|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
NDB Cluster поддерживает асинхронную
репликацию, чаще упомянутую просто как
репликация.
Эта секция объясняет, как настроить и управлять конфигурацией, в которой одна
группа компьютеров, работающих как NDB Cluster,
копирует к второму компьютеру или группе компьютеров.
Предполагается, что читатель знаком с репликацией MySQL
(см. Replication). NDB Cluster не поддерживает репликацию, используя GTID, полусинхронная
репликация также не поддерживается в Нормальная репликация включает
ведущий и ведомый
серверы. Ведущий является источником операций и данных, которые будут
копироваться, ведомый является получателем. В NDB Cluster
репликация концептуально очень похожа, но может быть более сложна на
практике, поскольку это может быть расширено, чтобы покрыть много различных
конфигураций, включая репликацию между двумя полными кластерами.
Хотя сам NDB Cluster зависит от
Рис. 8.1. NDB Cluster-to-Cluster Replication В этом сценарии процесс репликации
тот, в котором последовательные статусы основного кластера зарегистрированы и
сохранены к ведомому. Этот процесс достигается специальным потоком, известным
как двоичный поток инжектора регистрации NDB, который работает
на каждом сервере MySQL и производит регистрацию
( Для получения информации о выполнении восстановления момента времени NDB
Cluster и NDB Cluster Replication см.
главу 8.9.2. Переменные статуса NDB API _slave.
NDB API может обеспечить увеличенные контролирующие возможности на ведомых
репликации NDB Cluster. Они осуществляются как статистика переменных статуса
NDB Репликация от NDB до не-NDB таблиц. Возможно копировать
таблицы Всюду по этой секции мы используем следующие сокращения или символы для
обращения к группам ведущего и ведомого, к процессам и командам, которыми
управляют на узлах группы: Таблица 8.1. Аббревиатуры и символы Канал репликации требует двух серверов MySQL, действующих как серверы
репликации (один для ведущего и ведомого). Например, это означает, что в
случае установки репликации с двумя каналами репликации (чтобы обеспечить
дополнительный канал для избыточности), будет в общей сложности четыре узла
репликации (по два на кластер). Репликация NDB Cluster зависит от построчной репликации. Это означает, что
ведущий сервер репликации MySQL должен работать с
При попытке использовать репликацию NDB Cluster с
Значение по умолчанию для
Каждый сервер MySQL, используемый для репликации в любой группе, должен
быть однозначно определен среди всех серверов репликации MySQL, участвующих в
любой группе (у вас не может быть серверов репликации ведущего и ведомого
кластеров, разделяющих тот же самый ID).
Это может быть сделано, начав каждый узел SQL, используя опцию
Вообще верно в MySQL Replication, что оба сервера MySQL
(процессы mysqld)
должны быть совместимыми друг с другом относительно версии используемого
протокола репликации и относительно наборов функций SQL, которые
они поддерживают (см.
здесь). Это происходит из-за таких различий в NDB Cluster
и MySQL Server 5.7, что у NDB Cluster Replication
есть дополнительное требование, чтобы оба
mysqld произошли из
дистрибутива NDB Cluster. Самый простой и самый легкий способ гарантировать,
что серверы mysqld
совместимы, состоит в том, чтобы использовать тот же самый дистрибутив NDB
Cluster для ведущего и ведомого
mysqld. Мы предполагаем, что ведомый сервер
заняты только репликацией ведущего, и что никакие другие данные не
хранятся на нем. Все реплицируемые таблицы Возможно копировать NDB Cluster, используя основанную на запросе
репликацию. Однако в этом случае следующие ограничения применяются: Все обновления строк данных в кластере, действующем как ведущий,
должны быть направлены к единственному серверу MySQL. Невозможно копировать кластер, используя многократные одновременные
процессы репликации MySQL. Только изменения, внесенные на уровне SQL, копируются. Это в дополнение к другим ограничениям основанной на запросе
репликации в противоположность построчной репликации, посмотрите
see здесь для более определенной информации относительно
различий между двумя форматами репликации. Эта секция обсуждает известные проблемы в
репликации с NDB Cluster 7.5. Потеря связи.
Потеря связи может произойти между ведущим репликации узлом SQL и ведомым
репликации узлом SQL или между ведущим репликации узлом SQL и узлами данных в
основном кластере. В последнем случае это может произойти не только в
результате потери физической связи (например, сломанный сетевой кабель), а
из-за переполнения буферов событий узла данных,
если узел SQL также не спешит отвечать, он может быть пропущен кластером
(это управляемо до некоторой степени, приспосабливая параметры
Ведущий репликации выпускает событие gap,
соединяясь или снова соединяясь с основным кластером. Событие gap тип
incident event, которое указывает на инцидент,
который затрагивает содержание базы данных, но это не может легко быть
представлено как строка изменений. Примеры инцидентов: катастрофы сервера,
пересинхронизация базы данных, (немного) обновления программного обеспечения
и (немного) изменения аппаратной конфигурации. Когда ведомый сталкивается с
gap в журнале репликации, это останавливается с сообщением об ошибке.
Это сообщение доступно в выводе
Поскольку NDB Cluster не разработан, чтобы контролировать состояние
репликации или обеспечить отказоустойчивость, если высокая доступность
требование для ведомого сервера или кластера, то необходимо настроить
многократные линии репликации, контролировать основной
mysqld
на основной линии репликации и быть подготовленным перейти к вторичной линии
по мере необходимости. Это должно быть сделано вручную или возможно
посредством стороннего приложения. Для получения информации об осуществлении
этого типа установки посмотрите главы
8.7 и
8.8. Однако, если вы копируете от автономного сервера MySQL в NDB Cluster,
один канал обычно достаточен. Кольцевая репликация.
