|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
В этой главе рассматриваются использование NDB Cluster с
MySQL NDB Cluster Connector for Java, также известном как ClusterJ. ClusterJ это API высокого уровня, который подобен в стиле и понятиях
структурам вроде Hibernate и JPA. Поскольку ClusterJ не использует MySQL
Server, чтобы получить доступ к данным в кластере NDB, это может выполнить
некоторые операции намного более быстро, чем можно сделать, используя JDBC.
ClusterJ поддерживает первичный ключ и операции по уникальному ключу,
это не поддерживает операции мультитаблиц, включая соединения. Эта секция предоставляет концептуальный обзор архитектуры API для
использования MySQL NDB Cluster Connector for Java. MySQL NDB Cluster Connector for Java, он же ClusterJ, это Java API
для написания приложений для NDB Cluster. Это один среди различных путей
доступа и стилей доступа к данным в NDB Cluster.
раздел 4.1.2 описывает каждый
API более подробно. MySQL NDB Cluster Connector for Java включен во все исходные тексты и
двоичные пакеты NDB Cluster. Сборка MySQL NDB Cluster Connector for Java из
исходных текстов может быть сделана как часть сборки NDB Cluster,
однако, это может также быть построено с
Maven. NDB Cluster определяется как один или несколько MySQL
Server, обеспечивающих доступ к механизму хранения
JDBC и mysqld.
JDBC работает, посылая SQL-операторы в MySQL Server
и возвращая наборы результатов. Используя JDBC, необходимо написать SQL,
справиться со связью и скопировать любые данные из набора результатов,
которые вы хотите использовать в вашей программе в качестве объектов.
Внедрение JDBC, чаще всего используемое с MySQL Server, это
MySQL Connector/J. Java Persistence API (JPA) и JDBC.
JPA использует JDBC, чтобы соединиться с MySQL Server.
В отличие от JDBC, JPA обеспечивает представление объекта
данных в базе данных.
ClusterJ.
ClusterJ использует мост
JNI NDB API для прямого доступа к
Эти пути показывают в следующей диаграмме стека API: Рис. 4.1. Пути доступа Java к NDB JDBC и mysqld.
Connector/J обеспечивает стандартный доступ через драйвер MySQL JDBC.
Используя Connector/J, приложения JDBC могут быть написаны, чтобы работать с
сервером MySQL, действующим как узел SQL кластера NDB, почти таким же
способом, как другие приложения Connector/J работают с любым другим
случаем MySQL Server. См. раздел 4.2.3. ClusterJ.
ClusterJ это обычный Java Connector для
ClusterJ не должен соединяться с процессом
mysqld, имея прямой доступ
к Эта секция обсуждает ClusterJ API и объектную модель представления
данных, обработанных приложением. Application Programming Interface.
ClusterJ API зависит от 4 главных интерфейсов:
Иентрфейс Session. Весь доступ к данным в кластере NDB сделан в
контексте сессии. Иентрфейс
Нахождение постоянных экземпляров первичным ключом. Создание, обновление и удаление постоянных экземпляров. Получение конструктора запросов (см.
com.mysql.clusterj.query.QueryBuilder). Получение текущей транзакции (см.
com.mysql.clusterj.Transaction). Интерфейс SessionFactory. Сессии получены из
Интерфейс Transaction. Транзакциями не управляет интерфейс
Интерфейс
Интерфейс QueryBuilder. Интерфейс
Модель данных. ClusterJ обеспечивает доступ к данным в кластере
NDB, используя объекты области, подобные во многих отношениях
модели данных JPA. В ClusterJ у отображения объекта области есть следующие особенности: Все таблицы отображают к постоянным интерфейсам. Для каждой
таблицы Однако сами классы не постоянные. Пользователи отображают подмножество колонок к постоянным свойствам в
интерфейсах. Таким образом все свойства отображаются
к колонкам, однако, не все колонки обязательно отображают к свойствам. Все имена свойств ClusterJ по умолчанию имена столбцов.
Интерфейс обеспечивает методы получателя и методы установщика для каждого
значения с предсказуемыми соответствующими именами методов. Аннотации на интерфейсы определяют отображения. Пользовательская точка зрения на среду приложения и объекты области
иллюстрирована в следующей диаграмме, которая показывает логические отношения
среди элементов моделирования интерфейсов ClusterJ: Рис. 4.2. Пользовательская точка зрения ClusterJ на
приложение и окружающую среду Приложение получает экземпляры У каждой сессии есть своя собственная коллекция объектов области, каждый
из которых представляет данные из одной строки в базе данных.
Объекты области могут представлять данные в любом из следующих статусов: Новая, еще не сохранена в базе данных. Получена из от базы данных, доступна приложению. Обновлена, сохранена назад в базу данных. Удалена из базы данных. Эта секция предоставляет основную информацию о сборке и управлении
JAVA-приложениями, используя MySQL NDB Cluster Connector for Java (ClusterJ).
Эта секция обсуждает, как получить ClusterJ. Получение и установка MySQL NDB Cluster Connector for Java.
Можно получить новый выпуск NDB Cluster, который включает ClusterJ, с
downloads.mysql.com. Инструкции по установке, данные в
NDB Cluster Installation также устанавливают ClusterJ. Сборка и установка MySQL
NDB Cluster Connector for Java. Можно собрать и установить ClusterJ как
часть сборки NDB Cluster, которая всегда требует, чтобы вы
настроили сборку, используя опции CMake
Типичная команда CMake для формирования NDB Cluster с поддержкой ClusterJ:
Опция После формирования сборки с CMake выполните
make и
make install
как вы обычно сделали бы, чтобы собрать и установить программное
обеспечение NDB Cluster. Файлы jar MySQL NDB Cluster Connector for Java.
После установки эти файлы jar ClusterJ могут быть найдены в папке
Исходные файлы для ClusterJ формируются как проекты Maven,
позволяя легкую компиляцию и установку, используя Maven. Предположим, что
вы уже собрали и поставили NDB Cluster и ClusterJ,
согласно инструкциям выше. Тогда надо: Добавьте путь к файлу для папки, которая содержит
библиотеку клиента NDB ( Пойдите в каталог сборки, который вы создали, собирая кластер NDB
( Это устанавливает Установите ClusterJ с Maven выполнением
mvn install в каталоге
Это заставляет ClusterJ быть построенным с файлами
Можно пропустить тесты, которые происходят в конце процесса установки,
добавляя опцию Это препятствует тому, чтобы ваша установка терпела неудачу, потому что вы
еще не настроили тестовую среду. Поскольку исходные файлы для ClusterJ формируются как проекты Maven,
можно легко импортировать их в любимые позволенные Maven IDE,
настроить их и восстановить их по мере необходимости, выполнив эти шаги: Удостоверьтесь, что ваша поддержка IDE для Maven
включена. Вы, возможно, должны были бы установить плагин Maven для цели.
Следуйте за шагами 1 и 2
здесь,
которые делают источник ClusterJ готовым использоваться с Maven. Импортируйте ClusterJ как проект Maven. В NetBeans: В главном меню выберите >
. Диалоговое окно
Open Project появляется. В окне Open Project перейдите к папке
Работайте с проектами ClusterJ как с любыми другими проектами
Maven в NetBeans. Любые изменения исходного кода входят в исходное дерево, из
которого вы собрали кластер NDB, чтобы создать каталог сборки. В Eclipse: В главном меню выберите >
. Откроется окно
Import. В окне Import выберите
> для импорта и нажмите
. Появится окно
Import Maven Projects. В окне Import Maven Projects перейдите
в каталог Работайте с проектами ClusterJ как с любыми другими
проектами Maven в Eclipse. Эта секция предоставляет основную информацию для написания, компилирования
и выполнения приложений с ClusterJ. Для документации API ClusterJ см.
раздел 4.3. Требования. ClusterJ требует Java 1.7 или 1.8.
NDB Cluster должен быть собран с поддержкой
ClusterJ ; модули NDB Cluster, поставляемые Oracle, включают
поддержку ClusterJ. Если вы строите кластер NDB сами, см.
здесь
для получения информации о настройке, чтобы позволить поддержку ClusterJ. Чтобы собрать приложения, которые используют ClusterJ, вы должны иметь
файл Чтобы запустить приложения, которые используют ClusterJ, вам нужен файл
jar В этой секции мы обсуждаем, как запустить приложения ClusterJ и
среду приложения ClusterJ. Выполнение приложения ClusterJ. Все файлы ClusterJ jar
обычно находятся в Точные местоположения файлов ClusterJ jar и
ClusterJ поощряет вас использовать различные файлы jar
во время компиляции и во время выполнения. Это должно удалить способность
запросов получить доступ к экспонатам внедрения экземплярно.
ClusterJ предназначается, чтобы быть независимым от версии программного
обеспечения NDB Cluster, тогда как слой
Получение SessionFactory и Session.
Название файла произвольно, однако, в соответствии с соглашением, такие
файлы называют с расширением После редактирования и сохранения файл, можно загрузить его содержание в
экземпляр Также возможно установить эти свойства непосредственно
без использования файла: Как только свойства были установлены и загружены (используя
любой из методов), можно получить
Обычно достаточно установить и загрузить свойства
Экземпляры Для
Обработка ошибок и повторное соединение.
Ошибки, которые происходят, используя ClusterJ, должны быть обработаны
приложением с обработчиком ошибки. Он должен быть в состоянии обнаружить и
различать три типа ошибок и обращаться с ними соответственно: Normal errors:
Это ошибки на уровне приложения (например, двойной ключ, ограничение внешнего
ключа или тайм-аут). Они должны быть обработаны специализированными
способами, и, если решено, приложение может продолжить транзакцию. Unexpected errors:
Это отказы работать с кластером, которые не могут составляться условиями
приложения, но неокончательны. Приложение должно закрыть сессию ClusterJ и
вновь открыть новую. Connectivity errors:
Это такие ошибки как 4009 и 4010, которые указывают на сетевой сбой.
Есть два возможных сценария, в зависимости от того, была ли автоматическая
опция повторного соединения (доступно для NDB Cluster 7.5.7, 7.6.3
и для более поздних выпусков в сериях 7.5 и 7.6) включена: Automatic reconnection is enabled:
опция активирована, когда свойство связи
Когда ClusterJ обнаруживает разъединение с кластером NDB, он изменяет
Метод Если приложение не закрывает все сессии к концу периода тайм-аута,
определенного Автоматическое повторное соединение не
позволено: Это когда свойство связи
ClusterJ не пытается снова соединиться с кластером NDB, как только связь
потеряна. Приложение должно закрыть все сессии и затем перезапустить
Вместо того, чтобы активировать опцию и ждать ClusterJ, чтобы обнаружить
разъединение и делать попытку повторного соединения, у вас это может также
сделать само приложение, начиная процесс повторного соединения после
обнаружения ошибки связи, вызывая метод
Журналирование. ClusterJ использует
Java logging. Вот некоторые настройки по умолчанию для
регистрации ClusterJ, которые определяются в файле
Регистрация уровня установлена в
Используется обработчик
Уровень по умолчанию для
Используется Файлы журнала хранятся в каталоге
Файл Главная цель ClusterJ состоит в том, чтобы читать, писать и обновлять
данные о строке в существующей базе данных, вместо того, чтобы выполнять
DDL. Можно создать таблицу Теперь, когда таблица была составлена в кластере NDB, можно отобразить
интерфейс ClusterJ к ней, используя аннотации. Мы показываем вам, как сделать
это в следующей секции. В ClusterJ (как в JPA) аннотации используются, чтобы описать, как
интерфейс отображен к таблицам в базе данных. Аннотируемый интерфейс
похож на это: Этот интерфейс отображает семь столбцов: Внедрение этого интерфейса создается динамично ClusterJ во время
выполнения. Когда вызван метод ClusterJ не требует аннотации для каждого признака. ClusterJ автоматически
обнаруживает первичные ключи таблиц, в то время как есть аннотация в
ClusterJ, чтобы разрешить пользователю описывать первичные ключи таблицы (см.
предыдущий пример), когда определено, это в настоящее время игнорируется.
Надлежащее использование этой аннотации для генерации схем от интерфейсов
модели объекта области, но это еще не поддерживается. Сами аннотации должны быть импортированы из ClusterJ API. Они могут быть
найдены в пакете
В этой секции мы описываем, как выполнить операции, основные для
приложений ClusterJ, включая следующие: Создание новых экземпляров, урегулирование их свойств и сохранение
их в базе данных. Выполнение поисков первичного ключа. Обновление существующих строк и сохранение изменений базы данных.
Удаление строк из базы данных. Построение и выполнение запросов, чтобы принести набор
строк, соответствующих определенным критериям от базы данных.
Создание новых строк. Чтобы вставить новую строку в таблицу, сначала
создайте новый экземпляр Установите свойства экземпляра Как только вы удовлетворены изменениями, можно сохрангить экземпляр
Если autocommit=on и строка с тем же самым
Если вы хотите, чтобы данные были сохранены
даже при том, что строка уже существует, используйте метод
Сначения, которые вы не определили, снабжены их значениями по умолчанию
(
Поиски первичного ключа. Можно найти существующую строку в таблице
Это эквивалентно запросу на поиск первичного ключа
ClusterJ также поддерживает составные первичные ключи. Метод
ClusterJ также поддерживает btree и уникальные hash-индексы.
Как с первичными ключами, если запрос определяет значения для областей
упорядоченного или уникального индекса, ClusterJ оптимизирует запрос, чтобы
использовать индекс для просмотра таблицы. NDB Cluster автоматически размазывает данные таблицы на многократные узлы
данных. Для некоторых операций более эффективно сказать кластеру, на котором
узле данных физически расположены данные и выполнять транзакцию на том узле
данных. ClusterJ автоматически обнаруживает ключ разделения,
если операция может быть оптимизирована для определенного узла данных,
ClusterJ автоматически начинает транзакцию на том узле.
Обновите и сохраните строку. Чтобы обновить значение данного столбца
в строке, которую мы просто получили как
Для удобства мы используем в этом примере метод
Посмотрите обозначенный файл для получения дополнительной информации. Можно обновить дополнительные столбцы, призвав другие методы установщики
Чтобы сохранить измененную строку назад в базу данных NDB Cluster,
используйте метод Удаление строк.
Можно удалить единственную строку, используя метод
Там также существует метод для удаления многократных строк, который
предоставляет две возможности: Удалите все строки из таблицы. Удалите произвольную коллекцию строк. Оба вида многострочных удалений могут быть выполнены, используя метод
Вызов
Нет необходимости найти экземпляры в базе данных прежде, чем удалить их.
Написание запросов.
Интерфейс ClusterJ
Это используется, чтобы установить столбец для сравнения запросом.
Здесь мы показываем, как подготовить запрос, который сравнивает значение
столбца Чтобы получить следствия запроса, вызовите метод
Возвращаемое значение это
Транзакции. Интерфейс
Также возможно использование
Если вы не используете интерфейс ClusterJ обеспечивает отображения для всех общих типов БД MySQL к типам
Java. Объекты типов Java-примитивов должны быть отображены
к nullable столбцам базы данных. Так как у Явы нет родных unsigned типов данных, столбцов
Совместимость с отображениями JDBC. ClusterJ осуществляется, чтобы
быть совместимым с драйвером JDBC с точки зрения отображения от типов Java
до базы данных. Таким образом, если вы используете ClusterJ, чтобы сохранить
или восстановить данные, вы получаете то же самую значение, как будто вы
использовали драйвер JDBC непосредственно или через JPA. Следующие таблицы показывают отображения, используемые ClusterJ между
общими типами данных Java и типами столбца MySQL. Отдельные таблицы
предусмотрены для числовых типов и для типов переменной
ширины с плавающей запятой. Числовые типы. Эта таблица показывает отображения типов в ClusterJ
между Java и MySQL: Таблица 4.1. Типы даты и времени.
Следующая таблица показывает отображения типов данных даты и времени
между Java и MySQL: Таблица 4.2. ClusterJ отображает MySQL
Типы переменной ширины. Следующая таблица показывает отображения
ClusterJ между типами Java и MySQL: Таблица 4.3. Никакие двоичные данные не отображаются при переходе от MySQL
Клиенты JDBC источника данных NDB Cluster, использующие Connector/J
5.0.6 (и выше), понимают
Однако, в то время как Connector/J не зависит от библиотек клиента MySQL,
он действительно требует связи с сервером MySQL, что не делает ClusterJ.
JDBC также не обеспечивает отображений объекта для объектов базы данных,
свойств, операций или любого способа сохранить объекты. См.
MySQL Connector/J 5.1 Developer Guide. Следующие разделы содержат технические требования для пакетов ClusterJ,
интерфейсов, классов и методов. Обеспечивает классы и интерфейсы для использования NDB Cluster
непосредственно из Java. Класс для самонастройки. Интерфейсы для использования в прикладных программах. Классы, чтобы определить исключения. Этот пакет содержит три главных группы классов и интерфейсов. ClusterJ обеспечивает эти главные интерфейсы для
использования прикладными программами:
com.mysql.clusterj.connectstring
определяет имя хоста и порт ndb_mgmd. com.mysql.clusterj.connect.retries количество повторений соединений.
com.mysql.clusterj.connect.delay задержка в секундах
между повторениями связи. com.mysql.clusterj.connect.verbose показать ли сообщение в
System.out, соединяясь. com.mysql.clusterj.connect.timeout.before число секунд, чтобы ждать,
пока первый узел не отвечает на запрос связи. com.mysql.clusterj.connect.timeout.after число секунд, чтобы ждать,
пока последний узел не отвечает на запрос связи. com.mysql.clusterj.connect.database название базы
данных, чтобы использовать. Session
Нахождение постоянных экземпляров первичным ключом. Постоянная фабрика экземпляров (newInstance). Постоянное управление жизненным циклом
экземпляра (сохранение, удаление). Получение QueryBuilder. Получение Transaction (currentTransaction). Transaction
Начать блок действий. Передайте изменения от блока действий. Отменить все изменения от блока действий. Отметить блок действий как rollback only. Получить статус обратной перемотки текущего блока действий.
