пользовательского процесса. Если питание отвалилось
посреди удаления файла, то после того, как электроснабжение восстановлено,
SQLite ожидает видеть или весь файл со всеми его оригинальными
неповрежденными данными, или не найти файл вообще. Файлы базы данных SQLite это
обычные дисковые файлы, которые могут быть открыты и написаны процессами
обычного пользователя. Процесс может открыть базу данных SQLite и
заполнить ее поврежденными данными. Они могли бы также быть введены в базу
данных SQLite ошибками в операционной системе или дисковом контроллере,
особенно часто ошибки вызываются перебоем в питании. Нет ничего, что SQLite
может сделать, чтобы защитить от этих видов проблем. Если сбой действительно происходит, и горячий журнал оставляют на диске,
важно, чтобы оригинальный файл базы данных и горячий журнал остались на диске
с их настоящими именами, пока файл базы данных не открыт другим процессом
SQLite и не приведен в порядок. Во время восстановления в
шаге 4.2 SQLite
определяет местонахождение горячего журнала, ища файл в том же самом
каталоге, где открываемая база данных и чье имя получено из названия
открываемого файла. Если оригинальный файл базы данных или горячий журнал
были перемещены или переименованы, то горячий журнал не будет замечен,
и база данных не будет восстановлена до прежнего уровня. Мы подозреваем, что общий способ неудачи для восстановления SQLite
происходит так: перебой в питании происходит. После того, как
электроснабжение восстановлено, действующий из лучших побуждений пользователь
или системный администратор начинают смотреть, что случилось на диске.
Они видят свой файл базы данных, названный "important.data".
Этот файл, возможно, знаком им. Но после катастрофы, есть также горячий
журнал, названный "important.data-journal".
Пользователь тогда удаляет горячий журнал, думая, что это поможет очистить
систему. Мы не знаем ни о каком способе предотвратить это,
кроме пользовательского образования. Если там будут многократные связи с файлом базы данных, то журнал будет
создан, используя название ссылки, через которую был открыт файл.
Если катастрофа произойдет, и база данных открыта, снова используя
иную связь, горячий журнал не будет найден, и никакая обратная
перемотка не произойдет. Иногда перебой в питании будет заставлять файловую систему быть
испорченной таким образом, что о недавно измененных именах файлов забывают,
и файл перемещен в каталог "/lost+found".
Когда это произойдет, горячий журнал не будет найден, и восстановление
не произойдет. SQLite пытается предотвратить это, открывая и синхронизируя
каталог, содержащий журнал обратной перемотки в то же время, когда он
синхронизирует сам файл журнала. Однако, движение файлов в /lost+found
может быть вызвано несвязанными процессами, создающими несвязанные файлы в
том же самом каталоге, где главный файл базы данных. И так как это вне
контроля SQLite, нет ничего, что SQLite может сделать, чтобы предотвратить
это. Если вы работаете в системе, которая уязвима для этого вида повреждения
пространства имен файловой системы (большинство современных
журналирующих файловых систем неуязвимо, мы верим), тогда вы могли бы
рассмотреть помещение каждого файла базы данных SQLite в его
собственном частном подкаталоге. Время от времени кто-то обнаруживает новый способ грохнуть атомные
транзакции в SQLite, и разработчики должны сделать патч.
Это происходит все реже, и способы неудачи становятся более неясными.
Но все еще было бы глупо предположить, что атомные транзакции
SQLite, совершенно без ошибок. Разработчики стремятся исправлять эти
ошибки так быстро, как могут. Разработчики также пребывают в поисках новых способов оптимизировать
механизм коммитов. Текущие внедрения VFS для Unix (Linux и Mac OS X) и
Windows делают пессимистические предположения о поведении тех систем.
После консультации с экспертами по тому, как эти системы работают, мы могли
бы быть в состоянии ослабить некоторые предположения на этих системах и
позволить им работать быстрее.
В частности мы подозреваем, что самая современная файловая система
понимает атомную запись сектора и безопасное дополнение. Но пока это
неизвестно наверняка, SQLite проявит консервативный
подход и предположит худшее.
 Small. Fast. Reliable.
Small. Fast. Reliable.
Choose any three.
Атомные коммиты в SQLite
1. Введение
2.
Предположения аппаратных средств
3. Однофайловый коммит
3.1. Начальное состояние
3.2. Приобретение блокировки чтения
3.3. Чтение информации из базы данных
3.4. Получение зарезервированной блокировки
3.5. Создание файла журнала обратной перемотки
3.6. Изменение страниц базы данных в пространстве пользователя
3.7. Сброс файла журнала обратной перемотки
3.8. Получение монопольной блокировки
3.9. Запись изменений файла базы данных
3.10. 0 Сброс изменений
3.11. 1 Удаление журнала обратной перемотки
3.12. 2 Снятие блокировки
4. Обратная перемотка
4.1. Когда что-то идет не так, как надо...
4.2.
Горячие журналы обратной перемотки
4.3. Получение монопольной блокировки на базе данных
4.4. Отмена неполных изменений
4.5. Удаление горячего журнала
4.6. Продолжите, как будто незаконченные записи не происходили
5. Многофайловые коммиты
5.1. Отдельные журналы обратной перемотки для каждой базы данных
5.2. Файл супержурнала
5.3. Обновление заголовков журнала обратной перемотки
5.4. Обновление файлов базы данных
5.5. Удаление файла супержурнала
5.6. Очищение журналов обратной перемотки
6. Дополнительные детали процесса
6.1. Всегда журналируются полные сектора
6.2. Контакт с мусором, написанным в файлы журнала
PRAGMA synchronous=FULL;
6.3. Кэширование до передачи
7. Оптимизации
7.1. Кэширование между транзакциями
7.2.
Способ эксклюзивного доступа
7.3. Не журналируйте список пустых страниц
7.4. Единственные обновления страницы и атомная запись сектора
7.5. Файловые системы с безопасным добавлением
7.6. Постоянные журналы обратной перемотки
PRAGMA journal_mode=PERSIST;
PRAGMA journal_mode=DELETE;
BEGIN EXCLUSIVE;
COMMIT;
PRAGMA journal_mode=TRUNCATE;
8. Атомное тестирование передачи
9. Вещи, которые могут пойти не так, как надо
9.1. Неправильные блокировки
9.2. Неполные дисковые сбросы
PRAGMA fullfsync=ON;
9.3. Частичные удаления файла
9.4. Мусор написан в файлы
9.5. Удаление или переименование горячего журнала
10.
Будущие направления и заключение