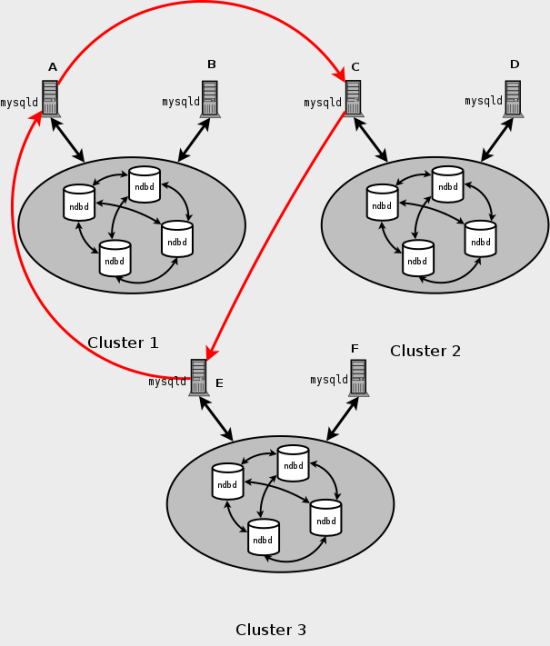
NDB Cluster Replication допускает кольцевую репликацию, как показано
в следующем примере. Установка репликации включает три NDB Clusters 1, 2 и 3,
где Cluster 1 действует как ведущий репликации для Cluster 2, Cluster 2
действует как ведущий репликации для Cluster 3, а Cluster 3 действует как
ведущий репликации для Cluster 1, таким образом заканчивая круг. У каждого
NDB Cluster есть два узла SQL, с узлами SQL A и B, принадлежащими Cluster 1,
узлами SQL C и D, принадлежащими Cluster 2, и узлами
SQL E и F, принадлежащими Cluster 3. Кольцевая репликация, используя эти группы поддерживается, пока
следующим условиям отвечают: Узлы SQL на всех ведущих и ведомых те же самые. Все узлы SQL, действующие как ведущие и ведомые репликации, начаты с
включенной системной переменной
Этот тип кольцевой установки репликации показывают
на следующей диаграмме: Рис. 8.2. Кольцевая репликация NDB Cluster В этом сценарии узел SQL A в Cluster 1 копирует к узлу SQL C в
Cluster 2, узел SQL C копирует к узлу SQL E в Cluster 3, узел
SQL E копирует узлу SQL A. Другими словами, линия репликации (обозначена
кривыми стрелками на диаграмме) непосредственно соединяет все узлы SQL,
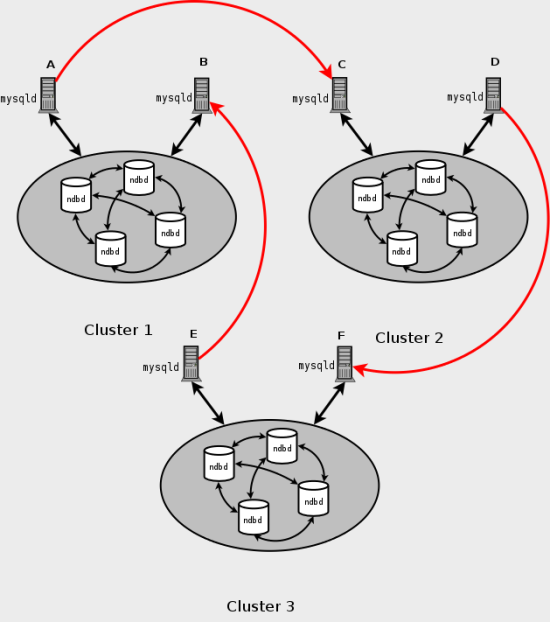
используемые в качестве ведущих и ведомых в репликации. Должно также быть возможно настроить кольцевую репликацию, в которой не
все основные узлы SQL ведомые, как показано здесь: Рис. 8.3. NDB Cluster: другой вариант кольцевой репликации В этом случае различные узлы SQL в каждой группе используются в качестве
ведущих репликации и ведомых. Однако, вы не должны
начинать ни один из узлов SQL с включенной системной переменной
Механизм хранения Репликация NDB Cluster и первичные ключи.
В случае неудачи узла, ошибок в репликации
NDB Cluster Replication и уникальные ключи.
В более старых версиях NDB Cluster
операции, которые обновили значения столбцов уникального ключа таблиц
Отсрочка ограничений таким образом в настоящее время поддерживается
только Проблема есть, когда репликация без отсроченной проверки обновлений
уникального ключа может быть иллюстрирована, используя таблицу
Однако то же самое потерпит неудачу с ошибкой дублирования ключа или
другим ограничительным нарушением на ведомом, потому что порядок
обновлений строки был сделан для одного разделения за один раз, а не
для таблицы в целом. Каждая таблица GTID не поддерживаются. Репликация используя глобальные ID
транзакции, не совместимые с Многопоточные ведомые не поддержаны.
NDB Cluster не поддерживает многопоточных ведомых и урегулирование связанных
системных переменных, например,
Это вызвано тем, что ведомый может не быть в состоянии отделить
транзакции, происходящие в одной базе данных,
от транзакций в другой, если они написаны в течение той же самой эпохи.
Кроме того, каждая транзакция, обработанная
Перезапуск с --initial.
Перезапуск с
Репликация с NDB на другие механизмы хранения.
Возможно копировать таблицы
Мультиведомая и кольцевая репликация не поддерживаются
(таблицы на ведущем и на ведомом должны использовать
Использование механизма хранения, который не выполняет двоичную
регистрацию для ведомых таблиц, требует специальной обработки. Использование нетранзакционного механизма хранения для ведомых таблиц
также требует специальной обработки. Основной mysqld
должен быть начат с опцией
Следующие несколько параграфов предоставляют дополнительную информацию о
каждой из проблем. Многократные ведущие, не поддержаны, копируя NDB к другим
механизмам хранения. Для репликации из
Кроме того, невозможно формировать больше, чем один канал репликации,
копируя между Репликация NDB к ведомому механизму хранения, который не
выполняет двоичную регистрацию.
При попытке копировать от NDB Cluster к ведомому, который использует механизм
хранения, который не обращается с его собственной двоичной регистрацией,
процесс репликации отвалится с ошибкой
Binary logging not possible ... Statement cannot be
written atomically since more than one engine involved and at
least one engine is self-logging (Error
1595).
Можно обойти проблему одним из следующих способов: Выключите двоичный журнал на ведомом.
Это может быть достигнуто, установив
Измените механизм хранения, используемый для таблицы
the mysql.ndb_apply_status.
Если эта таблица будет использовать механизм, который не обращается с его
собственной двоичной регистрацией, это может также устранить конфликт.