QueryBuilder
Определите модель объекта области, чтобы запросить. Сравните свойства с использованием параметров: equal lessThan greaterThan lessEqual greaterEqual between in Объедините использование сравнений "and", "or" и "not". ClusterJUserException представляет ошибку базы данных.
Первопричина исключения содержится в "cause". Унаследовано от
com.mysql.clusterj.ClusterJException:
Унаследовано от
java.lang.Throwable:
Унаследовано от
java.lang.Object:
Получите классификацию. Получите код. 7.3.15, 7.4.13, 7.5.4 Получите код mysql. 7.3.15, 7.4.13, 7.5.4 Получите статус. Вспомогательный класс для getClassification().
import com.mysql.clusterj.ClusterJDatastoreException.Classification;
Classification c = Classification.lookup(datastoreException.getClassification());
System.out.println("exceptionClassification " + c + " with value
" + c.value); Унаследовано от
java.lang.Enum:
Унаследовано от
java.lang.Object:
7.3.15, 7.4.13, 7.5.4 Получите классификацию для значения, возвращенного
ClusterJDatastoreException.getClassification(). Таблица 4.4. lookup(int) ClusterJException основа для всех исключений ClusterJ.
Приложения могут поймать ClusterJException, который будет зарегистрирован
относительно всего ClusterJ. Пользовательские исключения вызываются пользовательской ошибкой,
например обеспечивая строку соединения, которая относится к недоступному
хосту или порту. Если пользовательское исключение обнаружено во время самонастройки
(приобретая SessionFactory), это брошено как критическое исключение
Если исключение обнаружено во время инициализации постоянного
интерфейса, например аннотировав столбец, который не существует в
таблице, об этом сообщают как пользовательское исключение
Исключения хранилища данных сообщают об условиях, которые следуют из
операций по хранилищу данных после самонастройки. Например, дубликаты ключа
на вставке или несуществующая запись при удалении выдадут
Внутренние исключительные ситуации сообщают об условиях, которые
вызываются ошибками во внедрении. Об этих исключениях нужно сообщить как об
ошибках исключением Исключения находятся в трех общих категориях: User exceptions,
Datastore exceptions и Internal exceptions.
Прямые известные подклассы:
Унаследовано от
java.lang.Throwable:
Унаследовано от
java.lang.Object:
ClusterJFatalException представляет исключение,
которое не восстанавливаемо.
Известные прямые подклассы:
Унаследовано от
com.mysql.clusterj.ClusterJException:
Унаследовано от
java.lang.Throwable:
Унаследовано от
java.lang.Object:
ClusterJFatalInternalException представляет ошибку внедрения, после
которой не может восстановиться пользователь. Унаследовано от
com.mysql.clusterj.ClusterJException:
Унаследовано от
java.lang.Throwable:
Унаследовано от
java.lang.Object:
ClusterJFatalUserException представляет пользовательскую ошибку, которая
является невосстанавливаемой, такой как программные ошибки в постоянных
классах или недостающие ресурсы в среде выполнения. Унаследовано от
com.mysql.clusterj.ClusterJException:
Унаследовано от
java.lang.Throwable:
Унаследовано от
java.lang.Object:
ClusterJHelper предоставляет вспомогательные методы взаимодействия
между API и внедрением. Унаследовано от
java.lang.Object:
Получите названное булевого свойства от окружающей среды или от системных
свойств. Если свойство не 'true', тогда возвращаются false. Таблица 4.5.
getBooleanProperty(String, String) Определите местонахождение реализации услуги сервисным поиском
загрузчика класса контекста. Таблица 4.6.
getServiceInstance(Class<T>) Определите местонахождение реализации услуги для обслуживания сервисным
поиском определенного загрузчика класса.
Первый найденный сервисный экземпляр возвращен. Таблица 4.7.
getServiceInstance(Class<T>, ClassLoader) Определите местонахождение реализации услуги для обслуживания.
Если имя внедрения не пустое, используйте его вместо поиска.
Если класс реализации не загружаемый или не осуществляет интерфейс, бросает
исключение. Используйте загрузчик класса ClusterJHelper,
чтобы найти обслуживание. Таблица 4.8.
getServiceInstance(Class<T>, String) Определите местонахождение реализации услуги для обслуживания.
Если имя внедрения не пустое, используйте его вместо поиска.
Если класс реализации не загружаемый или не осуществляет
интерфейс, бросает исключение. Таблица 4.9.
getServiceInstance(Class<T>, String, ClassLoader) Определите местонахождение всех реализаций услуги сервисным поиском
определенного загрузчика класса. Внедрения в сервисном файле возвращаются.
Неудавшиеся экземпляры остаются в буфере errorMessages. Таблица 4.10.
getServiceInstances(Class<T>, ClassLoader, StringBuffer) Определите местонахождение внедрения SessionFactory сервисным поиском.
Используемый загрузчик класса является загрузчиком класса контекста потока.
Таблица 4.11.
getSessionFactory(Map) Исключения Если связь с кластером не может быть установлена
Определите местонахождение внедрения SessionFactory сервисным поиском
определенного загрузчика класса. Свойства это карта, которая может
содержать определенные для внедрения свойства плюс стандартные свойства. Таблица 4.12.
getSessionFactory(Map, ClassLoader) Исключения Если связь с кластером не может быть установлена
Получите названное строкой свойство от окружающей среды или
от системных свойств. Таблица 4.13.
getStringProperty(String, String) Возвратите новый экземпляр Dbug. Таблица 4.14. newDbug() ClusterJUserException представляет пользовательскую программную ошибку. Унаследовано от
com.mysql.clusterj.ClusterJException:
Унаследовано от
java.lang.Throwable:
Унаследовано от
java.lang.Object:
Возвратите имя набора символов. Таблица 4.15. charsetName() Возвратите тип столбца. Таблица 4.16. columnType() Возвратит, является ли этот столбец столбцом ключа разделения. Таблица 4.17. isPartitionKey() Возвратит, является ли этот столбец столбцом первичного ключа. Таблица 4.18. isPrimaryKey() Возвратите java-тип столбца. Таблица 4.19. javaType() Возвратите максимальное количество байтов, которые могут быть сохранены в
колонке после трансляции знаков, используя набор символов. Таблица 4.20. maximumLength() Возвратите название столбца. Таблица 4.21. name() Возвратит nullable ли столбец. Таблица 4.22. nullable() Возвратите номер столбца. Это число используется в качестве первого
параметра в методах get и set DynamicColumn. Таблица 4.23. number() Возвратите точность столбца. Таблица 4.24. precision() Возвратите масштаб столбца. Таблица 4.25. scale() Этот класс перечисляет типы столбца для столбцов в ndb. Унаследовано от
java.lang.Enum:
Унаследовано от
java.lang.Object:
Константы используются в ClusterJ. Значение по умолчанию размеров пула буферов в байтах: 256, 10K, 100K, 1M.
Значение по умолчанию автоувеличения пакетного размера связи. Значение по умолчанию начального автоувеличения связи. начение по умолчанию связи шага автоувеличения связи. Значение по умолчанию задержки связи. Значение по умолчанию повторов связи. Значение по умолчанию тайм-аута после связи. Значение по умолчанию тайм-аута перед связью. Значение по умолчанию тайм-аута связи mgm. Значение по умолчанию подробности связи. Значение по умолчанию базы данных. Значение по умолчанию максимального количества транзакций. Значение по умолчанию порога активации потока. Значение по умолчанию размера пула связи. 7.5.7 Значение по умолчанию тайм-аута повторного соединения связи.
Автоматическое повторное соединение из-за отказов сети отключено. Название переменной окружения, чтобы установить обработчик журналов. Название свойства размера пула байтового буфера.
Чтобы отключить буферный пул для объектов blob, установите значение этого
свойства в "1". С этим значением буфера будут выделены, освобождены и убраны,
если возможно, немедленно после использования для передачи данных blob. Имя свойства автоувеличения пакетного размера связи. Название свойства начального автоувеличения связи. Название свойства шага автоувеличения связи. Название свойства тайм-аута связи.
Для получения дополнительной информации см.
Ndb_cluster_connection::connect(). Название свойства повторов связи.
Для получения дополнительной информации см.
Ndb_cluster_connection::connect(). Название свойства тайм-аута после связи.
Для получения дополнительной информации см.
Ndb_cluster_connection::wait_until_ready(). Название свойства тайм-аута перед связью.
Для получения дополнительной информации см.
Ndb_cluster_connection::wait_until_ready(). Название начального тайм-аута для связи кластера, чтобы соединиться
с MGM прежде, чем соединить с узлами данных
Ndb_cluster_connection::set_timeout(). Название свойства подробности связи.
Для получения дополнительной информации см.
Ndb_cluster_connection::connect(). Название свойства сервиса связи. Название значения строки подключения.
Для получения дополнительной информации см.
Ndb_cluster_connection constructor. Название значения базы данных. Для получения дополнительной информации
посмотрите параметр catalogName конструктора Ndb
Ndb constructor. Название максимального количества транзакций.
Для получения дополнительной информации посмотрите
Ndb::init(). Название пула связи id узлов. Нет никакого значения по умолчанию.
Это список id узлов, чтобы вынудить связи быть назначенными на определенные
id узла. Если это свойство определяется и размер пула связи не по умолчанию,
количество id узлов списка должно соответствовать размеру пула связи или
количество id узлов должно быть 1, и id узла будут назначены на связи,
начинающиеся с указанного id узла. Порог активации потока для всех связей в пуле связи.
По умолчанию нет порога активации. Закрепление CPU получения потоков для связей в пуле связи.
По умолчанию нет закрепления CPU. Если это свойство определяется и размер
пула связи не по умолчанию (1), количество cpuids в списке должно
соответствовать размеру пула связи. Название свойства размера пула связи. Это количество связей, чтобы создать
в пуле связи. По умолчанию равняется 1 (все сессии разделяют ту же самую
связь, все запросы SessionFactory с той же строкой подключения
и базой данных разделят единственную SessionFactory). Установка 0
отключает объединение, каждый запрос SessionFactory
получит свой собственный уникальный SessionFactory. 7.5.7 Число секунд, чтобы ждать всех сессий, которые будут закрыты, повторно
подключая SessionFactory из-за отказов сети. По умолчанию 0 указывает, что
автоматическое повторное соединение к кластеру из-за отказов сети отключено.
Повторное соединение может быть позволено при помощи метода
SessionFactory.reconnect(int timeout) и определением нового тайм-аута. Флаг для отсроченных вставок, удалений и обновлений. Имя драйвера jdbc. Пароль для jdbc. url для jdbc. Имя пользователя jdbc. Название сервисного интерфейса сессии. Названия файлов с именами классов реализации для сервиса сессии. Dbug позволяет приложениям clusterj включить функциональность DBUG в
библиотеке кластера ndbapi. Статус dbug это управляющая строка,
которая состоит из флагов, отделенных двоеточиями. Флаги: d устанавливают флаг отладки. a[,filename] добавляет вывод отладки к файлу. A[,filename] аналогично a[,filename], сбрасывает вывод
после каждой операции. d[,keyword[,keyword...]] позволяет вывод из
макроса с указанными ключевыми словами. D[,tenths] ждет в течение указанных десятых частей секунды
после каждой операции. f[,function[,function...]]
ограничивает вывод указанным списком функций. F отмечает каждый вывод именем исходного файла. i отмечает каждый вывод process id текущего процесса. g[,function[,function...]] профиль определенного списка функций.
L отмечает каждый вывод номером строки исходного файла. n отмечает каждый вывод текущей глубиной вложения функции. N отмечает каждый вывод порядковаым номером. o[,filename] переписывает вывод оталдки в файле. O[,filename] аналогично o[,filename], но сбрасывает вывод
после каждой операции. p[,pid[,pid...]] ограничивает вывод указанным списком process ids.
P отмечает каждый вывод именем процесса. r перезагружает уровень отступа к нолю. t[,depth] ограничивает вложение функции указанной глубиной. T отмечает каждый вывод текущей меткой времени. Например, чтобы проследить вызовы и выводимую отладочную информацию только
для "jointx" и переписать содержание файла "/tmp/dbug/jointx", используйте
"t:d,jointx:o,/tmp/dbug/jointx". Вышеупомянутое может быть написано как
ClusterJHelper.newDbug().trace().debug("jointx").output("/tmp/dbug/jointx").set();
Определите имя файла для вывода отладки (добавление). Таблица 4.26. append(String) Установите список ключевых слов отладки. Таблица 4.27. debug(String) Установите список ключевых слов отладки. Таблица 4.28. debug(String[]) Принудительный сброс после каждой операции по выводу. Таблица 4.29. flush() Возвратите текущее состояние. Таблица 4.30. get() Определите имя файла для вывода отладки (перезапись). Таблица 4.31. output(String) Вернуть текущее состояние. Новый статус будет ранее сохраненным статусом.
Напечатайте сообщение отладки. Сохраните текущее состояние, как определено методами. Сохраните текущее состояние и установите параметр как новый статус. Таблица 4.32. push(String) Установите текущее состояние, как определено методами. Установите текущее состояние от параметра. Таблица 4.33. set(String) Установите флаг трассировки. Таблица 4.34. trace() Унаследовано от
java.lang.Object:
Способы блокировки для операций чтения. SHARED: Установите коллективную блокировку на строках. EXCLUSIVE: Установите монопольную блокировку на строках. READ_COMMITTED: Не устанавливайте блокировку, но прочитайте
новые переданные значения. Унаследовано от
java.lang.Enum:
Унаследовано от
java.lang.Object:
Экземпляр запроса представляет определенный запрос со связанными
параметрами. Экземпляр создается методом Запрос объясняет использование ключа индекс. Запрос объясняет ключ типа просмотра. Запрос объясняет значение типа просмотра для просмотра индекса. Запрос объясняет значение типа просмотра для первичного ключа. Запрос объясняет значение типа просмотра для сканирования таблицы. Запрос объясняет значение типа просмотра для уникального ключа. Удалите экземпляры, которые удовлетворяют условиям запроса. Таблица 4.35.
deletePersistentAll() Выполните запрос с одним или несколькими названными параметрами.
Параметры найдены по имени. Таблица 4.36.
execute(Map<String, ?>) Выполните запрос с одним или несколькими названными параметрами.
Параметры найдены по порядку, в котором они были объявлены в запросе. Таблица 4.37.
execute(Object...) Выполните запрос точно с одним параметром. Таблица 4.38. execute(Object) Объясните, как этот запрос будет или был выполнен. Если вызван прежде, чем
все параметры связаны, бросит ClusterJUserException. Возвратит карту пар
key:value, которые объясняют, как запрос будет или был выполнен.
Детали могут быть получены, вызывая toString на значении.
Следующие ключи возвращены:
ScanType: тип просмотра: PRIMARY_KEY: запрос использует ключевой поиск с первичным ключом.
UNIQUE_KEY: запрос используемый ключевой поиск с уникальным ключом.
INDEX_SCAN: запрос использовал просмотр
диапазона с неуникальным ключом. TABLE_SCAN: запрос использовал сканирование таблицы. IndexUsed: название используемого индекса, если есть. Таблица 4.39. explain() Исключения если не все параметры связаны Получите результаты как список. Таблица 4.40. getResultList() Исключения если не все параметры связаны если об исключении сообщает хранилище данных Установите пределы для результатов возврата. Выполнение запроса изменяется,
чтобы возвратить только подмножество результатов. Если фильтр обычно
возвращал бы 100 случаев, skip установлен в 50, а limit в 40, то первые 50
результатов, которые были бы возвращены, пропускаются, следующие 40
результатов возвращены, а остальные 10 проигнорированы. Skip должен быть больше или равным 0. Limit должен быть
больше или равным 0. Пределы не могут использоваться с deletePersistentAll.
Таблица 4.41. setLimits(long, long) Установить порядок для результатов этого запроса.
Выполнение запроса изменяется, чтобы использовать индекс, ранее определенный.
Должен быть индекс, определенный на столбцах, отображенных
к указанным полям в нужном порядке. Не должно быть никаких промежутков в полях относительно индекса.
Все области должны быть в индексе, но не все области в индексе должны
быть в порядке полей. Если применен предикат "in" в фильтре на области в порядке, это может
использоваться только с первой областью. Если какое-либо из этих условий нарушено, ClusterJUserException
брошен, когда запрос выполняется. Если применен предикат "in", каждый элемент в параметре определяет
отдельный диапазон, и упорядочивание выполняется в том диапазоне. Может быть
лучший (более эффективный) индекс на основе фильтра, но определение порядка
вынудит запрос использовать индекс, который содержит заданные области. Таблица 4.42.
setOrdering(Query.Ordering, String...) Установите значение параметра. Если вызвано многократно для того же самого
параметра, тихо заменит значение. Таблица 4.43. setParameter(String, Object) Упорядочивание Унаследовано от
java.lang.Enum:
Унаследовано от
java.lang.Object:
Результаты запроса.
Определен: метод
Получите итератор по результатам запроса. Таблица 4.44. iterator() Сессия это основной пользовательский интерфейс к кластеру.
Сессия расширяет AutoCloseable, таким образом, это может использоваться в
шаблоне try-with-resources. Этот шаблон позволяет приложению
создать сессию в декларации try и независимо от результата блока
try/catch/finally clusterj очистит и закроет сессию. Если блок try выходит
с открытой транзакцией, транзакция будет отменена, прежде
чем сессия закрывается.