Это может быть сделано, делая такой запрос, как
Отфильтруйте изменения таблицы mysql.ndb_apply_status на
ведомом. Это может быть сделано, начав ведомый узел SQL с
Вы не должны отключать репликацию или двоичную регистрацию
Репликация с NDB на нетранзакционный механизм хранения. Копируя от
Репликация и двоичная регистрация, фильтрующая правила с репликацией
между кластерами NDB. При использовании какой-либо из опций
Применение Применение Используя
Используя Необходимо также помнить, что каждое правило
репликации требует следующего: Собственная опция
Собственная опция
Если вы копируете NDB Cluster
ведомому, который использует механизм хранения кроме
NDB Cluster Replication и IPv6.
Сейчас NDB API и MGM API не поддерживают IPv6. Но MySQL Server
включая тех, которые действуют как узлы SQL в NDB Cluster,
могут использовать IPv6, чтобы связаться с другими MySQL Server.
Это означает, что можно копировать между NDB Cluster, используя IPv6, чтобы
соединить узлы SQL ведущего и ведомого, как показано штриховой
стрелкой в следующей диаграмме: Рис. 8.4. Репликация между узлами SQL, связанными IPv6 Однако все связи, происходящие в
NDB Cluster, представленной в предыдущей диаграмме непрерывными стрелами,
должны использовать IPv4. Другими словами, все узлы данных NDB Cluster,
серверы управления и клиенты управления должны быть доступными друг от друга,
используя IPv4. Кроме того, узлы SQL должны использовать IPv4,
чтобы общаться с группой. В настоящее время нет никакой поддержки в NDB и MGM API для IPv6,
поэтому все приложения с этими API используют именно IPv4. Продвижение и понижение признака. NDB Cluster Replication
включает поддержку продвижения признака.
Внедрение последнего различает преобразования типов,
их использованием на ведомом можно управлять, устанавливая
глобальную системную переменную сервера
См. Row-based replication: attribute
promotion and demotion. Репликация в NDB Cluster использует много специальных таблиц в БД
До NDB 7.5.2 эта таблица всегда использовала механизм
Размер этой таблицы зависит от числа эпох на файл двоичного журнала и
количества двоичных файлов журнала. Число эпох на файл двоичного журнала
обычно зависит от объема двоичной регистрации, произведенной в эпоху и
размера двоичного файла журнала с меньшими эпохами, законченных в большее
количество эпох на файл. Необходимо знать, что пустые эпохи производят
вставки для таблицы Занятый NDB Cluster пишет двоичную регистрацию регулярно и по-видимому
ротирует двоичные файлы журнала более быстро. Это означает, что
тихий NDB Cluster с
Когда mysqld стартует
с опцией
Добавление этого индекса не предоставляет преимущества, копируя от
единственного ведущего единственному ведомому, так как запрос
положения двоичной регистрации в таких случаях не использует
См. главу
8.8 для получения дополнительной информации об использовании колонок
Следующие данные показывают отношения главного сервера репликации NDB
Cluster, его потока инжектора двоичного журнала и таблицы
Рис. 8.5. Replication Master Cluster Дополнительная таблица Таблица Поскольку эта таблица наполнена из
данных, происходящих на ведущем, нужно позволить копировать,
любая фильтрация репликации или двоичной регистрации, фильтрующая правила,
которые непреднамеренно препятствуют тому, чтобы ведомый обновил
Таблицы Однако, желательно проверить существование и целостность этих таблиц как
начальный шаг в подготовке NDB Cluster к репликации.
Возможно рассмотреть данные о событии, зарегистрированные в двоичной
регистрации, запрашивая таблицу
Можно также получить полезную информацию из вывода
Когда выполнение схемы изменяется на таблицы
Если таблицы Разрешение конфликтов для NDB Cluster Replication
требует присутствия дополнительной таблицы
Подготовка NDB Cluster для репликации состоит из следующих шагов: Проверьте все серверы MySQL на совместимость версий (см.
главу 8.2
). Создайте ведомую учетку на основном
кластере с соответствующими привилегиями: В предыдущем запросе
Например, чтобы создать ведомую учетную запись пользователя с именем
Из соображений безопасности предпочтительно использовать уникальную
учетную запись пользователя, не используемую для любой другой
цели для репликации.
Формируйте ведомого, чтобы использовать ведущего. Используя MySQL Monitor,
это может быть достигнуто командой
В предыдущем запросе Например, чтобы сказать ведомому копировать от сервера MySQL, имя хоста
которого Для полного списка вариантов, которые могут использоваться с
этим запросом, посмотрите
CHANGE MASTER TO Statement. Чтобы обеспечить репликацию, также необходимо добавить
Для дополнительных опций, которые могут быть установлены в
Если основная группа уже используется, можно создать резервную копию
ведущего и загрузить ее на ведомого, чтобы сократить количество времени,
требуемое для ведомого, чтобы синхронизировать себя с ведущим. Если ведомый
также управляет NDB Cluster, это может быть достигнуто, используя резервную
копию и процедуру, описанную в
главе 8.9. Если вы не применяете NDB Cluster
на ведомом репликации, можно создать резервную копию этой командой
на ведущем репликации: Импортируйте получающийся дамп данных на ведомого, копируя файл дампа.
После этого можно использовать
mysql,
чтобы импортировать данные из dumpfile в ведомую базу данных как показано
здесь, причем Для полного списка опций
mysqldump см.
mysqldump
A Database Backup Program. Если вы копируете данные ведомому этим способом, необходимо
удостовериться, что ведомый начат с опцией
Гарантируйте, что каждый сервер MySQL, действующий как ведущий
репликации, формируется с уникальным ID сервера и с включеной двоичной
регистрацией, используя формат строки. См.
Replication Formats.
Эти варианты могут быть установлены в файле
Эта секция обрисовывает в общих чертах процедуру старта репликации
NDB Cluster, используя единственный канал репликации. Начните главный сервер репликации MySQL, дав эту команду: В предыдущем запросе Можно также начать ведущего с
Начните ведомый сервер репликации MySQL как показано здесь: Здесь Необходимо использовать
Необходимо синхронизировать ведомый сервер с двоичной регистрацией
репликации главного сервера. Если двоичная регистрация ранее не работала
на ведущем, выполните следующий запрос на ведомом: Это приказывает ведомому начинать читать двоичную регистрацию ведущего от
отправной точки регистрации. Иначе, то есть, если вы загружаете данные от
ведущего, используя резервную копию, см.