Определен: метод
Закройте эту сессию. Создайте запрос из QueryDefinition. Таблица 4.45.
createQuery(QueryDefinition<T>) Получите текущий Таблица 4.46. currentTransaction() Удалите экземпляр класса из базы данных, данной ее первичным ключом.
Для ключей отдельного столбца основной параметр это обертка (например,
Integer). Для многостолбцовых ключей основной параметр Object[], в котором
элементы соответствуют первичным ключам в порядке их определения в схеме. Таблица 4.47.
deletePersistent(Class<T>, Object) Удалите экземпляр из базы данных. Только идентификационная область
используется, чтобы определить, какой экземпляр должен быть удален.
Если экземпляр не существует в базе данных, исключение брошено. Таблица 4.48.
deletePersistent(Object) Удалите все экземпляры этого класса из базы данных. Никакое исключение не
брошено, даже при отсутствии экземпляров в базе данных. Таблица 4.49.
deletePersistentAll(Class<T>) Удалите все экземпляры параметра из базы данных. Таблица 4.50.
deletePersistentAll(Iterable<?>) Найдите определенный экземпляр его первичным ключом.
Ключ должен иметь тот же самый тип как первичный ключ, определенный
соответствующим параметром cls. Основной параметр это обернутая версия типа
примитива ключа, например, Integer для типов ключа INT, Long для BIGINT или
String для типов char и varchar.
Для многостолбцовых первичных ключей основной параметр Object[],
каждый элемент которого является компонентом первичного ключа.
Элементы должны быть в порядке декларации столбцов (не обязательно порядок,
определенный в CONSTRAINT ... PRIMARY KEY) в CREATE TABLE. Таблица 4.51.
find(Class<T>, Object) Сбросить отсроченные изменения. Вставки, удаления, загрузки и
обновления посылают в бэкэнд. Строка соответствовала этому экземпляру, найденному в базе данных? Таблица 4.52. found(Object) пустой указатель, если экземпляр пустой или был создан через
newInstance и никогда не загружался true, если экземпляр был возвращен из поиска или запроса или создан
через newInstance и успешно загружен false, если экземпляр был создан через newInstance и не найден
Получите QueryBuilder. Таблица 4.53. getQueryBuilder() Эта сессия закрывается? Таблица 4.54. isClosed() Загрузите экземпляр из базы данных в память. Загрузка асинхронная и будет
выполнена, когда операционный доступ к базе данных требования выполняется:
find, flush или query. Экземпляр должен быть возвращен из поиска или запроса
или создан через session.newInstance, и его первичный ключ инициализируется.
Таблица 4.55. load(T) Вставьте экземпляр в базу данных. Если экземпляр уже существует в базе
данных, исключение брошено. Таблица 4.56. makePersistent(T) Вставьте экземпляры в базу данных. Таблица 4.57.
makePersistentAll(Iterable<?>) Отметьте область в объекте, как измененную, таким
образом, это сбрасывается. Таблица 4.58.
markModified(Object, String) Создайте экземпляр интерфейса или динамического класса,
который отображается к таблице. Таблица 4.59.
newInstance(Class<T>) Создайте экземпляр интерфейса или динамического класса, который
отображается к таблице и устанавливает первичный ключ нового экземпляра.
Новый экземпляр может использоваться, чтобы создать, удалить или обновить
запись в базе данных. Таблица 4.60.
newInstance(Class<T>, Object) Вставьте экземпляр в базу данных. У этого метода есть идентичная
семантика с makePersistent. Таблица 4.61. persist(Object) Высвободите ресурсы, связанные с экземпляром. Экземпляр должен быть
запросом или объектом области, полученным через
session.newInstance(T.class), find(T.class), множеством T[] или итератором.
Высвобожденные ресурсы могут включать прямые буфера, используемые, чтобы
содержать данные экземпляра. Высвобожденные ресурсы могут
быть возвращены в пул. Таблица 4.62. release(T) Исключения если экземпляр не объект области T, итератор или множество
T[], или если объект используется после вызова этого метода. Удалите экземпляр из базы данных. У этого метода есть идентичная
семантика с deletePersistent. Таблица 4.63. remove(Object) Сохраните экземпляр в базе данных, не проверяя на существование.
Идентификационная область используется, чтобы определить, какой экземпляр
должен быть сохранен. Если экземпляр будет существовать в базе данных, то это
будет обновлено. Если экземпляр не будет существовать, он будет создан. Таблица 4.64. savePersistent(T) Обновите все экземпляры параметра в базе данных. Таблица 4.65.
savePersistentAll(Iterable<?>) Установите режим блокировки для операций чтения. Это немедленно вступит в
силу и останется в силе, пока эта сессия не закрывается, или этот метод
не вызовут снова. Таблица 4.66.
setLockMode(LockMode) Установите ключ разделения для следующей транзакции. Ключ должен иметь тот
же самый тип как первичный ключ, определенный таблицей, соответствующей
параметру cls. Основной параметр это обернутая версия типа примитива ключа,
например, Integer для типов ключа INT, Long для BIGINT или String для
char и varchar. Для многостолбцовых первичных ключей основной параметр это
Object[], каждый элемент которого является компонентом первичного ключа.
Элементы должны быть в порядке декларации столбцов (не обязательно это
порядок, определенный в CONSTRAINT ... PRIMARY KEY) в CREATE TABLE. Таблица 4.67.
setPartitionKey(Class<?>, Object) Исключения если транзакция включается в список если ключ разделения пустой если вызвано дважды в той же самой транзакции если ключ разделения имеет неправильный тип Выгрузите определение схемы для класса. Это должно быть сделано после
того, как определение схемы изменилось в базе данных из-за изменения таблицы
командой alter. В следующий раз, когда класс используется,
схема будет перезагружена. Таблица 4.68.
unloadSchema(Class<?>) Обновите экземпляр в базе данных, не обязательно получая его.
Идентификационная область используется, чтобы определить, какой экземпляр
должен быть обновлен. Если экземпляр не существует в базе данных, исключение
брошено. Этот метод не может использоваться, чтобы изменить первичный ключ.
Таблица 4.69.
updatePersistent(Object) Обновите все экземпляры параметра в базе данных. Таблица 4.70.
updatePersistentAll(Iterable<?>) SessionFactory представляет кластер. Закройте эту фабрику сессии. Высвободите все ресурсы.
Установите текущее состояние в Closed. Когда закрыто, вызовы getSession
бросят ClusterJUserException. Получите текущее состояние этой фабрики сессии. 7.5.7 Получите список, содержащий количество открытых сессий для каждой
связи в пуле связи. 7.3.14, 7.4.12, 7.5.2 Получите порог активации потока для всех связей в пуле связи. 16 или более
значит, что потоки никогда не используются в качестве приемников. 0 значит,
что поток всегда активен, и это сохраняет пул для его собственного
исключительного использования, эффективно блокируя все пользовательские
потоки от становления приемниками. В таких экземплярах нужно соблюдать
осторожность, чтобы гарантировать, что поток получения не конкурирует с
пользовательской потоком за ресурсы CPU, предпочтительно для него быть
привязанным к CPU для его собственного исключительного использования.
По умолчанию равняется 8. 7.5.7 Получить привязку потока к cpu для всех связей в пуле связи.
Если поток получения не будет связан с CPU,
соответствующее значение будет -1. 7.5.7 Создайте Session, чтобы использовать с кластером, используя все
свойства SessionFactory. Таблица 4.71. getSession() Создайте сессию, чтобы использовать с кластером, отвергнув некоторые
свойства. Свойства PROPERTY_CLUSTER_CONNECTSTRING,
PROPERTY_CLUSTER_DATABASE и
PROPERTY_CLUSTER_MAX_TRANSACTIONS не могут быть перекрыты. Таблица 4.72. getSession(Map) Повторно подключите эту фабрику сессии, используя новое определенное
значение тайм-аута. Оно, возможно, было определено в оригинальных свойствах
сессии или, возможно, было изменено прикладным вызовом
reconnect(int timeout). 7.5.7 Разъедините и снова соедините эту фабрику сессии, используя указанный
тайм-аут и измените сохраненное значение тайм-аута. Это тяжелый метод и
должен редко использоваться. Это предназначается для случаев, где процесс, в
котором работает clusterj, потерял возможность соединения с кластером и
обычно не в состоянии функционировать. Повторное соединение сделано в
нескольких фазах. Во-первых, фабрика сессии устанавливает статус в
Reconnecting и начинает повторно подключать поток, чтобы управлять процедурой
повторного соединения. В статусе Reconnecting методы getSession бросают
ClusterJUserException и пул связи недоступен, пока все сессии не закрылись.
Если сессии не закрываются обычно после тайм-аута, сессии будут вынуждены
закрыться. Затем все связи в пуле связи закрываются, что освобождает их слоты
связи в кластере. Наконец, пул связи воссоздается, используя оригинальные
свойства пула связи, и статус устанавливается в Open.
Процедура повторного соединения асинхронная. Чтобы наблюдать прогресс
процедуры, используйте методы currentState и getConnectionPoolSessionCounts.
Если значение тайм-аута отлично от нуля, автоматическое повторное соединение
будет сделано clusterj после нахождения сбоя сети. Если значение тайм-аута
0, автоматическое повторное соединение отключено. Если текущее состояние этой
фабрики сессии Reconnecting, этот метод тихо ничего не делает. Таблица 4.73. reconnect(int) 7.5.7 Установите порог активации потока получения для всех связей в пуле связи.
16 или выше значит, что поток никогда не используется в качестве приемника.
0 значит, что поток всегда активен и это сохраняет пул для его собственного
исключительного использования, эффективно блокируя все пользовательские
потоки от становления приемниками. В таких экземплярах нужно соблюдать
осторожность, чтобы гарантировать, что поток получения не конкурирует с
пользовательским потоком за ресурсы CPU, предпочтительно для него быть
привязанным к CPU для его собственного исключительного использования.
По умолчанию равняется 8. Исключения если значение отрицательно если метод терпит неудачу из-за некоторой внутренней причины
7.5.7 Свяжите потоки получения с cpuid для всех связей в пуле связи. Определите
-1, чтобы сбросить привязку. cpuid должен быть между 0 и
количеством CPU в машине. Исключения если cpuid неправильный или если число элементов в cpuids не равно
количеству связей в пуле связи. если привязка терпит неудачу из-за некоторой внутренней причины
7.5.7 Статус этой фабрики сессии. Унаследовано от
java.lang.Enum:
Унаследовано от
java.lang.Object:
7.5.7 Этот интерфейс определяет сервис для создлания SessionFactory из
свойств Map<String, String>. Создайте или получите фабрику сессии. Если фабрика сессии с тем же
самым значением PROPERTY_CLUSTER_CONNECTSTRING уже создана в VM, существующая
фабрика возвращена, независимо от того, совпадают ли другие свойства
фабрики с определенными в Map. Таблица 4.74.
getSessionFactory(Map<String, String>) Транзакция представляет пользовательскую транзакцию, активную в кластере.
Начать транзакцию. Передать транзакцию. Эта транзакция была отмечена как rollback only? Таблица 4.75. getRollbackOnly() Есть ли в настоящее время активная транзакция? Таблица 4.76. isActive() Отменить транзакцию. Отметьте эту транзакцию как rollback only. После того, как этот метод
вызывают, commit() отменит транзакцию и бросит исключение, rollback()
отменит транзакцию и не бросит исключение. Этот пакет предоставляет аннотации для интерфейсов модели объекта области,
отображенных к таблицам базы данных. Аннотация для столбца в базе данных. Позволяет ли столбец нулевым значениям быть вставленными.
Это отвергает определение базы данных и требует, чтобы приложение обеспечило
ненулевые значения для столбцы базы данных. Таблица 4.77. allowsNull Значение по умолчанию для этой столбца. Таблица 4.78. defaultValue Название столбца. Таблица 4.79. name Аннотация для групп столбцов. Эта аннотация используется для
многостолбцовых структур, таких как индексы и ключи. Информация об аннотации столбцов.
Таблица 4.80. value Аннотация для нестандартного расширения. Ключ для расширения (требуется). Таблица 4.81. key Значение для расширения (требуется). Таблица 4.82. value Продавец, к которому расширение относится (требуется, чтобы
сделать ключ уникальным). Таблица 4.83. vendorName Аннотация для группы расширений. Расширения. Таблица 4.84. value Аннотация для индекса базы данных. Столбцы, которые составляют этот индекс. Таблица 4.85. columns Название индекса. Таблица 4.86. name Уникален ли этот индекс. Таблица 4.87 unique Аннотация для группы индексов. Это используется на классе, где есть
многократные определенные индексы. Индексы. Таблица 4.88 value Аннотация для Large Object (lob). Эта аннотация может использоваться с
типами byte[] и InputStream для столбцов двоичных данных, с
String и InputStream для символьных столбцов. Аннотация, чтобы определить, что участник не постоянный.
Если используется, это единственная аннотация, позволенная на участнике. Перечисление значений обработки "null-value".
Это поведение определяется в @Persistent аннотации. Унаследовано от
java.lang.Enum:
Унаследовано от
java.lang.Object:
Аннотация на класс или участника, чтобы определить ключ разделения.
Аннотируя класс или интерфейс, отдельный столбец или многочисленные столбцы
могут быть определены. Аннотируя участника, ни столбец, ни столбцы
не должны быть определены. Название столбца, чтобы использовать для ключа разделения. Таблица 4.89. column Столбец (столбцы) для ключа разделения. Таблица 4.90. columns Аннотация для того, способны ли класс или интерфейс к постоянству. Перечисление значений модификатора постоянства для участника. Унаследовано от
java.lang.Enum:
Унаследовано от
java.lang.Object:
Аннотация для определения постоянства участника. Имя столбца, где значения сохранены для этого участника. Таблица 4.91. column Нестандартные расширения для этого участника. Таблица 4.92. extensions Поведение, когда этот участник содержит нулевое значение. Таблица 4.93. nullValue Является ли этот участник частью первичного ключа для таблицы.
Это эквивалентно определению @PrimaryKey как отдельной
аннотации на участника. Таблица 4.94. primaryKey Аннотация на участника, чтобы определить его как члена первичного ключа
класса или постоянного интерфейса. Название столбца, чтобы использовать для первичного ключа. Таблица 4.95. column Столбец (столбцы) для первичного ключа. Таблица 4.96. columns Название ограничения первичного ключа. Таблица 4.97. name Аннотация на тип, чтобы определить его как проектирование таблицы.
Только столбцы, отображенные к постоянным областям/методам, будут
использоваться, выполняя операции на таблице. Обеспечивает интерфейсы создания запросов для ClusterJ. Используемый, чтобы объединить многократные
предикаты с логическими операциями. Объедините этот Предикат с другим, используя "and". Таблица 4.98. and(Predicate) Отрицайте этот Предикат. Таблица 4.99. not() Объедините этот Предикат с другим, используя "or". Таблица 4.100. or(Predicate) PredicateOperand представляет столбец или параметр, который
может сравниться с другим. Возвратите представление Предиката, сравнивающее его с
другим с использованием "between". Таблица 4.101.
between(PredicateOperand, PredicateOperand) Возвратите представление Предиката, сравнивающее его с другим с
использованием "equal to". Таблица 4.102.
equal(PredicateOperand) Возвратите представление Предиката, сравнивающее его
с другим с использованием "greater than or equal to". Таблица 4.103.
greaterEqual(PredicateOperand) Возвратите представление Предиката, сравнивающее его
с другим с использованием "greater than". Таблица 4.104.
greaterThan(PredicateOperand) Возвратите представление Предиката, сравнивающее его
с коллекцией с использованием "in". Таблица 4.105.
in(PredicateOperand) Возвратите представление Предиката, сравнивающее его с not null. Таблица 4.106. isNotNull() Возвратите представление Предиката, сравнивающее его с null. Таблица 4.107. isNull() Возвратите представление Предиката, сравнивающее его с другим с
использованием "less than or equal to". Таблица 4.108.
lessEqual(PredicateOperand) Возвратите представление Предиката, сравнивающее его с другим с
использованием "less than". Таблица 4.109.
lessThan(PredicateOperand) Возвратите представление Предиката, сравнивающее его с
другим с использованием "like". Таблица 4.110.
like(PredicateOperand) QueryBuilder представляет фабрику для запросов. Создайте QueryDefinition, чтобы определить запросы. Таблица 4.111.
createQueryDefinition(Class<T>) QueryDefinition позволяет пользователям определять запросы. Удобный метод отрицать предикат. Таблица 4.112. not(Predicate) Определите параметр для запроса. Таблица 4.113. param(String) Определите предикат, чтобы удовлетворить запрос. Таблица 4.114. where(Predicate) QueryDomainType представляет тип области запроса. Тип области утверждает
имена свойств, которые используются, чтобы отфильтровать результаты. Получите PredicateOperand, представляющий свойство типа области. Таблица 4.115. get(String) Получите тип области запроса. Таблица 4.116. getType() Таблица 4.117. com.mysql.clusterj.* Таблица 4.118. com.mysql.clusterj.* Эта секция обсуждает ограничения и известные проблемы в
MySQL NDB Cluster Connector for Java API.
Известные проблемы в ClusterJ:
Joins: с ClusterJ
запросы ограничиваются единственной таблицей. Это не проблема с JPA или JDBC,
оба из которых поддерживают соединения.
Database views:
Поскольку представления базы данных MySQL не используют
Relations and inheritance: ClusterJ
не поддерживает отношения или наследование.
Таблицы отображены непосредственно на классы области и только операции
единственной таблицы поддерживаются.
Таблицы
TIMESTAMP: Сейчас ClusterJ не
поддерживает тип данных timestamp для области первичного ключа.
Известные проблемы в JDBC и Connector/J:
Для получения информации об ограничениях и известных проблемах с
JDBC и Connector/J см.
JDBC API Implementation Notes и
Troubleshooting Connector/J Applications. Известные проблемы в NDB Cluster:
Для получения информации об ограничениях и других известных проблемах с
кластером NDB посмотрите
Known Limitations of NDB Cluster.
Глава 4. MySQL NDB Cluster Connector for Java
4.1. MySQL NDB Cluster Connector
for Java: обзор
4.1.1 MySQL NDB Cluster
Connector for Java Architecture
4.1.2. Java и NDB Cluster
NDBCLUSTER
то есть, к ряду узлов данных NDB Cluster (процесс
ndbd).
Есть три главных пути доступа из Java к
NDBCLUSTER:NDBCLUSTER.
Это использует стиль доступа к данным, который основан на модели объекта
области, подобной во многих отношениях используемому JPA. ClusterJ не зависит
от MySQL Server для доступа к данным.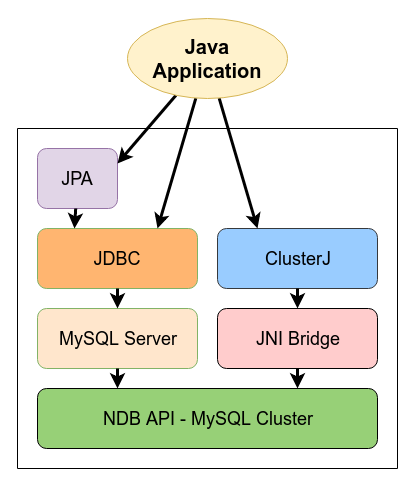
NDBCLUSTER (или
NDB), механизма хранения для
NDB Cluster, в стиле
Hibernate,
JPA и
JDO. Как другие структуры, ClusterJ использует
Data Mapper pattern, в котором данные представляются как
объекты области, отдельные от бизнес-логики, отображая классы Java
к таблицам базы данных, сохраненным в
NDBCLUSTER.NDBCLUSTER часто упоминается
(в документации MySQL и в других местах) просто как
as NDB. Термины
NDB и NDBCLUSTER
синонимичны и можно использовать также
ENGINE=NDB или
ENGINE=NDBCLUSTER в запросе
CREATE TABLE.NDBCLUSTER с использованием
моста JNI, который включен в динамическую библиотеку
libnbdclient. Однако в отличие от JDBC, ClusterJ
не поддерживает создание таблицы и другие операции по определению данных, они
должны быть выполнены некоторыми другими средствами, такими как JDBC или
клиент mysql.
Кроме того, ClusterJ ограничивается запросами на единственной таблице
и не поддерживает отношения или наследование, необходимо использовать другой
вид путей доступа, если вы нуждаетесь в поддержке для тех
особенностей в ваших запросах.
4.1.3. ClusterJ API и Data Object Model
Session,
SessionFactory,
Transaction и
QueryBuilder.Session
представляет отдельную связь пользователя с NDB Cluster.
Это содержит методы для следующих операций:SessionFactory,
где, как правило, есть единственный экземпляр для каждого NDB Cluster,
где вы хотите получить доступ из Java VM.
SessionFactory хранит конфигурационную
информацию о кластере, такую как имя хоста и номер порта сервера управления
кластером NDB. Это также хранит параметры относительно того, как соединиться
с кластером, включая задержки связи. Для получения дополнительной информации
о SessionFactory и его использовании в ClusterJ см.
здесь.Session, как другие современные среды разработки
приложения, ClusterJ отделяет управление транзакциями от других методов.
Операционное установление границ могло бы быть сделано автоматически
контейнером или в фильтре сервлета веб-сервера. Удаление операционных методов
завершения из Session
облегчает это разделение проблем.Transaction поддерживает стандартные начало,
передачу и отмену, требуемые транзакционной базой данных. Кроме того, это
позволяет пользователю отметить транзакцию, как "для обратной перемотки",
что позволяет компоненту, который не ответственен за завершение транзакции,
указать, что из-за приложения или ошибки базы данных транзакцию нельзя
заканчивать как обычно.QueryBuilder
позволяет построить запросы критериев динамично, используя свойства модели
объекта области в качестве элементов моделирования запроса.
Сравнения между параметрами и значениями столбцов базы данных могут быть
определены в операциях и отношениях. Эти сравнения могут быть объединены,
используя методы, соответствующие булевым операторам AND, OR и NOT.
Сравнение с NULL также поддерживается.NDB в кластере ClusterJ
использует один или несколько интерфейсов. Во многих случаях единственный
интерфейс используется, но для случаев, где различные колонки необходимы
различным частям приложения, многократные интерфейсы могут быть отображены
к той же самой таблице.
SessionFactory формируется объектом,
который, возможно, был загружен из файла или построен динамично приложением,
используя некоторые другие средства (см.
раздел 4.2.2.1).Session
из SessionFactory с самое большее одним
потоком, работающим с Session за один раз.
Поток может управлять многими экземплярами
Session, если есть требование многократных
связей с базой данных.4.2. Использование MySQL NDB Cluster
Connector for Java
4.2.1. Получение, установка и настройка
MySQL NDB Cluster Connector for Java
WITH_NDBCLUSTER_STORAGE_ENGINE
(или псевдоним
WITH_NDBCLUSTER).
cmake .. -DWITH_BOOST=/usr/local/boost_1_59_0 -DWITH_NDBCLUSTER=ON
WITH_NDB_JAVA
позволена по умолчанию, что означает, что ClusterJ будет построен вместе с
кластером NDB вышеупомянутой командой. Однако, если CMake не может найти
местоположение Java на вашей системе, процесс конфигурации собирается
потерпеть неудачу, используйте опцию
WITH_CLASSPATH, чтобы
обеспечить путь к классу Java в случае необходимости. Кроме того, потому что
ClusterJ использует набор символов ucs2
для внутренней памяти и ClusterJ не может быть построен без него, если вы
когда-нибудь используете опцию CMake
WITH_EXTRA_CHARSETS
и измените значение от настройки по умолчанию
all, необходимо удостовериться, что
ucs2 определяется в списке наборов символов,
переданном опции. Для получения информации о других опциях CMake, которые
могут использоваться, см.
option_cmake_with_ndbcluster.share/java в каталоге установки
MySQL (/usr/local/mysql по
умолчанию для Linux):clusterj-api-
: Это файл времени компиляции, требуемый
для компилирования кода приложения ClusterJ.version.jarclusterj-
: Это библиотека времени выполнения,
требуемая для выполнения приложений ClusterJ.version.jarclusterj-test-: Это набор тестов ClusterJ, требуемый для
тестирования вашей установки ClusterJ.
version.jarСборка ClusterJ с Maven
libndbclient.so)
как свойство ndbclient.lib к вашему местному
файлу Maven settings.xml (находится в местном
хранилище Maven, которое обычно является
/home/
в Linux). Библиотека клиента должна быть найдена в каталоге
username/.m2lib каталога установки NDB Cluster.
Если файла settings.xml не существует в вашем
местном хранилище Maven, создайте его. Это простой файл
settings.xml, содержащий свойство
ndbclient.lib:
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0
http://maven.apache.org/xsd/settings-1.0.0.xsd">
<profiles>
<profile>
<id>jni-library</id>
<activation>
<activeByDefault>true</activeByDefault>
</activation>
<properties>
<ndbclient.lib>/NDB_Cluster_installation_directory/lib/</ndbclient.lib>
</properties>
</profile>
</profiles>
</settings>
bld в образце
здесь) и затем в подкаталог
storage/ndb/clusterj в нем. Выполните скрипт
mvn_install_ndbjtie.sh:
./mvn_install_ndbjtie.sh
ndbjtie.jar,
который предоставляет слой JNI ClusterJ и требуется для сборки CluterJ.
storage/ndb/clusterj:
mvn install
.jar, установленными в местном хранилище Maven.
skipTests:
mvn install -DskipTests
Сборка ClusterJ с Maven в IDE
storage/ndb под каталогом сборки (см. шаг 2
здесь), выберите каталог
clusterj, который имеет символ Maven
(![]() ) и нажмите
.
Проект
) и нажмите
.
Проект ClusterJ Aggregate импортируется с
ClusterJ API, ClusterJ
Core, ClusterJ Test Suite,
ClusterJ Tie и
ClusterJ Unit Test Framework как подпроекты
в Modules.storage/ndb под каталогом сборки
(шаг 2 здесь), выберите каталог
clusterj и нажмите
. Проект
clusterj-aggregate, а также его подпроекты
its subprojects clusterj-api,
clusterj-core,
clusterj-test,
clusterj-tie и
clusterj-unit появятся в диалоговом окне
Maven Projects. Нажмите
и
.
Все проекты ClusterJ импортируются.4.2.2. Применение ClusterJ
clusterj-api jar в вашем classpath или
использовать менеджер по зависимости Maven, чтобы установить и формировать
библиотеку ClusterJ в вашем проекте.clusterj, кроме того,
libndbclient должен быть в каталоге,
определенном by java.library.path.
Раздел 4.2.2.1
предоставляет больше информации об этих требованиях.
4.2.2.1. Выполнение приложений ClusterJ и сессий
share/mysql/java/ в каталоге
установки MySQL. Выполняя приложение ClusterJ, необходимо установить
classpath на эти файлы. Кроме того, необходимо установить переменную
java.library.path, чтобы указать на каталог,
содержащий библиотеку ndbclient, обычно это
lib/mysql в каталоге установки MySQL.
Таким образом вы могли бы выполнить программу ClusterJ
MyClusterJApp способом, подобным тому,
что показан здесь:
shell>
java -classpath /usr/local/mysql/share/mysql/java/clusterj.jar \
-Djava.library.path=/usr/local/mysql/lib MyClusterJApp
libndbclient зависят от того, как программное
обеспечение NDB Cluster было установлено. Посмотрите
Installation Layouts.ndbclient
определен для версии. Это позволяет поддержать стабильный API, так,
чтобы запросы, написанные для него, используя данную версию NDB, продолжили
работать после модернизации кластера к новой версии.SessionFactory это источник всех сессий
ClusterJ, которые используют данный NDB Cluster. Обычно есть только одна
SessionFactory на NDB Cluster на
Java Virtual Machine.SessionFactory
может формироваться, устанавливая одно или более свойств.
Предпочтительный способ сделать это, поместить их в файл:
com.mysql.clusterj.connectstring=localhost:1186
com.mysql.clusterj.database=mydb
.properties.
Для приложений ClusterJ обычно файл называют
clusterj.properties.Properties:
File propsFile = new File("clusterj.properties");
InputStream inStream = new FileInputStream(propsFile);
Properties props = new Properties();
props.load(inStream);
Properties props = new Properties();
props.put("com.mysql.clusterj.connectstring", "localhost:1186");
props.put("com.mysql.clusterj.database", "mydb");
SessionFactory и затем от этого экземпляр
Session
. Для этого вы используете метод
SessionFactory
getSession():
SessionFactory factory = ClusterJHelper.getSessionFactory(props);
Session session = factory.getSession();
com.mysql.clusterj.connectstring и
com.mysql.clusterj.database
(и эти свойства, наряду с
com.mysql.clusterj.max.transactions,
не могут быть изменены после старта
SessionFactory).
Для полного списка доступных свойств
SessionFactory и значений см.
com.mysql.clusterj.Constants.
Session не должны быть разделены среди потоков. Каждый поток в
вашем запросе должен использовать свой собственный экземпляр
Session
.com.mysql.clusterj.connectstring
мы используем по умолчанию строку подключения NDB Cluster
localhost:1186 (см.
NDB Cluster Connection Strings). Для значения
com.mysql.clusterj.database мы используем
mydb в этом примере, но это значение
может быть названием любой базы данных, содержащей таблицы
NDB. Для листинга всех
свойств
SessionFactory, которые могут быть
установлены этим способом, см.
com.mysql.clusterj.Constants.
com.mysql.clusterj.connection.reconnect.timeout
было установлено в положительное число, которое определяет тайм-аут
повторного соединения в секундах.State в
SessionFactory
с OPEN на
RECONNECTING,
SessionFactory
тогда ждет от приложения закрытия всех сессий, а затем пытается повторно
подключить приложение к кластеру NDB, закрывая все связи в пуле связи и
воссоздавая пул, используя его оригинальные свойства.
После восстановления всех связей, State в
SessionFactory снова
OPEN и приложение может теперь получить сессии.
SessionFactory.getState() вернет
State из
SessionFactory,
который OPEN,
RECONNECTING или
CLOSED. Попытка получить сессию, когда
State не
OPEN приведет к
ClusterJUserException с сообщением
Session factory is not open.
com.mysql.clusterj.connection.reconnect.timeout,
SessionFactory завершает любые открытые
сессии насильственно (что могло бы привести к потере ресурсов), затем делает
попытку повторного соединения.com.mysql.clusterj.connection.reconnect.timeout
не было установлено или установлено в ноль (это также имеет место для более
старых выпусков NDB Cluster, которые не поддерживают автоматическую
функцию повторного соединения).SessionFactory. Рестарт
SessionFactory
может быть автоматической функцией или ручным вмешательством.
В любом случае код должен ждать, пока все сессии не были закрыты (то есть,
метод
getConnectionPoolSessionCounts() в интерфейсе
SessionFactory вернет нули для всех объединенных связей). Тогда
SessionFactory может быть закрыт и вновь открыт, и приложение
сможет получить сессии снова.SessionFactory.reconnect(int timeout),
это вызывает процесс повторного соединения, описанный выше, но использует
параметр timeout метода
reconnect() как ограничение по времени для того,
чтобы закрыть все открытые сессии.logging.properties и могут быть изменены там:
INFO для всех классов.java.util.logging.FileHandler.java.util.logging.FileHandler =
FINESTjava.util.logging.SimpleFormatter
для обработчика.target в соответствии с текущим рабочим
каталогом и имена файлов находятся, обычно, в образце
log,
где NumNum это уникальное число для
решения конфликтов имени файла (см. документацию Java на
java.util.logging.FileHandler).logging.properties
расположен по умолчанию в текущем рабочем каталоге, но местоположение может
быть изменено, определив системное свойство
java.util.logging.config.file,
когда вы запускаете Java.4.2.2.2. Создание таблиц
employee, которая
соответствует этому интерфейсу, используя следующий
CREATE TABLE, в клиентском
приложении MySQL, таком как
mysql.
CREATE TABLE employee (id INT NOT NULL PRIMARY KEY,
first VARCHAR(64) DEFAULT NULL,
last VARCHAR(64) DEFAULT NULL,
municipality VARCHAR(64) DEFAULT NULL,
started DATE DEFAULT NULL,
ended DATE DEFAULT NULL,
department INT NOT NULL DEFAULT 1,
UNIQUE KEY idx_u_hash (last,first USING HASH),
KEY idx_municipality (municipality)) ENGINE=NDBCLUSTER;
4.2.2.3. Аннотации
@PersistenceCapable(table="employee")
@Index(name="idx_uhash")
public interface Employee {
@PrimaryKey
int getId();
void setId(int id);
String getFirst();
void setFirst(String first);
String getLast();
void setLast(String last);
@Column(name="municipality")
@Index(name="idx_municipality")
String getCity();
void setCity(String city);
Date getStarted();
void setStarted(Date date);
Date getEnded();
void setEnded(Date date);
Integer getDepartment();
void setDepartment(Integer department);
}
id,
first, last,
municipality,
started, ended и
department. Аннотация
@PersistenceCapable(table="employee")
используется, чтобы позволить ClusterJ знать, которую таблицу базы данных
Employee отобразить (в этом случае таблицу
employee). Аннотация
@Column используется потому, что имя свойства
city, подразумеваемое методами
getCity() и
setCity(), отличается от отображенного имени
столбца municipality. Аннотации
@PrimaryKey и
@Index сообщают ClusterJ об индексах в
таблице базы данных.
newInstance(), ClusterJ создает класс реализации для
интерфейса Employee,
этот класс хранит значения во внутреннем множестве объекта.com.mysql.clusterj.annotation и
импортированы примерно так:
import com.mysql.clusterj.annotation.Column;
import com.mysql.clusterj.annotation.Index;
import com.mysql.clusterj.annotation.PersistenceCapable;
import com.mysql.clusterj.annotation.PrimaryKey;
4.2.2.4. Основные операции ClusterJ
Employee.
Это может быть достигнуто, вызывая метод Session
newInstance():
Employee newEmployee = session.newInstance(Employee.class);
Employee
соответствующие желаемым столбцам таблицы
employee. Например, следующее задаст свойства
id, firstName,
lastName и started.
emp.setId(988);
newEmployee.setFirstName("John");
newEmployee.setLastName("Jones");
newEmployee.setStarted(new Date());
Employee, вставляя новую строку, содержащую
требуемые значения, которые будут вставлены в таблицу
employee:
session.persist(newEmployee);
id уже есть в базе данных, метод
persist() терпит неудачу. Если autocommit=off
и строка с тем же самым id уже есть в базе
данных, метод persist() достигает цели, но
последующий commit() терпит неудачу.savePersistent() вместо
persist(). Метод
savePersistent()
обновляет существующий экземпляр или создает новый экземпляр по мере
необходимости, не бросая исключение.0 для целочисленных типов,
0.0 для числовых типов и
null для ссылочных типов).NDB, используя метод
Session
find():
Employee theEmployee = session.find(Employee.class, 988);
SELECT * FROM employee WHERE id = 988.find() может взять объектный массив в
качестве ключа, где компоненты массива используются, чтобы представлять
столбцы первичного ключа в том порядке, в каком они были объявлены.