главу 8.8
для получения информации о том, как получить правильные значения, чтобы
использовать для Наконец, необходимо приказать ведомому начинать применять репликация,
дав эту команду в клиенте
mysql
на ведомом репликации: Это также начинает передачу данных от ведущего ведомому. Также возможно использовать два канала репликации способом, подобным
процедуре, описанной в следующей секции, различия между этим и использованием
единственного канала репликации рассмотрены в
главе 8.7. Также возможно улучшить производительность репликации, позволяя
пакетные обновления.
Это может быть достигнуто, установив системную переменную
Ведомый комплектует пакеты на основе эпохи:
обновления, принадлежащие больше, чем одной транзакции, можно послать как
часть того же самого пакета. Все обновления применяются, когда конец эпохи достигнут, даже если общее
количество обновлений меньше 32 КБ. Группирование может быть включено во время выполнения.
Чтобы активировать его во время выполнения, можно использовать любой из
этих двух запросов: Если конкретный пакет вызывает проблемы (такие как запрос, эффекты
которого, кажется, не копируются правильно), пакетирование
может быть дезактивировано, используя любой из следующих запросов: Можно проверить, используется ли пакетирование
в настоящее время, посредством соответствующего
В более полном сценарии в качестве примера мы предполагаем два канала
репликации, чтобы обеспечить избыточность и таким образом принять меры против
возможного отказа единственного канала репликации. Это требует в общей
сложности четырех серверов репликации, двух ведущих для основной группы и
двух ведомых серверов для ведомой группы. В целях обсуждения мы предполагаем,
что уникальные идентификаторы назначены как показано здесь: Таблица 8.2. Сервера репликации NDB Cluster Подготовка репликации с двумя каналами не сильно
отличается от подготовки единственного канала репликации. Во-первых, процессы
mysqld
для основных и вторичных ведущих репликации должны начинаться, сопровождаемые
теми же процессами для основных и вторичных ведомых. Тогда процессы
репликации могут быть начаты командой
Начните основного ведущего репликации: Начните вторичного ведущего репликации: Начните основной ведомый сервер репликации: Начните вторичного ведомого репликации: Наконец, начните репликацию на основном канале, выполнив
Только основной канал должен быть начат в этом пункте.
Вторичный канал репликации должен быть начат только, если основной канал
репликации терпит неудачу, как описано в
главе 8.8.
Управление многократными каналами репликации одновременно может привести к
нежелательным записям, создаваемым на ведомых репликации. Как упомянуто ранее, необязательно включать двоичный журнал
на ведомых репликации. Если основной процесс репликации терпит неудачу, возможно переключиться на
вторичный канал репликации. Следующая процедура описывает шаги для этого.
Получите время новой глобальной контрольной точки (GCP). Таким образом,
необходимо определить новую эпоху из таблицы
В кольцевой топологии репликации, с ведущим и ведомым
на каждом хосте, когда вы используете
В этом случае необходимо определить последнюю эпоху на этом ведомом,
исключая любые эпохи от любых других ведомых в двоичной регистрации этого
ведомого, которые не были перечислены в опции
В некоторых случаях может быть более простым или более эффективным
использовать список ID серверов, которые будут включены и
Используя информацию, полученную из запроса, показанного в шаге 1,
получите соответствующие записи из таблицы
Можно использовать следующий запрос, чтобы получить необходимые записи
от таблицы Это сохранено на ведущем, начиная с отказа основного канала репликации.
Мы использовали пользовательскую переменную
Необходимо гарантировать, что ведомый
mysqld запущен с опцией
Теперь возможно синхронизировать вторичный канал, управляя следующим
запросом на вторичном ведомом сервере: Снова мы использовали пользовательские переменные (в этом случае
Можно теперь начать репликацию на вторичном канале, дав
соответствующую команду на вторичном ведомом
mysqld: Как только вторичный канал репликации активен, можно исследовать неудачу
для ремонтных работ. Вторичный канал репликации должен быть начат, только если и когда основной
канал репликации потерпел неудачу. Управление многократными каналами
репликации одновременно может привести к нежелательным дубликатам
записей, создаваемым на ведомых репликации. Если неудача ограничивается единственным сервером, должно быть (в теории)
возможно копировать от
Эта секция обсуждает резервные копии и восстановление от них, используя
репликацию NDB Cluster. Мы предполагаем, что сервера репликации уже
формировались, как покрыто ранее (см.
главу 8.5).
Процедура чтобы сделать резервную копию и затем восстановить
от нее, следующие: Есть два различных метода, которыми может быть
начата резервная копия. Метод A. Этот метод требует, чтобы процесс резервного
копирования группы был ранее позволен на главном сервере до старта процесса
репликации. Это может быть сделано включением следующей строки в раздел
Номер порта должен быть определен, только если порт по умолчанию (1186)
не используется. Посмотрите
главу 4.5.
В этом случае резервная копия может быть начата, выполнив этот
запрос на ведущем репликации: Метод B. Если файл
В нашем сценарии, как обрисовано в общих чертах ранее (см.
главу 8.5),
это было бы выполнено следующим образом: Скопируйте резервные файлы группы ведомому. Каждой системе,
управляющей процессом
ndbd
для основной группы, определят местонахождение резервных файлов и
все эти файлы должны быть скопированы
ведомому, чтобы гарантировать успешное восстановление.
Резервные файлы могут быть скопированы в любой каталог на компьютере, где
находится ведомый хост управления, пока MySQL и NDB имеют право на чтение
этого каталога. В этом случае мы предположим, что эти файлы были скопированы
в каталог Не необходимо, чтобы у ведомой группы было то же самое количество
процессов
ndbd
(узлы данных) как у ведущей, однако, это настоятельно рекомендовано.