Кроме того, запросы оптимизированы, чтобы обнаружить, определяются ли столбцы
первичного ключа как часть условий запроса, и если это так, поиск первичного
ключа или просмотр выполняются как стратегия осуществления запроса.theEmployee, используйте метод
set*(), имя которого соответствует названию того
столбца. Например, чтобы обновить дату
started для
Employee, используйте метод
Employee
setStarted():
theEmployee.setStarted(new Date(getMillisFor(2010, 01, 04)));
getMillisFor(), который определяется как
показано здесь в файле
AbstractClusterJModelTest.java (лежит в
каталоге
storage/ndb/clusterj/clusterj-test/src/main/java/testsuite/clusterj
исходного дерева NDB Cluster):
/** Convert year, month, day into milliseconds after the Epoch, UTC.
* Set hours, minutes, seconds, and milliseconds to zero.
* @param year the year
* @param month the month (0 for January)
* @param day the day of the month
* @return
*/
protected static long getMillisFor(int year, int month, int day) {
Calendar calendar = Calendar.getInstance();
calendar.clear();
calendar.set(Calendar.YEAR, year);
calendar.set(Calendar.MONTH, month);
calendar.set(Calendar.DATE, day);
calendar.set(Calendar.HOUR, 0);
calendar.set(Calendar.MINUTE, 0);
calendar.set(Calendar.SECOND, 0);
calendar.set(Calendar.MILLISECOND, 0);
long result = calendar.getTimeInMillis();
return result;
}
Employee:
theEmployee.setDepartment(3);
Session
updatePersistent():
session.updatePersistent(theEmployee);
deletePersistent()
из Session. В этом примере мы находим
сотрудника, ID которого равняется 13, затем удаляем эту строку из таблицы
employee:
Employee exEmployee = session.find(Employee.class, 13);
session.deletePersistent(exEmployee);'
System.out.println("Deleted employee named " + exEmployee.getFirst()
+ " " + exEmployee.getLast() + ".");
deletePersistentAll().
Первый вариант
этого метода действует на Class.
Например, следующий запрос удаляет все строки из таблицы
employee и вернет количество удаленных строк,
как показано здесь:
int numberDeleted = session.deletePersistentAll(Employee);
System.out.println("There used to be "+ numberDeleted +
" employees, but now there are none.");
deletePersistentAll() эквивалентно
SQL-оператору DELETE FROM employee в клиенте
mysql.deletePersistentAll() может также
использоваться, чтобы удалить коллекцию строк, как показано в этом примере:
// Assemble the collection of rows to be deleted...
List<Employee> redundancies = new ArrayList<Employee> ();
for (int i = 1000; i < 2000; i += 100) {
Employee redundant = session.newInstance(Employee.class);
redundant.setId(i);
redundancies.add(redundant);
}
numberDeleted = session.deletePersistentAll(redundancies);
System.out.println("Deleted " + numberDeleted + " rows.");
QueryBuilder
используется, чтобы создавать запросы. Процесс начинается с получения
экземпляра
QueryBuilder, который поставляется
текущим
Session, мы можем тогда получить
QueryDefinition:
QueryBuilder builder = session.getQueryBuilder();
QueryDomainType<Employee> domain = builder.createQueryDefinition(Employee.class);
department с постоянной величиной
8.
domain.where(domain.get("department").equal(domain.param("department"));
Query<Employee> query = session.createQuery(domain);
query.setParameter("department", 8);
Query
getResultList();
List<Employee> results = query.getResultList();
List, который
можно повторить, чтобы восстановить и обработать строки обычным способом.
Transaction может произвольно использоваться
для связанных транзакций с помощью следующих методов:
begin(): Начните транзакцию.
commit(): Передайте транзакцию.
rollback(): Отмените транзакцию.
Transaction чтобы проверять, активна ли транзакция (через
метод
isActive()), работа с флагом
rollback-only (через методы
getRollbackOnly() и
setRollbackOnly()).Transaction,
методы в Session, влияющие на базу данных
(например, persist(),
deletePersistent(),
updatePersistent()),
автоматически приложены в транзакции базы данных.
4.2.2.5. Отображение типов данных между MySQL и Java
UNSIGNED нужно избежать в схемах таблицы,
если это возможно.Тип данных Java
Тип данных MySQL boolean,
BooleanBIT(1)byte,
ByteBIT(1) to
BIT(8),
TINYINTshort,
ShortBIT(1) to
BIT(16),
SMALLINT,
YEARint,
IntegerBIT(1) to
BIT(32),
INTlong,
LongBIT(1) to
BIT(64),
BIGINT,
BIGINT UNSIGNEDfloat,
FloatFLOATdouble,
DoubleDOUBLEjava.math.BigDecimalNUMERIC,
DECIMALjava.math.BigIntegerNUMERIC (precision = 0),
DECIMAL (precision = 0)
Тип данных Java
Тип данных MySQL
Java.util.DateDATETIME,
TIMESTAMP,
TIME,
DATE
Java.sql.DateDATE
Java.sql.TimeTIME
Java.sql.TimestampDATETIME,
TIMESTAMP
YEAR в Java-тип
short (или
java.lang.Short)
как показано в первой таблице в этой секции.java.util.Date
представляет дату и время, подобно пути, которым Unix делает это, но с
большей точностью и большим диапазоном. Где Unix представляет момент времени
как 32-битное число со знаком секунд, начиная с Unix Epoch (01 January 1970),
Java использует 64-битное число со знаком миллисекунд, начиная с Epoch.
Тип данных Java
Тип данных MySQL
StringCHAR,
VARCHAR,
TEXTbyte[]BINARY,
VARBINARY,
BLOB
BINARY,
VARBINARY или
BLOB к байтовым массивам Java.
Данные представлены приложению точно как это сохранено.
4.2.3. Применение Connector/J с NDB Cluster
jdbc:mysql:loadbalance:// URL (см.
Configuration Properties for Connector/J),
с которым можно использовать в своих интересах способность соедиениться с
многократными серверами MySQL, чтобы достигнуть
выравнивания нагрузки и отказоустойчивости.4.3. ClusterJ API
4.3.1. com.mysql.clusterj
4.3.1.1. Главные интерфейсы
com.mysql.clusterj.SessionFactory,
com.mysql.clusterj.Session,
com.mysql.clusterj.Transaction,
com.mysql.clusterj.query.QueryBuilder и
com.mysql.clusterj.Query.
Bootstrapping класс-помощник
com.mysql.clusterj.ClusterJHelper содержит методы для создания
com.mysql.clusterj.SessionFactory.
Bootstrapping это процесс
идентификации NDB Cluster и получения SessionFactory для использования с
кластером. Есть один SessionFactory на кластер на Java VM.4.3.1.1.1. SessionFactory
com.mysql.clusterj.SessionFactory формируется через свойства,
которые определяют кластер NDB, с которым соединяется приложение:
File propsFile = new File("clusterj.properties");
InputStream inStream = new FileInputStream(propsFile);
Properties props = new Properties();
props.load(inStream);
SessionFactory sessionFactory = ClusterJHelper.getSessionFactory(props);
com.mysql.clusterj.Session представляет отдельную связь
пользователя с кластером. Это содержит методы для:
Session session = sessionFactory.getSession();
Employee existing = session.find(Employee.class, 1);
if (existing != null) {
session.remove(existing);
}
Employee newemp = session.newInstance(Employee.class);
newemp.initialize(2, "Craig", 15, 146000.00);
session.persist(newemp);
com.mysql.clusterj.Transaction позволяет пользователям объединять
многократные операции в единую транзакцию базы данных. Это содержит методы:
Transaction tx = session.currentTransaction();
tx.begin();
Employee existing = session.find(Employee.class, 1);
Employee newemp = session.newInstance(Employee.class);
newemp.initialize(2, "Craig", 146000.00);
session.persist(newemp);
tx.commit();
com.mysql.clusterj.query.QueryBuilder
позволяет пользователям строить запросы. Это содержит методы:
QueryBuilder builder = session.getQueryBuilder();
QueryDomainType<Employee> qemp = builder.createQueryDefinition(Employee.class);
Predicate service = qemp.get("yearsOfService").greaterThan(qemp.param("service"));
Predicate salary = qemp.get("salary").lessEqual(qemp.param("salaryCap"));
qemp.where(service.and(salary));
Query<Employee> query = session.createQuery(qemp);
query.setParameter("service", 10);
query.setParameter("salaryCap", 180000.00);
List<Employee> results = query.getResultList();
4.3.1.2. ClusterJDatastoreException
4.3.1.2.1. Резюме
public class ClusterJDatastoreException
extends, ClusterJException {
// Public Constructorspublic
ClusterJDatastoreException(String
message);
public
ClusterJDatastoreException(String msg
,
int code,
int mysqlCode,
int status,
int classification);
public
ClusterJDatastoreException(String message
,
Throwable t);
public
ClusterJDatastoreException(Throwable t
);
// Public Methodspublic int
getClassification();
public int getCode();
public int getMysqlCode();
public int getStatus
();
}
printStackTraceaddSuppressed
, fillInStackTrace
, getCause
, getLocalizedMessage
, getMessage
, getStackTrace
, getSuppressed
, initCause
, setStackTrace
, toStringequals
, getClass
, hashCode
, notify
, notifyAll
, wait
4.3.1.2.2. getClassification()
public int getClassification();
4.3.1.2.3. getCode()
public int getCode();
4.3.1.2.4. getMysqlCode()
public int getMysqlCode();
4.3.1.2.5 getStatus()
public int getStatus();
4.3.1.3. ClusterJDatastoreException.Classification
4.3.1.3.1 Резюме
public static final
class ClusterJDatastoreException.Classification
extends, Enum<Classification> {
// Public Static Fieldspublic
static final Classification
ApplicationError ;
public static
final Classification
ConstraintViolation ;
public static
final Classification
FunctionNotImplemented ;
public static
final Classification
InsufficientSpace ;
public static
final Classification
InternalError ;
public static
final Classification
InternalTemporary ;
public static
final Classification
NoDataFound ;
public static
final Classification
NoError ;
public static
final Classification
NodeRecoveryError ;
public static
final Classification
NodeShutdown ;
public static
final Classification
OverloadError ;
public static
final Classification
SchemaError ;
public static
final Classification
SchemaObjectExists ;
public static
final Classification
TemporaryResourceError ;
public static
final Classification
TimeoutExpired ;
public static
final Classification
UnknownErrorCode ;
public static
final Classification
UnknownResultError ;
public static
final Classification
UserDefinedError ;
// Public Static Methodspublic static
Classification lookup(int value
);
public static Classification
valueOf(String name);
public static
Classification[] values();
}
compareTo
, equals
, getDeclaringClass
, hashCode
, Имя
, ordinal
, toString
, valueOfgetClass
, notify
, notifyAll
, wait
4.3.1.3.2. lookup(int)
public static Classification
lookup(int value);
Параметр
Описание value
Классификация возвращена getClassification(). return
Классификация для ошибки.
4.3.1.4. ClusterJException
com.mysql.clusterj.ClusterJFatalUserException.
com.mysql.clusterj.ClusterJUserException.
com.mysql.clusterj.ClusterJDatastoreException.
com.mysql.clusterj.ClusterJFatalInternalException.4.3.1.4.1. Резюме
public class ClusterJException
extends, RuntimeException {
// Public Constructorspublic
ClusterJException(String message
);
public ClusterJException
(String message,
Throwable t);
public
ClusterJException(Throwable t);
// Public Methodspublic
synchronized void printStackTrace(
PrintStream s);
}
com.mysql.clusterj.ClusterJDatastoreException
,
com.mysql.clusterj.ClusterJFatalException,
com.mysql.clusterj.ClusterJUserException
.addSuppressed
, fillInStackTrace
, getCause
, getLocalizedMessage
, getMessage
, getStackTrace
, getSuppressed
, initCause
, printStackTrace
, setStackTrace
, toStringequals
, getClass
, hashCode
, notify
, notifyAll
, wait
4.3.1.5. ClusterJFatalException
4.3.1.5.1. Резюме
public class ClusterJFatalException
extends, ClusterJException {
// Public Constructorspublic
ClusterJFatalException(String string
);
public ClusterJFatalException(String
string,
Throwable t);
public
ClusterJFatalException(Throwable t
);
}
com.mysql.clusterj.ClusterJFatalInternalException
,
com.mysql.clusterj.ClusterJFatalUserException
printStackTraceaddSuppressed
, fillInStackTrace
, getCause
, getLocalizedMessage
, getMessage
, getStackTrace
, getSuppressed
, initCause
, setStackTrace
, toStringequals
, getClass
, hashCode
, notify
, notifyAll
, wait
4.3.1.6. ClusterJFatalInternalException
4.3.1.6.1. Резюме
public class
ClusterJFatalInternalException extends,
ClusterJFatalException
{
// Public Constructors
public ClusterJFatalInternalException(
String string
);
public ClusterJFatalInternalException(
String string,
Throwable t);
public
ClusterJFatalInternalException(Throwable
t);
}
printStackTraceaddSuppressed
, fillInStackTrace
, getCause
, getLocalizedMessage
, getMessage
, getStackTrace
, getSuppressed
, initCause
, setStackTrace
, toStringequals
, getClass
, hashCode
, notify
, notifyAll
, wait/p>
4.3.1.7. ClusterJFatalUserException
4.3.1.7.1. Резюме
public class
ClusterJFatalUserException extends,
ClusterJFatalException {
// Public Constructors
public ClusterJFatalUserException(
String string
);
public ClusterJFatalUserException(
String string,
Throwable t);
public ClusterJFatalUserException(
Throwable t);
}
printStackTraceaddSuppressed
, fillInStackTrace
, getCause
, getLocalizedMessage
, getMessage
, getStackTrace
, getSuppressed
, initCause
, setStackTrace
, toStringequals
, getClass
, hashCode
, notify
, notifyAll
, wait4.3.1.8. ClusterJHelper
4.3.1.8.1. Резюме
public class ClusterJHelper
{
// Public Constructorspublic
ClusterJHelper();
// Public Static Methodspublic static
boolean getBooleanProperty(String
propertyName,
String def);
public static T
getServiceInstance(Class<T> cls
);
public static T
getServiceInstance(Class<T> cls
,
ClassLoader loader);
public static T
getServiceInstance(Class<T> cls
,
String implementationClassName
);
public static T
getServiceInstance(Class<T> cls
,
String implementationClassName,
ClassLoader loader);
public static List<T>
getServiceInstances(Class<T>
cls,
ClassLoader loader,
StringBuffer errorMessages);
public static SessionFactory
getSessionFactory(Map props
);
public static SessionFactory
getSessionFactory(Map props
,
ClassLoader loader);
public static String
getStringProperty(String propertyName
,
String def);
public static Dbug newDbug
();
}
equals
, getClass
, hashCode
, notify
, notifyAll
, toString
, wait
4.3.1.8.2. getBooleanProperty(String, String)
public static boolean
getBooleanProperty(String propertyName
,
String def);Параметр
Описание propertyName
Название значения def
По умолчанию, если свойство не установлено return
Системное свойство, если это установлено через -D или
системную окружающую среду
4.3.1.8.3. getServiceInstance(Class<T>)
public static T
getServiceInstance(Class<T> cls
);
Параметр
Описание cls
Класс фабрики return
Сервисный экземпляр
4.3.1.8.4. getServiceInstance(Class<T>, ClassLoader)
public static T
getServiceInstance(Class<T> cls
,
ClassLoader loader);Параметр
Описание cls
Класс фабрики loader
Загрузчик класса для фабричного внедрения return
Сервисный экземпляр
4.3.1.8.5. getServiceInstance(Class<T>, String)
public static T
getServiceInstance(Class<T> cls
,
String implementationClassName);Параметр
Описание cls
implementationClassName
return
Экземпляр внедрения для обслуживания
4.3.1.8.6. getServiceInstance(Class<T>, String, ClassLoader)
public static T
getServiceInstance(Class<T> cls
,
String implementationClassName,
ClassLoader loader);Параметр
Описание cls
implementationClassName
Название класса реализации, чтобы загрузить loader
ClassLoader, чтобы найти обслуживание return
Экземпляр внедрения для обслуживания
4.3.1.8.7. getServiceInstances(Class<T>, ClassLoader, StringBuffer)
public static List<T>
getServiceInstances(Class<T> cls
,
ClassLoader loader,
StringBuffer errorMessages);Параметр
Описание cls
Класс фабрики loader
Загрузчик класса для фабричного внедрения errorMessages
Буфер для сообщений об ошибках return
Сервисный экземпляр
4.3.1.8.8. getSessionFactory(Map)
public static SessionFactory
getSessionFactory(Map props
);
Параметр
Описание props
Свойства фабрики сессии return
Фабрика сессии
ClusterFatalUserException
4.3.1.8.9. getSessionFactory(Map, ClassLoader)
public static SessionFactory
getSessionFactory(Map props
,
ClassLoader loader);Параметр
Описание props
свойства для фабрики loader
загрузчик класса для фабричного внедрения return
фабрика сессии
ClusterFatalUserException
4.3.1.8.10. getStringProperty(String, String)
public static String
getStringProperty(String propertyName
,
String def);Параметр
Описание propertyName
название значения def
по умолчанию, если свойство не установлено return
системное свойство, если это установлено через -D или
системную окружающую среду
4.3.1.8.11. newDbug()
public static Dbug
newDbug();
Параметр
Описание return
новый экземпляр Dbug
4.3.1.9. ClusterJUserException
4.3.1.9.1. Резюме
public class
ClusterJUserException extends,
ClusterJException
{
// Public Constructors
public ClusterJUserException(
String message);
public
ClusterJUserException(String message
,
Throwable
t);
public
ClusterJUserException(Throwable
t);
}
printStackTraceaddSuppressed
, fillInStackTrace
, getCause
, getLocalizedMessage
, getMessage
, getStackTrace
, getSuppressed
, initCause
, setStackTrace
, toStringequals
, getClass
, hashCode
, notify
, notifyAll
, wait4.3.1.10. ColumnMetadata
public interface ColumnMetadata
{
// Public Methodspublic abstract
String charsetName();
public abstract ColumnType
columnType();
public abstract boolean
isPartitionKey();
public abstract boolean
isPrimaryKey();
public abstract Class<?>
javaType();
public abstract int
maximumLength();
public abstract String
name();
public abstract boolean
nullable();
public abstract int number
();
public abstract int
precision();
public abstract int
scale();
}
4.3.1.10.1.
charsetName()
public abstract String
charsetName();
Параметр
Описание return
имя набора символов
4.3.1.10.2.
columnType()
public abstract ColumnType
columnType();
Параметр
Описание return
тип столбца
4.3.1.10.3. isPartitionKey()
public abstract boolean
isPartitionKey();
Параметр
Описание return
true, если это столбец ключа разделения
4.3.1.10.4.
isPrimaryKey()
public abstract boolean
isPrimaryKey();
Параметр
Описание return
true, если это столбец первичного ключа
4.3.1.10.5.
javaType()
public abstract Class<?>
javaType();
Параметр
Описание return
java-тип столбца.
4.3.1.10.6.
maximumLength()
public abstract int
maximumLength();
Параметр
Описание return
максимальное количество байтов, которые могут быть сохранены в столбце
4.3.1.10.7. name()
public abstract String
name();
Параметр
Описание return
название столбца.
4.3.1.10.8.
nullable()
public abstract boolean
nullable();
Параметр
Описание return
nullable ли этот столбец
4.3.1.10.9. number()
public abstract int
number();
Параметр
Описание return
номер столбца.
4.3.1.10.10. precision()
public abstract int
precision();
Параметр
Описание return
точность столбца.
4.3.1.10.11. scale()
public
abstract int scale();
Параметр
Описание return
масштаб столбца
4.3.1.11. ColumnType
4.3.1.11.1 Резюме
public final class
ColumnType extends,
Enum<ColumnType>
{
// Public Static Fields
public static
final ColumnType
Bigint ;
public static
final ColumnType
Bigunsigned ;
public
static final
ColumnType Binary ;
public
static final
ColumnType Bit ;
public
static final
ColumnType Blob ;
public
static final
ColumnType Char ;
public
static final
ColumnType Date ;
public
static final
ColumnType Datetime ;
public
static final
ColumnType Datetime2 ;
public
static final
ColumnType Decimal ;
public
static final
ColumnType
Decimalunsigned ;
public static
final ColumnType
Double ;
public static
final ColumnType
Float ;
public static
final ColumnType
Int ;
public static
final ColumnType
Longvarbinary ;
public
static final
ColumnType
Longvarchar ;
public static
final ColumnType
Mediumint ;
public
static final
ColumnType
Mediumunsigned ;
public static
final ColumnType
Olddecimal ;
public
static final
ColumnType
Olddecimalunsigned ;
public static
final ColumnType
Smallint ;
public
static final
ColumnType
Smallunsigned ;
public static
final ColumnType
Text ;
public static
final ColumnType
Time ;
public static
final ColumnType
Time2 ;
public static
final ColumnType
Timestamp ;
public
static final
ColumnType
Timestamp2 ;
public static
final ColumnType
Tinyint ;
public static
final ColumnType
Tinyunsigned ;
public
static final
ColumnType Undefined ;
public
static final
ColumnType Unsigned ;
public
static final
ColumnType Varbinary ;
public
static final
ColumnType Varchar ;
public
static final
ColumnType Year ;
// Public Static Methodspublic static
ColumnType valueOf(
String name);
public static ColumnType[]
values();
}
compareTo
, equals
, getDeclaringClass
, hashCode
, Имя
, ordinal
, toString
, valueOfgetClass
, notify
, notifyAll
, wait4.3.1.12. Constants
4.3.1.12.1. Резюме
public interface
Constants
{
// Public Static Fields
public static
final String
DEFAULT_PROPERTY_CLUSTER_BYTE_BUFFER_POOL_SIZES
= "256, 10240, 102400, 1048576";
public
static final
int
DEFAULT_PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_BATCH_SIZE
= 10;
public static
final long
DEFAULT_PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_START
= 1L;
public
static final
long
DEFAULT_PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_STEP
= 1L;
public
static final
int
DEFAULT_PROPERTY_CLUSTER_CONNECT_DELAY
= 5;
public
static final
int
DEFAULT_PROPERTY_CLUSTER_CONNECT_RETRIES
= 4;
public
static final
int
DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER
= 20;
public
static final <
span>int
DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE
= 30;
public
static final
int
DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_MGM
= 30000;
public
static final
int
DEFAULT_PROPERTY_CLUSTER_CONNECT_VERBOSE
= 0;
public
static final
String
DEFAULT_PROPERTY_CLUSTER_DATABASE
= "test";
public
static final
int
DEFAULT_PROPERTY_CLUSTER_MAX_TRANSACTIONS
= 4;
public
static final
int
DEFAULT_PROPERTY_CONNECTION_POOL_RECV_THREAD_ACTIVATION_THRESHOLD
= 8;
public
static final
int
DEFAULT_PROPERTY_CONNECTION_POOL_SIZE = 1
;
public static
final int
DEFAULT_PROPERTY_CONNECTION_RECONNECT_TIMEOUT
= 0;
public
static final
String
ENV_CLUSTERJ_LOGGER_FACTORY_NAME
= "CLUSTERJ_LOGGER_FACTORY";
public
static final
String
PROPERTY_CLUSTER_BYTE_BUFFER_POOL_SIZES
= "com.mysql.clusterj.byte.buffer.pool.sizes"
;
public static
final String
PROPERTY_CLUSTER_CONNECTION_SERVICE
= "com.mysql.clusterj.connection.service";
public
static final
String
PROPERTY_CLUSTER_CONNECTSTRING
= "com.mysql.clusterj.connectstring";
public
static final
String
PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_BATCH_SIZE
= "com.mysql.clusterj.connect.autoincrement.batchsize";
public
static final
String
PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_START
= "com.mysql.clusterj.connect.autoincrement.offset"
;public
static final
String
PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_STEP
= "com.mysql.clusterj.connect.autoincrement.increment";
public
static final
String
PROPERTY_CLUSTER_CONNECT_DELAY
= "com.mysql.clusterj.connect.delay";
public
static final
String
PROPERTY_CLUSTER_CONNECT_RETRIES
= "com.mysql.clusterj.connect.retries";
public
static final
String
PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER
= "com.mysql.clusterj.connect.timeout.after"
;
public static
final String
PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE
= "com.mysql.clusterj.connect.timeout.before";
public
static final
String
PROPERTY_CLUSTER_CONNECT_TIMEOUT_MGM
= "com.mysql.clusterj.connect.timeout.mgm";
public
static final
String
PROPERTY_CLUSTER_CONNECT_VERBOSE
= "com.mysql.clusterj.connect.verbose";
public
static final
String
PROPERTY_CLUSTER_DATABASE
= "com.mysql.clusterj.database";
public
static final
String
PROPERTY_CLUSTER_MAX_TRANSACTIONS
= "com.mysql.clusterj.max.transactions";
public
static final
String
PROPERTY_CONNECTION_POOL_NODEIDS
= "com.mysql.clusterj.connection.pool.nodeids";
public
static final
String
PROPERTY_CONNECTION_POOL_RECV_THREAD_ACTIVATION_THRESHOLD
= "com.mysql.clusterj.connection.pool.recv.thread.activation.threshold"
;
public static
final String
PROPERTY_CONNECTION_POOL_RECV_THREAD_CPUIDS
= "com.mysql.clusterj.connection.pool.recv.thread.cpuids";
public
static final
String
PROPERTY_CONNECTION_POOL_SIZE
= "com.mysql.clusterj.connection.pool.size";
public
static final
String
PROPERTY_CONNECTION_RECONNECT_TIMEOUT
= "com.mysql.clusterj.connection.reconnect.timeout";
public
static final
String
PROPERTY_DEFER_CHANGES
= "com.mysql.clusterj.defer.changes";
public
static final
String
PROPERTY_JDBC_DRIVER_NAME
= "com.mysql.clusterj.jdbc.driver";
public
static final
String
PROPERTY_JDBC_PASSWORD
= "com.mysql.clusterj.jdbc.password";
public
static final
String
PROPERTY_JDBC_URL
= "com.mysql.clusterj.jdbc.url";
public
static final
String
PROPERTY_JDBC_USERNAME
= "com.mysql.clusterj.jdbc.username";
public
static final
String
SESSION_FACTORY_SERVICE_CLASS_NAME
= "com.mysql.clusterj.SessionFactoryService";
public
static final
String
SESSION_FACTORY_SERVICE_FILE_NAME
= "META-INF/services/com.mysql.clusterj.SessionFactoryService"
;
}
4.3.1.12.2. DEFAULT_PROPERTY_CLUSTER_BYTE_BUFFER_POOL_SIZES
public static
final String
DEFAULT_PROPERTY_CLUSTER_BYTE_BUFFER_POOL_SIZES
= "256, 10240, 102400, 1048576";
4.3.1.12.3. DEFAULT_PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_BATCH_SIZE
public static
final int
DEFAULT_PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_BATCH_SIZE
= 10;
4.3.1.12.4. DEFAULT_PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_START
public static
final long
DEFAULT_PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_START
= 1L;
4.3.1.12.5. DEFAULT_PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_STEP
public static
final long
DEFAULT_PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_STEP
= 1L;
4.3.1.12.6. DEFAULT_PROPERTY_CLUSTER_CONNECT_DELAY
public static
final int
DEFAULT_PROPERTY_CLUSTER_CONNECT_DELAY
= 5;
4.3.1.12.7. DEFAULT_PROPERTY_CLUSTER_CONNECT_RETRIES
public static
final int
DEFAULT_PROPERTY_CLUSTER_CONNECT_RETRIES = 4
;
4.3.1.12.8. DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER
public static
final int
DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER
= 20;
4.3.1.12.9. DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE
public static
final int
DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE
= 30;
4.3.1.12.10. DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_MGM
public static
final int
DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_MGM
= 30000;
4.3.1.12.11. DEFAULT_PROPERTY_CLUSTER_CONNECT_VERBOSE
public static
final int
DEFAULT_PROPERTY_CLUSTER_CONNECT_VERBOSE
= 0;
4.3.1.12.12. DEFAULT_PROPERTY_CLUSTER_DATABASE
public static
final String
DEFAULT_PROPERTY_CLUSTER_DATABASE
= "test";
4.3.1.12.13. DEFAULT_PROPERTY_CLUSTER_MAX_TRANSACTIONS
public static
final int
DEFAULT_PROPERTY_CLUSTER_MAX_TRANSACTIONS
= 4;
4.3.1.12.14.
DEFAULT_PROPERTY_CONNECTION_POOL_RECV_THREAD_ACTIVATION_THRESHOLD
public static
final int
DEFAULT_PROPERTY_CONNECTION_POOL_RECV_THREAD_ACTIVATION_THRESHOLD
= 8;
4.3.1.12.15. DEFAULT_PROPERTY_CONNECTION_POOL_SIZE
public static
final int
DEFAULT_PROPERTY_CONNECTION_POOL_SIZE
= 1;
4.3.1.12.16. DEFAULT_PROPERTY_CONNECTION_RECONNECT_TIMEOUT
public static
final int
DEFAULT_PROPERTY_CONNECTION_RECONNECT_TIMEOUT
= 0;
4.3.1.12.17. ENV_CLUSTERJ_LOGGER_FACTORY_NAME
public static
final String
ENV_CLUSTERJ_LOGGER_FACTORY_NAME
= "CLUSTERJ_LOGGER_FACTORY";
4.3.1.12.18. PROPERTY_CLUSTER_BYTE_BUFFER_POOL_SIZES
public static
final String
PROPERTY_CLUSTER_BYTE_BUFFER_POOL_SIZES
= "com.mysql.clusterj.byte.buffer.pool.sizes";
4.3.1.12.19. PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_BATCH_SIZE
public static
final String
PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_BATCH_SIZE
= "com.mysql.clusterj.connect.autoincrement.batchsize";
4.3.1.12.20. PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_START
public static
final String
PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_START
= "com.mysql.clusterj.connect.autoincrement.offset";
4.3.1.12.21. PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_STEP
public static
final String
PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_STEP
= "com.mysql.clusterj.connect.autoincrement.increment";
4.3.1.12.22. PROPERTY_CLUSTER_CONNECT_DELAY
public static
final String
PROPERTY_CLUSTER_CONNECT_DELAY
= "com.mysql.clusterj.connect.delay";
4.3.1.12.23. PROPERTY_CLUSTER_CONNECT_RETRIES
public static
final String
PROPERTY_CLUSTER_CONNECT_RETRIES
= "com.mysql.clusterj.connect.retries";
4.3.1.12.24. PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER
public static
final String
PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER
= "com.mysql.clusterj.connect.timeout.after";
4.3.1.12.25. PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE
public static
final String
PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE
= "com.mysql.clusterj.connect.timeout.before";
4.3.1.12.26. PROPERTY_CLUSTER_CONNECT_TIMEOUT_MGM
public static
final String
PROPERTY_CLUSTER_CONNECT_TIMEOUT_MGM
= "com.mysql.clusterj.connect.timeout.mgm";
4.3.1.12.27. PROPERTY_CLUSTER_CONNECT_VERBOSE
public static
final String
PROPERTY_CLUSTER_CONNECT_VERBOSE
= "com.mysql.clusterj.connect.verbose";
4.3.1.12.28. PROPERTY_CLUSTER_CONNECTION_SERVICE
public static
final String
PROPERTY_CLUSTER_CONNECTION_SERVICE
= "com.mysql.clusterj.connection.service";
4.3.1.12.29. PROPERTY_CLUSTER_CONNECTSTRING
public static
final String
PROPERTY_CLUSTER_CONNECTSTRING
= "com.mysql.clusterj.connectstring";
4.3.1.12.30. PROPERTY_CLUSTER_DATABASE
public static
final String
PROPERTY_CLUSTER_DATABASE
= "com.mysql.clusterj.database";
4.3.1.12.31. PROPERTY_CLUSTER_MAX_TRANSACTIONS
public static
final String
PROPERTY_CLUSTER_MAX_TRANSACTIONS
= "com.mysql.clusterj.max.transactions";
4.3.1.12.32. PROPERTY_CONNECTION_POOL_NODEIDS
public static
final String
PROPERTY_CONNECTION_POOL_NODEIDS
= "com.mysql.clusterj.connection.pool.nodeids";
4.3.1.12.33. PROPERTY_CONNECTION_POOL_RECV_THREAD_ACTIVATION_THRESHOLD
public static
final String
PROPERTY_CONNECTION_POOL_RECV_THREAD_ACTIVATION_THRESHOLD
= "com.mysql.clusterj.connection.pool.recv.thread.activation.threshold";
4.3.1.12.34. PROPERTY_CONNECTION_POOL_RECV_THREAD_CPUIDS
public static
final String
PROPERTY_CONNECTION_POOL_RECV_THREAD_CPUIDS
= "com.mysql.clusterj.connection.pool.recv.thread.cpuids";
4.3.1.12.35. PROPERTY_CONNECTION_POOL_SIZE
public static
final String
PROPERTY_CONNECTION_POOL_SIZE
= "com.mysql.clusterj.connection.pool.size";
4.3.1.12.36. PROPERTY_CONNECTION_RECONNECT_TIMEOUT
public static
final String
PROPERTY_CONNECTION_RECONNECT_TIMEOUT
= "com.mysql.clusterj.connection.reconnect.timeout";
4.3.1.12.37. PROPERTY_DEFER_CHANGES
public static
final String PROPERTY_DEFER_CHANGES
= "com.mysql.clusterj.defer.changes";
4.3.1.12.38. PROPERTY_JDBC_DRIVER_NAME
public static
final String
PROPERTY_JDBC_DRIVER_NAME
= "com.mysql.clusterj.jdbc.driver";
4.3.1.12.39. PROPERTY_JDBC_PASSWORD
public static
final String PROPERTY_JDBC_PASSWORD
= "com.mysql.clusterj.jdbc.password";
4.3.1.12.40. PROPERTY_JDBC_URL
public static
final String PROPERTY_JDBC_URL
= "com.mysql.clusterj.jdbc.url";
4.3.1.12.41. PROPERTY_JDBC_USERNAME
public static
final String PROPERTY_JDBC_USERNAME
= "com.mysql.clusterj.jdbc.username";
4.3.1.12.42. SESSION_FACTORY_SERVICE_CLASS_NAME
public static
final String
SESSION_FACTORY_SERVICE_CLASS_NAME
= "com.mysql.clusterj.SessionFactoryService";
4.3.1.12.43. SESSION_FACTORY_SERVICE_FILE_NAME
public static
final String
SESSION_FACTORY_SERVICE_FILE_NAME
= "META-INF/services/com.mysql.clusterj.SessionFactoryService";
4.3.1.13. Dbug
4.3.1.13.1. Резюме
public interface Dbug {
// Public Methodspublic abstract
Dbug append(String
fileName);
public abstract Dbug
debug(String string
);public abstract
Dbug debug(
String[] strings
);public abstract
Dbug flush();
public abstract String
get();
public abstract Dbug
output(String fileName
);
public abstract
void pop();
public abstract void
print(String keyword
,
String
message);
public abstract void
push();
public abstract void
push(String state
);
public abstract
void set();
public abstract void
set(String state
);
public abstract
Dbug trace();
}
4.3.1.13.2. append(String)
public abstract Dbug
append(String fileName);
Параметр
Описание fileName
название файла return
this
4.3.1.13.3. debug(String)
public abstract Dbug debug
(String string);
Параметр
Описание string
Разделенные запятой ключевые слова отладки return
this
4.3.1.13.4.