Надо, чтобы ведомый был начат с опцией
Создайте любые базы данных на ведомой группе, которые присутствуют на
основной группе и должны копироваться ведомой. Перезагрузите ведомую группу, используя этот
запрос в MySQL Monitor: Можно теперь начать процесс восстановления группы на ведомом
репликации, используя команду
ndb_restore
для каждого резервного файла в свою очередь. Для первого из них
необходимо включить опцию Для восстановления от основной группы с четырьмя узлами данных (как
показано в главе 8), где резервные файлы были
скопированы к каталогу Теперь необходимо получить новую эпоху из таблицы
Используя Если в настоящее время нет никакого трафика репликации, можно получить
эту информацию, выполняя
Используя значения, полученные в предыдущем шаге,
можно теперь выполнить
Теперь, когда ведомый знает
от какой точки в котором файле двоичного журнала начать читать данные от
ведущего, можно заставить ведомого начинать копировать этим
стандартным запросом MySQL: Чтобы выполнить резервную копию и восстановление
на втором канале репликации, необходимо только повторить эти шаги, заменяя
имена хоста и ID вторичного ведущего и ведомого для основных серверов
репликации ведущего и ведомого в соответствующих случаях
и управляя предыдущими запросами на них. Для получения дополнительной информации о резервных копиях и
восстановлении кластера из резервных копий посмотрите
главу 7.3. Возможно автоматизировать большую часть процесса, описанного в
предыдущей секции (см.
главу 8.9).
Следующий скрипт на Perl Восстановление момента времени то есть,
восстановление изменений данных, внесенных начиная с данного момента времени,
выполняется после восстановления полного резервного копирования, которое
возвращает сервер в его состояние, когда резервная копия была сделана.
Выполнение восстановления момента времени таблиц NDB Cluster с
NDB Cluster Replication может быть достигнуто, используя локальную резервную
копию Чтобы выполнить восстановление момента времени NDB Cluster,
необходимо выполнить шаги, показанные здесь: Зарезервируйте все БД В некотором более позднем пункте, до восстановления,
делают резервную копию таблицы
Эта резервная копия должна быть обновлена регулярно, возможно, даже каждый
час, в зависимости от ваших потребностей.
Катастрофический отказ или ошибка происходят. Определите местонахождение последней известной
хорошей резервной копии. Очистите файловые системы узла данных (используя
ndbd
Табличное пространство NDB Cluster Disk Data
и файлы журнала не удалены
Используйте
Выполните
ndb_restore,
восстановив все данные. Необходимо включать опцию
Восстановите таблицу Найдите эпоху, примененную последний раз, то есть, максимум
столбца Найдите последний файл журнала
( С помощью mysqlbinlog
переиграйте двоичные события регистрации от файла и положения до сбоя
(см. mysqlbinlog).
См. также
Point-in-Time (Incremental) Recovery Using the Binary Log
для получения дополнительной информации о двоичной регистрации,
репликации и возрастающем восстановлении. Возможно использовать NDB Cluster в репликации с несколькими ведущими,
включая кольцевую репликацию между многими NDB Cluster. Пример кольцевой репликации.
В следующих нескольких параграфах мы полагаем, что пример установки
репликации, включающей три NDB Cluster 1, 2 и 3, где Cluster 1
действует как ведущий репликации для Cluster 2, Cluster 2 для Cluster 3 и
Cluster 3 для Cluster 1. У каждого кластера есть два узла SQL, с узлами SQL
A и B в Cluster 1, C и D в Cluster 2, E и F в Cluster 3. Кольцевая репликация, используя эти группы поддерживается, пока
следующим условиям отвечают: Узлы SQL на всех ведущих и ведомых то же самое. Все узлы SQL, действующие как ведущие репликации и ведомые, начаты с
включенной системной переменной
Этот тип кольцевой установки репликации показывают
на следующей диаграмме: Рис. 8.6. Кольцевая репликация NDB Cluster В этом сценарии узел SQL A в Cluster 1 копирует к узлу SQL C в
Cluster 2, узел SQL C к узлу SQL E в Cluster 3, а узел
SQL E к узлу SQL A. Другими словами, линия репликации (обозначена
кривыми стрелками на диаграмме) непосредственно соединяет все узлы SQL,
используемые в качестве ведущих репликации и ведомых. Также возможно настроить кольцевую
репликацию таким способом, что не все основные узлы SQL также ведомые,
как показано здесь: Рис. 8.7. Другая кольцевая репликация NDB Cluster В этом случае различные узлы SQL в каждой группе используются в качестве
ведущих репликации и ведомых. Однако, вы не должны
not
начинать ни один из узлов SQL с включенной системной переменной
Применение резервирования и восстановления NDB, чтобы инициализировать
ведомый NDB Cluster.
Настраивая кольцевую репликацию, возможно инициализировать ведомый кластер
при помощи клиента управления (команда Это известная проблема, которую мы намереваемся
решить в будущем выпуске. Пример отказоустойчивости.
В этой секции мы обсуждаем отказоустойчивость в мультиустановке репликации
NDB Cluster с тремя NDB Cluster, имеющими ID сервера 1, 2 и 3. В этом
сценарии Cluster 1 копирует к Clusters 2 и 3, Cluster 2 тоже копирует к
Cluster 3. Эти отношения показывают здесь: Рис. 8.8. NDB Cluster Multi-Master Replication с 3 ведущими Другими словами, данные копируют от Cluster 1 на Cluster 3
через 2 различных маршрута: непосредственно и посредством Cluster 2. Не все серверы MySQL
должны действовать как ведущий и как ведомый, и данный NDB Cluster
мог бы использовать различные узлы SQL для различных каналов репликации.
Такой случай показывают здесь: Рис. 8.9. NDB Cluster Multi-Master Replication с серверами MySQL Серверами MySQL, действующими как ведомые репликации, нужно управлять с
включенной системной переменной
Применение системной переменной
Потребность в отказоустойчивости возникает, когда одна из групп репликации
падает. В этом примере мы рассматриваем случай, где Cluster 1
потерян, таким образом, Cluster 3 теряет 2 источника обновлений от Cluster 1.
Поскольку репликация между NDB Cluster асинхронная, нет никакой гарантии, что
обновления Cluster 3, происходящие непосредственно из Cluster 1,
более свежие, чем полученные через Cluster 2.
Можно обращаться с этим, гарантируя что Cluster 3 предпочтительней Cluster 2
относительно обновлений от Cluster 1.