debug(String[])
public abstract Dbug debug
(String[] strings);
Параметр
Описание strings
ключевые слова отладки return
this
4.3.1.13.5. flush()
public abstract Dbug
flush();
Параметр
Описание return
this
4.3.1.13.6. get()
public abstract String
get();
Параметр
Описание return
текущее состояние
4.3.1.13.7. output(String)
public abstract Dbug
output(String fileName);
Параметр
Описание fileName
название файла return
this
4.3.1.13.8. pop()
public abstract void
pop();
4.3.1.13.9.
print(String, String)
public abstract void print
(String keyword,
String message);4.3.1.13.10. push()
public abstract void
push();
4.3.1.13.11. push(String)
public abstract void push
(String state);
Параметр
Описание state
новый статус
4.3.1.13.12. set()
public abstract void
set();
4.3.1.13.13. set(String)
public abstract void
set(String state);
Параметр
Описание state
новый статус
4.3.1.13.14. trace()
public abstract Dbug
trace();
Параметр
Описание return
this
4.3.1.14. DynamicObject
public abstract class
DynamicObject {
// Public Constructorspublic
DynamicObject();
// Public Methodspublic final
ColumnMetadata[] columnMetadata();
public final
DynamicObjectDelegate delegate();
public final void
delegate(DynamicObjectDelegate delegate
);
public Boolean found();
public final Object get
(int columnNumber);
public final void set
(int columnNumber,
Object value);
public String table();
}
equals
, getClass
, hashCode
, notify
, notifyAll
, toString
, wait
4.3.1.15. DynamicObjectDelegate
public interface DynamicObjectDelegate
{
// Public Methodspublic abstract
ColumnMetadata[] columnMetadata();
public abstract Boolean
found();
public abstract void found
(Boolean found);
public abstract Object
get(int columnNumber);
public abstract void
release();
public abstract void set
(int columnNumber,
Object value);
public abstract boolean
wasReleased();
}
4.3.1.16. LockMode
4.3.1.16.1. Резюме
public final class
LockMode extends, Enum<LockMode>
{
// Public Static Fieldspublic
static final LockMode
EXCLUSIVE ;
public static
final LockMode
READ_COMMITTED ;
public static
final LockMode SHARED
;
// Public Static Methodspublic static
LockMode valueOf(String name
);
public static LockMode[]
values();
}
compareTo
, equals
, getDeclaringClass
, hashCode
, Имя
, ordinal
, toString
, valueOfgetClass
, notify
, notifyAll
, wait4.3.1.17. Query
com.mysql.clusterj.Session.<T>createQuery(com.mysql.clusterj.query.QueryDefinition<T>)
.4.3.1.17.1. Резюме
public interface
Query<E> {
// Public Static Fields public
static final String
INDEX_USED
= "IndexUsed";
public static
final String SCAN_TYPE
= "ScanType";
public static
final String SCAN_TYPE_INDEX_SCAN
= "INDEX_SCAN";
public static
final String SCAN_TYPE_PRIMARY_KEY
= "PRIMARY_KEY";
public static
final String SCAN_TYPE_TABLE_SCAN
= "TABLE_SCAN";
public static
final String SCAN_TYPE_UNIQUE_KEY
= "UNIQUE_KEY";
// Public Methodspublic abstract
int deletePersistentAll();
public abstract Results<E>
execute(Object parameter
);
public abstract Results<E>
execute(Object[] parameters
);
public abstract Results<E>
execute(Map<String, ?>
parameters);
public abstract Map<String,
Object> explain();
public abstract List<E>
getResultList();
public abstract void
setLimits(long skip,
long limit);
public abstract void
setOrdering(Ordering ordering,
String[] orderingFields);
public abstract void
setParameter(String parameterName
,
Object value);
}
4.3.1.17.2. INDEX_USED
public static
final String INDEX_USED
= "IndexUsed";
4.3.1.17.3. SCAN_TYPE
public static
final String SCAN_TYPE
= "ScanType";
4.3.1.17.4. SCAN_TYPE_INDEX_SCAN
public static
final String SCAN_TYPE_INDEX_SCAN
= "INDEX_SCAN";
4.3.1.17.5. SCAN_TYPE_PRIMARY_KEY
public static
final String SCAN_TYPE_PRIMARY_KEY
= "PRIMARY_KEY";
4.3.1.17.6. SCAN_TYPE_TABLE_SCAN
public static
final String SCAN_TYPE_TABLE_SCAN
= "TABLE_SCAN";
4.3.1.17.7. SCAN_TYPE_UNIQUE_KEY
public static
final String SCAN_TYPE_UNIQUE_KEY
= "UNIQUE_KEY";
4.3.1.17.8. deletePersistentAll()
public abstract int
deletePersistentAll();
Параметр
Описание return
количество удаленных экземпляров
4.3.1.17.9. execute(Map<String, ?>)
public abstract Results<E>
execute(Map<String, ?>
parameters);
Параметр
Описание parameters
Параметры для запроса return
результат запроса
4.3.1.17.10. execute(Object...)
public abstract
Results<E> execute(Object[]
parameters);
Параметр
Описание parameters
Параметр для запроса return
Результат запроса
4.3.1.17.11. execute(Object)
public abstract Results<E>
execute(Object parameter
);
Параметр
Описание parameter
Параметр для запроса return
Результат запроса
4.3.1.17.12. explain()
public abstract Map<String,
Object> explain();
Параметр
Описание return
данные о выполнении этого запроса
ClusterJUserException
4.3.1.17.13. getResultList()
public abstract List<E>
getResultList();
Параметр
Описание return
Результат
ClusterJUserException
ClusterJDatastoreException4.3.1.17.14.
setLimits(long, long)
public abstract void
setLimits(long skip,
long limit);Параметр
Описание skip
сколько результатов пропустить limit
сколько результатов возвратить после пропуска, используйте
Long.MAX_VALUE, если нет ограничения.
4.3.1.17.15. setOrdering(Query.Ordering, String...)
public abstract void
setOrdering(Ordering ordering,
String[] orderingFields);Параметр
Описание ordering
Ordering.ASCENDING или Ordering.DESCENDING orderingFields
поля для сортировки
4.3.1.17.16.
setParameter(String, Object)
public abstract void
setParameter(String parameterName
,
Object value);Параметр
Описание parameterName
название параметра value
значение для параметра
4.3.1.18. Query.Ordering
4.3.1.18.1. Резюме
public static final
class Query.Ordering extends,
Enum<Ordering> {
// Public Static Fieldspublic
static final Ordering
ASCENDING ;
public static
final Ordering DESCENDING
;
// Public Static Methodspublic static
Ordering valueOf(String name
);
public static Ordering[]
values();
}
compareTo
, equals
, getDeclaringClass
, hashCode
, Имя
, ordinal
, toString
, valueOfgetClass
, notify
, notifyAll
, wait4.3.1.19. Results
4.3.1.19.1. Резюме
public interface
Results<E> extends,
Iterable<E> {
// Public Methodspublic abstract
Iterator<E> iterator();
}
4.3.1.19.2. iterator()
public abstract Iterator<E>
iterator();
iterator в интерфейсе
Iterable.Параметр
Описание return
итератор
4.3.1.20. Session
4.3.1.20.1. Резюме
public interface
Session extends, AutoCloseable {
// Public Methodspublic abstract
void close();
public abstract Query<T>
createQuery(QueryDefinition<T>
qd);
public abstract Transaction
currentTransaction();
public abstract void
deletePersistent(
Class<T> cls
,
Object key);
public abstract void
deletePersistent(Object instance
);public abstract
int deletePersistentAll(Class<T>
cls);
public abstract void
deletePersistentAll(Iterable<?>
instances);
public abstract T
find(Class<T> cls
,
Object key);
public abstract void
flush();
public abstract Boolean
found(Object instance
);public abstract
QueryBuilder getQueryBuilder();
public abstract boolean
isClosed();
public abstract T
load(T instance
);public abstract
T makePersistent(T
instance);
public abstract
Iterable<?>
makePersistentAll(
Iterable<?> instances);
public abstract void
markModified(Object instance
,
String
fieldName);
public abstract T
newInstance(Class<T> cls
);public abstract
T newInstance(Class<T>
cls,
Object key);
public abstract void
persist(Object instance
);public abstract
T release(T obj);
public abstract void
remove(Object instance
);public abstract
T savePersistent(T
instance);
public abstract
Iterable<?> savePersistentAll(
Iterable<?>
instances);
public abstract void
setLockMode(LockMode lockmode
);public abstract
void setPartitionKey(Class<?>
cls,
Object key);
public
abstract String
unloadSchema(Class<?> cls
);public abstract
void updatePersistent(Object
instance);
public abstract void
updatePersistentAll(Iterable<?>
instances);
}
4.3.1.20.2. close()
public abstract void
close();
close в интерфейсе
AutoCloseable.
4.3.1.20.3. createQuery(QueryDefinition<T>)
public abstract Query<T>
createQuery(QueryDefinition<T>
qd);
Параметр
Описание qd
определение запроса return
экземпляр запроса
4.3.1.20.4. currentTransaction()
public abstract Transaction
currentTransaction();
com.mysql.clusterj.Transaction.Параметр
Описание return
транзакция
4.3.1.20.5. deletePersistent(Class<T>, Object)
public abstract void
deletePersistent(Class<T> cls
,
Object key);Параметр
Описание cls
интерфейс или динамический класс key
primary key
4.3.1.20.6. deletePersistent(Object)
public abstract void
deletePersistent(Object instance
);
Параметр
Описание instance
экземпляр, чтобы удалить
4.3.1.20.7. deletePersistentAll(Class<T>)
public abstract int
deletePersistentAll(Class<T> cls
);
Параметр
Описание cls
интерфейс или динамический класс return
сколько удалено экземпляров
4.3.1.20.8. deletePersistentAll(Iterable<?>)
public abstract void
deletePersistentAll(Iterable<?>
instances);
Параметр
Описание instances
экземпляры, чтобы удалить
4.3.1.20.9. find(Class<T>, Object)
public abstract T find
(Class<T> cls,
Object key);Параметр
Описание cls
интерфейс или динамический класс, чтобы найти экземпляр key
ключ экземпляра, чтобы найти return
экземпляр интерфейса или динамического класса с указанным ключом
4.3.1.20.10. flush()
public abstract void
flush();
4.3.1.20.11. found(Object)
public abstract Boolean
found(Object instance);
Параметр
Описание instance
экземпляр, соответствующий строке в базе данных return
4.3.1.20.12.
getQueryBuilder()
public abstract QueryBuilder
getQueryBuilder();
Параметр
Описание return
конструктор запросов
4.3.1.20.13. isClosed()
public abstract boolean
isClosed();
Параметр
Описание return
true, если сессия закрывается
4.3.1.20.14. load(T)
public abstract T load
(T instance);
Параметр
Описание instance
экземпляр, чтобы загрузить return
экземпляр
4.3.1.20.15.
makePersistent(T)
public abstract T
makePersistent(T instance
);
Параметр
Описание instance
экземпляр, чтобы вставить return
экземпляр
4.3.1.20.16. makePersistentAll(Iterable<?>)
public abstract Iterable<?>
makePersistentAll(Iterable<?>
instances);
Параметр
Описание instances
экземпляры, чтобы вставить. return
экземпляры
4.3.1.20.17. markModified(Object, String)
public abstract void
markModified(Object instance,
String fieldName);Параметр
Описание instance
постоянный экземпляр fieldName
область, чтобы отметить, как измененную
4.3.1.20.18.
newInstance(Class<T>)
public abstract T
newInstance(Class<T> cls
);
Параметр
Описание cls
интерфейс, для которого можно создать экземпляр return
экземпляр, который осуществляет интерфейс
4.3.1.20.19. newInstance(Class<T>, Object)
public abstract T
newInstance(Class<T> cls,
Object key);Параметр
Описание cls
интерфейс, для которого можно создать экземпляр return
экземпляр, который осуществляет интерфейс
4.3.1.20.20. persist(Object)
public abstract void
persist(Object instance
);
Параметр
Описание instance
экземпляр, чтобы вставить
4.3.1.20.21. release(T)
public abstract T release
(T obj);
Параметр
Описание obj
объект области типа T, итератор или множество T[] return
входной параметр
ClusterJUserException
4.3.1.20.22. remove(Object)
public abstract void
remove(Object instance);
Параметр
Описание instance
экземпляр, чтобы удалить
4.3.1.20.23. savePersistent(T)
public abstract T
savePersistent(T instance
);
Параметр
Описание instance
экземпляр, чтобы обновить
4.3.1.20.24. savePersistentAll(Iterable<?>)
public abstract Iterable<?>
savePersistentAll(Iterable<?>
instances);
Параметр
Описание instances
экземпляры, чтобы обновить
4.3.1.20.25. setLockMode(LockMode)
public abstract void
setLockMode(LockMode lockmode
);
Параметр
Описание lockmode
Режим LockMode
4.3.1.20.26. setPartitionKey(Class<?>, Object)
public abstract void
setPartitionKey(Class<?> cls
,
Object key);Параметр
Описание key
первичный ключ отображенной таблицы
ClusterJUserException
ClusterJUserExceptionClusterJUserExceptionClusterJUserException
4.3.1.20.27. unloadSchema(Class<?>)
public abstract String
unloadSchema(Class<?> cls
);
Параметр
Описание cls
класс, для которого выгружена схема return
название схемы, которая была выгружена
4.3.1.20.28. updatePersistent(Object)
public abstract void
updatePersistent(Object instance
);
Параметр
Описание instance
экземпляр, чтобы обновить
4.3.1.20.29. updatePersistentAll(Iterable<?>)
public abstract void
updatePersistentAll(Iterable<?>
instances);
Параметр
Описание instances
экземпляры, чтобы обновить
4.3.1.21. SessionFactory
4.3.1.21.1. Резюме
public interface SessionFactory
{
// Public Methodspublic
abstract void close();
public abstract State
currentState();
public abstract List<Integer>
getConnectionPoolSessionCounts();
public abstract int
getRecvThreadActivationThreshold();
public abstract short[]
getRecvThreadCPUids();
public abstract Session
getSession();
public abstract Session
getSession(Map properties
);
public abstract void
reconnect();
public abstract void
reconnect(int timeout);
public abstract void
setRecvThreadActivationThreshold(int
threshold);
public abstract void
setRecvThreadCPUids(short[] cpuids
);
}
4.3.1.21.2. close()
public abstract void
close();
4.3.1.21.3.
currentState()
public abstract State
currentState();
4.3.1.21.4. getConnectionPoolSessionCounts()
public abstract List<Integer>
getConnectionPoolSessionCounts();
4.3.1.21.5. getRecvThreadActivationThreshold()
public abstract int
getRecvThreadActivationThreshold();
4.3.1.21.6. getRecvThreadCPUids()
public abstract short[]
getRecvThreadCPUids();
4.3.1.21.7.
getSession()
public abstract Session
getSession();
Параметр
Описание return
session
4.3.1.21.8. getSession(Map)
public abstract Session
getSession(Map properties
);
Параметр
Описание properties
перекрытие некоторых свойств для этой сессии return
session
4.3.1.21.9.
reconnect()
public abstract void
reconnect();
4.3.1.21.10.
reconnect(int)
public abstract void
reconnect(int timeout);
Параметр
Описание timeout
Значение тайм-аута в секундах, 0, чтобы отключить
автоматическое повторное соединение
4.3.1.21.11. setRecvThreadActivationThreshold(int)
public abstract void
setRecvThreadActivationThreshold(int
threshold);
ClusterJUserExceptionClusterJFatalInternalException
4.3.1.21.12. setRecvThreadCPUids(short[])
public abstract void
setRecvThreadCPUids(short[] cpuids
);
ClusterJUserException
ClusterJFatalInternalException
4.3.1.22. SessionFactory.State
4.3.1.22.1. Резюме
public static final
class SessionFactory.State extends,
Enum<State> {
// Public Static Fieldspublic
static final State
Closed ;
public static
final State Open ;
public static
final State Reconnecting
;
// Public Static Methodspublic static
State valueOf(String name
);
public static State[]
values();
}
compareTo
, equals
, getDeclaringClass
, hashCode
, Имя
, ordinal
, toString
, valueOfgetClass
, notify
, notifyAll
, wait
4.3.1.23. SessionFactoryService
4.3.1.23.1. Резюме
public interface
SessionFactoryService {
// Public Methodspublic abstract
SessionFactory getSessionFactory(
Map<String, String> props);
}
4.3.1.23.2. getSessionFactory(Map<String, String>)
public abstract SessionFactory
getSessionFactory(Map<String, String>
props);
Параметр
Описание props
свойства для фабрики сессии, в которых ключи определяются в Constants
и значения описывают окружающую среду return
session factory
4.3.1.24. Transaction
4.3.1.24.1. Резюме
public interface Transaction
{
// Public Methodspublic abstract
void begin();
public abstract void
commit();
public abstract boolean
getRollbackOnly();
public abstract boolean
isActive();
public abstract void
rollback();
public abstract void
setRollbackOnly();
}
4.3.1.24.2. begin()
public abstract void begin
();
4.3.1.24.3. commit()
public abstract void
commit();
4.3.1.24.4.