С точки зрения серверов MySQL это означает, что необходимо копировать любые
обновления от сервера MySQL C к серверу F. На сервере C выполните следующие запросы: Можно улучшить исполнение этого запроса и таким образом, вероятно,
значительно ускорить время отказоустойчивости, добавляя соответствующий
индекс к таблице Скопируйте зачения Как только это было сделано, вы можете скомандовать
Используя установку репликации, вовлекающую много ведущих (включая
кольцевую репликацию) возможно, что различные ведущие могут попытаться
обновить ту же самую строку на ведомом с различными данными. Разрешение
конфликтов в NDB Cluster Replication обеспечивает средство решения таких
конфликтов, разрешая определенной пользователями колонке резолюции
использоваться, чтобы определить, должно ли обновление на данном
ведущем быть применено на ведомом. Некоторые типы разрешения конфликтов поддерживаются NDB Cluster
( Необходимо также иметь в виду, что
обязанность приложения гарантировать, что колонка резолюции правильно
наполнена соответствующими значениями, чтобы функция резолюции могла сделать
соответствующий выбор, определяя, применить ли обновление. Требования. Приготовления к разрешению конфликтов должны быть
сделаны на ведущем и на ведомом. Эти задачи описаны в следующем списке: На ведущем, пишущем двоичные журналы,
необходимо определить, какие колонки посылают (все колонки или только те,
которые были обновлены). Это сделано для MySQL Server в целом, применив
опцию запуска mysqld
Если вы копируете таблицы с очень большими колонками (например,
as См. Replication and max_allowed_packet
для получения дополнительной информации об этой проблеме. На ведомом необходимо определить который тип разрешения
конфликтов применить (latest timestamp wins,
same timestamp wins, primary
wins, primary wins, complete
transaction или none). Это сделано, используя системную таблицу
NDB Cluster также поддерживает прочитанное обнаружение конфликта, то
есть, обнаруживание конфликтов между чтениями
данной строки в одном кластере и обновлением или удалением той же самой
строки в другом кластере. Это требует исключительных блокировок чтения,
полученных, устанавливая
Используя функции Функции Основной контроль за колонкой.
Мы видим операции по обновлению с точки зрения образов
до и после
то есть, статусов таблицы прежде и после того, как обновление будет
применено. Обычно, обновляя таблица с первичным ключом, образ
до не очень интересен, однако, когда мы должны
определить на основе обновления, использовать ли обновленные значения на
ведомом репликации, мы должны удостовериться, что оба образа написаны в
двоичный журнал ведущего. Это сделано с опцией
Сделана ли регистрация полных строк или только обновленных
колонок, решено, когда сервер MySQL начат и не может быть изменено онлайн,
необходимо перезапустить mysqld
или начать новый экземпляр mysqld
с иным вариантом регистрации.
В целях разрешения конфликтов есть два основных метода регистрации
строк, как определено урегулированием опции
Регистрация полных строк. Зарегистрируйте только данные о колонке, которые были обновлены, то
есть данные о колонке, значение которой было установлено, независимо от того,
было ли это значение на самом деле изменено. Это поведение по умолчанию.
Это обычно достаточно и более эффективно зарегистрировать только
обновленные колонки, однако, если необходимо зарегистрировать полные строки,
можно сделать так, установив
Настройка MySQL Server
Чтобы выключить выбор, начните основной
mysqld с
Контроль за разрешением конфликтов.
Разрешение конфликтов обычно позволяется на сервере, где конфликты могут
произойти. Как выбор метода журналирования, это позволено записями в
таблице
Системная таблица ndb_replication.
Чтобы позволить разрешение конфликтов, необходимо создать таблицу
Колонки в этом таблице описаны в следующих нескольких параграфах. db. Название базы данных, содержащей таблицу, которая будет
копироваться. Можно использовать любой или оба из подстановочных знаков
table_name. Название таблицы, которая будет копироваться.
Имя таблицы может включать любой или оба из подстановочных знаков
server_id. Уникальный ID сервера MySQL (узла SQL),
где таблица находится. binlog_type. Тип двоичного журнала.
Это определяется как показано в следующей таблице: Таблица 8.3. Значения binlog_type
с внутренними значениями и описаниями conflict_fn. Функция разрешения конфликтов, которая будет
применена. Эта функция должна быть определена как одно из показанных в
следующем списке значений: Эти функции описаны в следующих нескольких параграфах.
NDB$OLD(column_name).
Если значение
Эта функция может использоваться для разрешения конфликтов
same value wins.
Этот тип разрешения конфликтов гарантирует, что обновления не применяются
на ведомом от неправильного ведущего. Значение столбца от образа ведущего до
используется этой функцией.
NDB$MAX(column_name).
Если значение столбца timestamp
для данной строки, прибывающей от ведущего, выше, чем это на ведомом, оно
применяется, иначе это не применяется на ведомом.
Это иллюстрировано следующим псевдокодом:
Эта функция может использоваться для разрешения конфликтов
greatest timestamp wins.
Этот тип разрешения конфликтов гарантирует, что в случае конфликта версия
строки, которая была последний раз обновлена, является
версией, которая сохраняется. Значение столбца от ведущего образа после
используется этой функцией.
NDB$MAX_DELETE_WIN().
Вариант
Эта функция может использоваться для разрешения конфликтов
greatest timestamp, delete wins.
Этот тип разрешения конфликтов гарантирует, что в случае конфликта версия
строки, которая была удалена или последний раз обновлена, является
версией, которая сохраняется. Как с
NDB$EPOCH() и NDB$EPOCH_TRANS().
Функция Большая часть того, что следует в описании
Когда ведомый первичный обнаруживает конфликты, они вводят события в свою
собственную двоичную регистрацию, чтобы дать компенсацию за них,
это гарантирует, что вторичный NDB Cluster
в конечном счете перестраивает себя с первичным и так первичный и вторичный
работают вместе без отклонения.
Этот механизм компенсации и перестройки требует, чтобы основной NDB Cluster
всегда выигрывал любые конфликты со вторичным то есть, что всегда
используются изменения первичного, а не от вторичного в случае конфликта. Эти
правила primary always wins
имеют следующие последствия: Операции, которые изменяют данные, когда-то переданные на
первичном, полностью постоянные и не будут отменены или откачены до прежнего
уровня обнаружением конфликта и резолюцией. Данные, прочитанные из первичного,
полностью последовательны. Любые изменения, переданные на первичном
(в местном масштабе или от ведомого), не изменятся позже. Операции, которые изменяют данные на вторичном, могут позже
измениться, если первичный решает, что они находятся в конфликте. Отдельные строки, прочитанные на вторичном, последовательны в любом
случае, каждая строка всегда отражает статус, переданный вторичным, или
передачу от первичного. Наборы строк, прочитанных на вторичном, могут не обязательно быть
последовательными в данном единственном моменте времени. Для
Принимая период достаточной длины без любых конфликтов, все данные по
вторичному NDB Cluster в конечном счете становятся согласовывающимися с
данными первичного кластера. Каждая из функций Для значений по умолчанию этих параметров конфигурации (2000 и 100
миллисекунд, соответственно), это дает значение 5 битов, таким образом,
значение по умолчанию (6) должно быть достаточным, если другие значения
не используются для
Как с другими функциями обнаружения конфликта, обсужденными в этой секции,
Поскольку алгоритмы обнаружения конфликта, используемые
Конфликт между операциями
Переменные статуса обнаружения конфликта.
Несколько переменных статуса могут использоваться, чтобы контролировать
обнаружение конфликта. Вы видите, сколько строк были найдены в конфликте
См. главу
5.3.9.3.
Ограничения на NDB$EPOCH().
Следующие ограничения в настоящее время применяются, используя
Конфликты обнаружены, используя границы эпохи NDB Cluster
со степенью детализации, пропорциональной
Дополнительное хранение требуется для таблиц, используя функции
Конфликты между операциями удаления
могут привести к расхождению между первичным и вторичным.
Когда строка удалена на обеих группах одновременно, конфликт может быть
обнаружен, но не зарегистрирован, так как строка удалена. Это означает, что
дальнейшие конфликты во время распространения любых последующих операций по
перестройке не будут обнаружены, что может привести к расхождению. Удаление должно быть внешне преобразовано в последовательную форму или
маршрутизировано только к одному кластеру.
Альтернативно отдельная строка должна быть обновлена транзакционно
с таким удалением и любыми вставками, которые следуют за ним, так, чтобы
конфликты могли быть прослежены через удаление строки.
Это может потребовать изменений в запросах. Только два NDB Cluster в кольцевой конфигурации
active-active
в настоящее время поддерживаются, используя
Таблицы со столбцами
NDB$EPOCH_TRANS().
Кроме того, любые транзакции, которые обнаружимо зависят от противоречивой
транзакции, также расцениваются как конфликтные,
определяемые содержанием двоичной регистрации вторичного кластера.
Так как двоичная регистрация содержит только операции по модификации данных
(вставки, обновления и удаления), только накладывающиеся модификации данных
используются, чтобы определить зависимости между транзакциями. См.
NDB$EPOCH() и NDB$EPOCH_TRANS(). Информация о статусе. Переменная статуса сервера
Число раз, которое строка не была применена как результат разрешения
конфликтов same timestamp wins на данном
mysqld
с прошлого раза, когда это было перезапущено, дано глобальной переменной
статуса
NDB$EPOCH2().
Функция
NDB$EPOCH2_TRANS().
Где При использовании Необходимо также знать что, отражая все операции от вторичного назад
первичному увеличивается размер регистрации на первичном, а также требования
к пропускной способности, использованию CPU и дисковому I/O. Применение отраженных операций на вторичном зависит от статуса целевой
строки на вторичном. Применяются ли отраженные изменения на вторичном, может
быть прослежено, проверив переменные статуса
События применяются, если и только если оба из
следующих условий верны: Существование строки то есть, существует ли это в соответствии с
типом события. Для операции удаления и обновления строка должна уже
существовать. Для операций по вставке не должна. Строка была в последний раз изменена первичным.
Возможно, что модификация была достигнута посредством
выполнения отраженной операции. Если оба из условий не соблюдаются, от отраженной
операции отказывается вторичный.
Таблица исключений разрешения конфликтов.
Чтобы использовать функцию разрешения конфликтов
Первые четыре колонки требуются. Названия первых четырех колонок и
колонок, соответствующих колонкам первичного ключа оригинальной таблицы, не
очень важны, однако, мы предлагаем по причинам ясности и последовательности,
что вы используете имена, показанные здесь для столбцов
Если таблица исключений использует одну или больше дополнительных колонок
После этих колонок столбцы, составляющие первичный ключ оригинальной
таблицы, должны быть скопированы в порядке, в котором они используются, чтобы
определить первичный ключ оригинальной
таблицы. Типы данных для колонок, дублирующих колонки первичного ключа
оригинальной таблицы, должны быть таким же (или больше), как первоначальные
столбцы. Подмножество колонок первичного ключа может использоваться. Независимо от используемой версии NDB Cluster,
таблица исключений должна использовать механизм
Дополнительные колонки могут произвольно быть определены после
скопированных колонок первичного ключа, но не перед любой
из них, любые такие дополнительные столбцы не могут быть
Типы операций
Дополнительные справочные колонки, которые не являются частью первичного
ключа оригинальной таблицы, можно назвать
Таблица Следующие примеры предполагают, что у вас уже есть установка репликации
NDB Cluster как описано в главах
8.5 и
8.6.
Пример NDB$MAX(). Предположим, что вы хотите позволить
разрешение конфликтов greatest timestamp
wins на таблице Удостоверьтесь, что вы начали основной
mysqld м
-На ведущем выполните такой
Вставка 0 в
Вставка Создайте таблицу Теперь, когда обновления сделаны на этой
таблице, разрешение конфликтов применяется, и версия строки, имеющей
самую большую значение для Другие варианты
Пример NDB$OLD(). Предположим, что таблица
Следующие шаги требуются в показанном порядке: Сначала ДО создания
Возможные значения для столбца Составьте соответствующую таблицу исключений для
Мы можем включать дополнительные колонки для получения информации о типе,
причине и ID происходящей транзакции для данного конфликта. Мы также не
обязаны поставлять соответствие колонкам для всех колонок первичного ключа в
оригинальной таблице. Это означает, что можно
составить таблицу исключений: Префикс Создайте таблицу Эти шаги должны быть выполнены для каждой таблицы,
для которой вы хотите выполнить использование разрешения конфликтов
Обнаружение конфликта чтения и резолюция.