getRollbackOnly()
public abstract boolean
getRollbackOnly();
Параметр
Описание return
true, если транзакция была отмечена как rollback only
4.3.1.24.5. isActive()
public abstract boolean
isActive();
Параметр
Описание return
true, если транзакция активна
4.3.1.24.6. rollback()
public abstract void
rollback();
4.3.1.24.7. setRollbackOnly()
public abstract void
setRollbackOnly();
4.3.2. com.mysql.clusterj.annotation
4.3.2.1. Column
4.3.2.1.1. Резюме
@Target(value={java.lang.annotation.ElementType.FIELD,
java.lang.annotation.ElementType.METHOD})
@Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME)
public @interface Column {
public String
Имя ;
public String
allowsNull ;
public String
defaultValue ;
}
4.3.2.1.2. allowsNull
Параметр
Описание return
позволяет ли столбец нулевым значениям быть вставленными
4.3.2.1.3.
defaultValue
Параметр
Описание return
значение по умолчанию для этой столбца
4.3.2.1.4. name
Параметр
Описание return
Название столбца
4.3.2.2. Columns
4.3.2.2.1. Резюме
@Target(value={java.lang.annotation.ElementType.FIELD,
java.lang.annotation.ElementType.METHOD,
java.lang.annotation.ElementType.TYPE})
@Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME)
public @interface Columns {
public Column[]
value ;
}
4.3.2.2.2. value
Параметр
Описание return
собственно столбцы
4.3.2.3. Extension
4.3.2.3.1. Резюме
@Target(value={java.lang.annotation.ElementType.TYPE,
java.lang.annotation.ElementType.FIELD,
java.lang.annotation.ElementType.METHOD})
@Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME)
public @interface Extension
{
public String
vendorName ;
public String
key ;
public String
value ;
}
4.3.2.3.2. key
Параметр
Описание return
Собственно ключ
4.3.2.3.3. value
Параметр
Описание return
Значение
4.3.2.3.4.
vendorName
Параметр
Описание return
vendor
4.3.2.4. Extensions
4.3.2.4.1. Резюме
@Target(value={java.lang.annotation.ElementType.TYPE,
java.lang.annotation.ElementType.FIELD,
java.lang.annotation.ElementType.METHOD})
@Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME)
public @interface Extensions
{
public Extension[]
value ;
}
4.3.2.4.2. value
Параметр
Описание return
Расширения
4.3.2.5. Index
4.3.2.5.1. Резюме
@Target(value={java.lang.annotation.ElementType.TYPE,
java.lang.annotation.ElementType.FIELD,
java.lang.annotation.ElementType.METHOD})
@Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME)
public @interface Index{
public String
Имя ;
public String
unique ;
public Column[]
columns ;
}
4.3.2.5.2. columns
Параметр
Описание return
Столбцы, которые составляют этот индекс
4.3.2.5.3. name
Параметр
Описание return
Название индекса
4.3.2.5.4. unique
Параметр
Описание
return
Уникален ли этот индекс
4.3.2.6. Indices
4.3.2.6.1. Резюме
@Target(value=java.lang.annotation.ElementType.TYPE)
@Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME)
public @interface Indices {
public Index[]
value ;
}
4.3.2.6.2. value
Параметр
Описание return
Индексы
4.3.2.7. Lob
4.3.2.7.1. Резюме
@Target(value={java.lang.annotation.ElementType.FIELD,
java.lang.annotation.ElementType.METHOD})
@Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME)
public @interface Lob
{
}
4.3.2.8. NotPersistent
4.3.2.8.1. Резюме
@Target(value={java.lang.annotation.ElementType.FIELD,
java.lang.annotation.ElementType.METHOD})
@Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME)
public @interface NotPersistent
{
}
4.3.2.9. NullValue
4.3.2.9.1. Резюме
public final class
NullValue extends, Enum<NullValue>
{
// Public Static Fieldspublic
static final NullValue
DEFAULT ;
public static
final NullValue EXCEPTION
;
public static
final NullValue NONE
;
// Public Static Methodspublic static
NullValue valueOf(String name
);
public static NullValue[]
values();
}
compareTo
, equals
, getDeclaringClass
, hashCode
, Имя
, ordinal
, toString
, valueOfgetClass
, notify
, notifyAll
, wait
4.3.2.10. PartitionKey
4.3.2.10.1. Резюме
@Target(value={java.lang.annotation.ElementType.TYPE,
java.lang.annotation.ElementType.FIELD,
java.lang.annotation.ElementType.METHOD})
@Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME)
public @interface PartitionKey
{
public String
column ;
public Column[]
columns ;
}
4.3.2.10.2. column
Параметр
Описание
return
Название столбца, чтобы использовать для ключа разделения.
4.3.2.10.3. columns
Параметр
Описание return
Столбец (столбцы) для ключа разделения.
4.3.2.11. PersistenceCapable
4.3.2.11.1. Резюме
@Target(value=java.lang.annotation.ElementType.TYPE)
@Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME)
public @interface PersistenceCapable
{
public
String table ;
public String
database ;
public String
schema ;
}
4.3.2.12. PersistenceModifier
4.3.2.12.1. Резюме
public final class
PersistenceModifier extends,
Enum<PersistenceModifier> {
// Public Static Fieldspublic
static final PersistenceModifier
NONE ;
public static
final PersistenceModifier
PERSISTENT ;
public static
final PersistenceModifier
UNSPECIFIED ;
// Public Static Methodspublic static
PersistenceModifier valueOf(String
name);
public static
PersistenceModifier[] values();
}
compareTo
, equals
, getDeclaringClass
, hashCode
, Имя
, ordinal
, toString
, valueOfgetClass
, notify
, notifyAll
, wait
4.3.2.13. Persistent
4.3.2.13.1. Резюме
@Target(value={java.lang.annotation.ElementType.FIELD,
java.lang.annotation.ElementType.METHOD})
@Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME)
public @interface Persistent
{
public
NullValue nullValue ;
public
String primaryKey ;
public
String column ;
public
Extension[] extensions ;
}
4.3.2.13.2. column
Параметр
Описание return
the name of the column
4.3.2.13.3. extensions
Параметр
Описание
return
Нестандартные расширения для этого участника.
4.3.2.13.4. nullValue
Параметр
Описание return
Поведение, когда этот участник содержит нулевое значение.
4.3.2.13.5. primaryKey
Параметр
Описание return
Является ли этот участник частью первичного ключа для таблицы.
4.3.2.14.
PrimaryKey
4.3.2.14.1. Резюме
@Target(value={java.lang.annotation.ElementType.TYPE,
java.lang.annotation.ElementType.FIELD,
java.lang.annotation.ElementType.METHOD})
@Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME)
public @interface PrimaryKey
{
public String
Имя ;
public String
column ;
public Column[]
columns ;
}
4.3.2.14.2. column
Параметр
Описание return
Название столбца, чтобы использовать для первичного ключа.
4.3.2.14.3. columns
Параметр
Описание
return
Столбец (столбцы) для первичного ключа.
4.3.2.14.4. name
Параметр
Описание return
Название ограничения первичного ключа.
4.3.2.15.
Projection
4.3.2.15.1. Резюме
@Target(value=java.lang.annotation.ElementType.TYPE)
@Retention(value=java.lang.annotation.RetentionPolicy.RUNTIME)
public @interface Projection {
}
4.3.3. com.mysql.clusterj.query
4.3.3.1. Predicate
4.3.3.1.1. Резюме
public interface Predicate
{
// Public Methodspublic abstract
Predicate and(Predicate
predicate);public
abstract Predicate not();
public abstract Predicate
or(Predicate predicate
);
}
4.3.3.1.2. and(Predicate)
public abstract Predicate
and(Predicate predicate);
Параметр
Описание predicate
tдругой предикат return
новый Предикат, объединяющий оба Предиката
4.3.3.1.3. not()
public abstract Predicate
not();
Параметр
Описание return
этот предикат
4.3.3.1.4. or(Predicate)
public abstract Predicate
or(Predicate predicate);
Параметр
Описание predicate
другой предикат return
новый Предикат, объединяющий оба Предиката
4.3.3.2.
PredicateOperand
4.3.3.2.1. Резюме
public interface PredicateOperand
{
// Public Methodspublic abstract
Predicate between(PredicateOperand
lower,
PredicateOperand upper);
public abstract Predicate
equal(PredicateOperand other
);
public abstract Predicate
greaterEqual(PredicateOperand other
);
public abstract Predicate
greaterThan(PredicateOperand other
);
public abstract Predicate
in(PredicateOperand other
);
public abstract Predicate
isNotNull();
public abstract Predicate
isNull();
public abstract Predicate
lessEqual(PredicateOperand other
);
public abstract Predicate
lessThan(PredicateOperand other
);
public abstract Predicate
like(PredicateOperand other
);
}
4.3.3.2.2. between(PredicateOperand, PredicateOperand)
public abstract Predicate
between(PredicateOperand lower,
PredicateOperand upper);Параметр
Описание lower
другой PredicateOperand
upper
другой PredicateOperand return
новый Predicate
4.3.3.2.3. equal(PredicateOperand)
public abstract Predicate
equal(PredicateOperand other
);
Параметр
Описание other
другой PredicateOperand return
новый Predicate
4.3.3.2.4. greaterEqual(PredicateOperand)
public abstract Predicate
greaterEqual(PredicateOperand other
);
Параметр
Описание other
другой PredicateOperand return
новый Predicate
4.3.3.2.5. greaterThan(PredicateOperand)
public abstract Predicate
greaterThan(PredicateOperand other
);
Параметр
Описание other
другой PredicateOperand return
новый Predicate
4.3.3.2.6. in(PredicateOperand)
public abstract Predicate
in(PredicateOperand other
);
Параметр
Описание other
другой PredicateOperand return
новый Predicate
4.3.3.2.7. isNotNull()
public abstract Predicate
isNotNull();
Параметр
Описание return
новый Predicate
4.3.3.2.8. isNull()
public abstract Predicate
isNull();
Параметр
Описание return
новый Predicate
4.3.3.2.9. lessEqual(PredicateOperand)
public abstract Predicate
lessEqual(PredicateOperand other
);
Параметр
Описание other
другой PredicateOperand return
новый Predicate
4.3.3.2.10. lessThan(PredicateOperand)
public abstract
Predicate lessThan(PredicateOperand
other);
Параметр
Описание other
другой PredicateOperand return
новый Predicate
4.3.3.2.11. like(PredicateOperand)
public abstract Predicate
like(PredicateOperand other
);
Параметр
Описание other
другой PredicateOperand return
новый Predicate
4.3.3.3. QueryBuilder
4.3.3.3.1. Резюме
public interface QueryBuilder
{
// Public Methodspublic abstract
QueryDomainType<T> createQueryDefinition(
Class<T> cls);
}
4.3.3.3.2. createQueryDefinition(Class<T>)
public abstract
QueryDomainType<T> createQueryDefinition(
Class<T> cls);
Параметр
Описание cls
класс типа, который будет запрошен return
QueryDomainType, чтобы определить запрос
4.3.3.4. QueryDefinition
4.3.3.4.1. Резюме
public interface
QueryDefinition<E> {
// Public Methodspublic abstract
Predicate not(Predicate
predicate);
public abstract
PredicateOperand param(String
parameterName);
public abstract
QueryDefinition<E> where(
Predicate predicate);
}
4.3.3.4.2. not(Predicate)
public abstract Predicate
not(Predicate predicate);
Параметр
Описание predicate
предикат для отрицания return
инвертированный предикат
4.3.3.4.3. param(String)
public abstract PredicateOperand
param(String parameterName
);
Параметр
Описание parameterName
название параметра return
PredicateOperand, представляющий параметр
4.3.3.4.4. where(Predicate)
public abstract
QueryDefinition<E> where(Predicate
predicate);
Параметр
Описание predicate
Predicate return
это определение запроса
4.3.3.5. QueryDomainType
4.3.3.5.1. Резюме
public interface
QueryDomainType<E> extends,
QueryDefinition<E>{
// Public Methodspublic abstract
PredicateOperand get(String
propertyName);public
abstract Class<E> getType
();
}
4.3.3.5.2. get(String)
public abstract PredicateOperand
get(String propertyName
);
Параметр
Описание propertyName
название свойства return
представление значения свойства
4.3.3.5.3. getType()
public abstract Class<E>
getType();
Параметр
Описание return
Тип области запроса.
4.3.4. Постоянные значения полей
4.3.4.1. com.mysql.clusterj.*
Имя
Описание DEFAULT_PROPERTY_CLUSTER_BYTE_BUFFER_POOL_SIZES
"256, 10240, 102400, 1048576"
DEFAULT_PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_BATCH_SIZE
10 DEFAULT_PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_START
1 DEFAULT_PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_STEP
1 DEFAULT_PROPERTY_CLUSTER_CONNECT_DELAY
5 DEFAULT_PROPERTY_CLUSTER_CONNECT_RETRIES
4 DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER
20 DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE
30 DEFAULT_PROPERTY_CLUSTER_CONNECT_TIMEOUT_MGM
30000 DEFAULT_PROPERTY_CLUSTER_CONNECT_VERBOSE
0 DEFAULT_PROPERTY_CLUSTER_DATABASE "test" DEFAULT_PROPERTY_CLUSTER_MAX_TRANSACTIONS
4
DEFAULT_PROPERTY_CONNECTION_POOL_RECV_THREAD_ACTIVATION_THRESHOLD
8 DEFAULT_PROPERTY_CONNECTION_POOL_SIZE 1 DEFAULT_PROPERTY_CONNECTION_RECONNECT_TIMEOUT
0 ENV_CLUSTERJ_LOGGER_FACTORY_NAME
"CLUSTERJ_LOGGER_FACTORY" PROPERTY_CLUSTER_BYTE_BUFFER_POOL_SIZES
"com.mysql.clusterj.byte.buffer.pool.sizes" PROPERTY_CLUSTER_CONNECTION_SERVICE
"com.mysql.clusterj.connection.service" PROPERTY_CLUSTER_CONNECTSTRING
"com.mysql.clusterj.connectstring" PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_BATCH_SIZE
"com.mysql.clusterj.connect.autoincrement.batchsize" PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_START
"com.mysql.clusterj.connect.autoincrement.offset" PROPERTY_CLUSTER_CONNECT_AUTO_INCREMENT_STEP
"com.mysql.clusterj.connect.autoincrement.increment" PROPERTY_CLUSTER_CONNECT_DELAY
"com.mysql.clusterj.connect.delay" PROPERTY_CLUSTER_CONNECT_RETRIES
"com.mysql.clusterj.connect.retries" PROPERTY_CLUSTER_CONNECT_TIMEOUT_AFTER
"com.mysql.clusterj.connect.timeout.after" PROPERTY_CLUSTER_CONNECT_TIMEOUT_BEFORE
"com.mysql.clusterj.connect.timeout.before" PROPERTY_CLUSTER_CONNECT_TIMEOUT_MGM
"com.mysql.clusterj.connect.timeout.mgm" PROPERTY_CLUSTER_CONNECT_VERBOSE
"com.mysql.clusterj.connect.verbose" PROPERTY_CLUSTER_DATABASE
"com.mysql.clusterj.database" PROPERTY_CLUSTER_MAX_TRANSACTIONS
"com.mysql.clusterj.max.transactions" PROPERTY_CONNECTION_POOL_NODEIDS
"com.mysql.clusterj.connection.pool.nodeids"
PROPERTY_CONNECTION_POOL_RECV_THREAD_ACTIVATION_THRESHOLD
"com.mysql.clusterj.connection.pool.recv.thread.activation.threshold"
PROPERTY_CONNECTION_POOL_RECV_THREAD_CPUIDS
"com.mysql.clusterj.connection.pool.recv.thread.cpuids" PROPERTY_CONNECTION_POOL_SIZE
"com.mysql.clusterj.connection.pool.size" PROPERTY_CONNECTION_RECONNECT_TIMEOUT
"com.mysql.clusterj.connection.reconnect.timeout" PROPERTY_DEFER_CHANGES
"com.mysql.clusterj.defer.changes" PROPERTY_JDBC_DRIVER_NAME
"com.mysql.clusterj.jdbc.driver" PROPERTY_JDBC_PASSWORD
"com.mysql.clusterj.jdbc.password" PROPERTY_JDBC_URL
"com.mysql.clusterj.jdbc.url" PROPERTY_JDBC_USERNAME
"com.mysql.clusterj.jdbc.username" SESSION_FACTORY_SERVICE_CLASS_NAME
"com.mysql.clusterj.SessionFactoryService" SESSION_FACTORY_SERVICE_FILE_NAME
"META-INF/services/com.mysql.clusterj.SessionFactoryService"
Имя
Описание INDEX_USED
"IndexUsed" SCAN_TYPE "ScanType" SCAN_TYPE_INDEX_SCAN "INDEX_SCAN" SCAN_TYPE_PRIMARY_KEY "PRIMARY_KEY" SCAN_TYPE_TABLE_SCAN "TABLE_SCAN" SCAN_TYPE_UNIQUE_KEY "UNIQUE_KEY"
4.4. MySQL NDB Cluster Connector for Java:
ограничения и известные проблемы
NDB, приложения ClusterJ
не могут видеть представления и таким образом
не могут получить доступ к ним. Чтобы работать с представлениями, используя
Яву, необходимо использовать JPA или JDBC.NDB для NDB Cluster 7.3 и
выше понимают внешние ключи и ограничения внешнего ключа проведены в жизнь,
используя ClusterJ для вставок, обновлений и удалений.
| Найди своих коллег! |
Вы можете
направить письмо администратору этой странички, Алексею Паутову.
![]()