NDB Cluster также поддерживает отслеживание операций чтения, которое
позволяет в кольцевых установках репликации справиться с конфликтами чтения
данной строки в одной группе и обновлением или удалением той же самой строки
в другом кластере. Этот пример использует таблицы
Таблицы данных были созданы, используя следующие SQL-операторы: Содержание этих двух таблиц включает строки, показанные в (частичном)
выводе следующего запроса
Мы предполагаем, что уже используем таблицу
исключений, которая включает четыре необходимых колонки (и они используются
для первичного ключа этой таблицы), дополнительные колонки для операционного
типа и причины и колонку первичного ключа оригинальной таблицы, созданную с
использованием SQL-оператора, показанного здесь: Предположим там происходят две одновременных транзакции на этих двух
кластерах. В кластере A
мы создаем новый отдел, затем перемещаем сотрудника номер 999 в тот
отдел, используя следующие SQL-операторы: В то же время на кластере B
другая транзакция читает из Противоречивые транзакции обычно не обнаруживаются механизмом разрешения
конфликтов, так как конфликт между чтением
( Конфликт зарегистрирован в таблице исключений (на
A) как операция
Любые существующие строки, найденные в операции чтения, отмечаются.
Это означает, что многократные строки, следующие из того же самого конфликта,
могут войти в таблицу исключений, как показано исследовав эффекты конфликта
между обновлением на кластере A и
чтение многократных строк на кластере
B от той же самой таблицы в
одновременных транзакциях. Транзакцию, выполненную на кластере
A, показывают здесь: Одновременно транзакция, содержащая запросы, показанные здесь, работает на
кластере B: В этом случае все три строки, соответствующие
Отслеживание чтений выполняется только на основе существующих строк.
Чтение на основе данного условия отслеживает конфликты только любых строк,
которые найдены,
а не любых строк, которые вставляются в чередованную транзакцию.
Это подобно тому, как исключительная блокировка строки выполняется в
единственном экземпляре NDB Cluster.
Глава 8. NDB Cluster Replication
NDB.NDB
для объединения в кластеры функциональности, не столь необходимо использовать
NDB
как механизм хранения ведомого для копируемых таблиц (см.
здесь). Однако, для максимальной доступности возможно (и предпочтительно)
копировать от одного NDB Cluster на другой
и именно этот сценарий мы обсуждаем.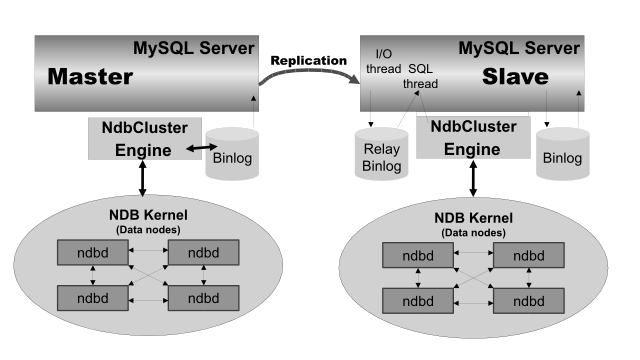
binlog). Это гарантирует, что все изменения в
группе, производящей регистрацию (а не только те изменения, которые вызваны
через MySQL Server), вставляются в регистрацию с правильным порядком
преобразования в последовательную форму. Мы обращаемся к ведущему и
ведомым серверам MySQL как к серверам репликации или узлам, поток данных или
линия связи между ними известна как
канал репликации._slave, как замечено в выводе
SHOW STATUS или в
результатах запросов к таблицам
SESSION_STATUS или
GLOBAL_STATUS
в сессии клиента mysql,
связанного с MySQL Server, который действует как ведомый в NDB Cluster
Replication. Сравнивая значения этих переменных статуса прежде и после того,
как выполнение воздействия запросов копируется в таблицы
NDB,
можно наблюдать соответствующие действия на уровне NDB API,
что может быть полезным, контролируя или исследуя NDB Cluster Replication.
Глава 7.17
предоставляет дополнительную информацию.NDB с
NDB Cluster к таблицам, используя другие механизмы хранения MySQL, такие как
InnoDB или
MyISAM на ведомом
mysqld.
Это подчиняется многим условиям, посмотрите
здесь и
здесь.
8.1. NDB Cluster Replication: символы и сокращения
Обозначение
Смысл MГруппа, служащая (основным) ведущим репликации SГруппа, действующая как (основной) ведомый репликации shell
M>Команда, которая будет выполнена на основной группе mysql
M>Команда клиента MySQL, данная на единственном сервере MySQL, работающем
как узел SQL на основной группе mysql
M*>Команда клиента MySQL
на всех узлах SQL, участвующих в группе ведущего репликации shell
S>Команда, которая будет выполнена на ведомой группе mysql
S>Команда клиента MySQL, данная на единственном сервере MySQL, работающем
как узел SQL на ведомой группе mysql
S*>Команда клиента MySQL
на всех узлах SQL, участвующих в ведомой группе репликации CОсновной канал репликации C'Вторичный канал репликации M'Вторичный ведущий репликации S'Вторичный ведомый репликации
8.2. Основные требования для NDB Cluster Replication
--binlog-format=ROW или
--binlog-format=MIXED, как
описано в главе 8.6
. Для получения общей информации о построчной репликации посмотрите
здесь.--binlog-format=STATEMENT
репликация не работает правильно потому, что таблица
ndb_binlog_index на ведущем и столбец
epoch таблицы
ndb_apply_status на ведомом не обновляется (см.
главу 8.4).
Вместо этого только обновления на сервере MySQL, действующем как ведущий
репликации, размножаются ведомому, но никакие обновления от любых других
узлов SQL ведущего кластера не копируются.--binlog-format в NDB 7.5
MIXED.--server-id=
, где idid
уникальное целое число. Хотя это не строго необходимо, мы предположим в целях
этого обсуждения, что все выполняемые модули NDB Cluster
имеют ту же самую версию выпуска.NDB
должны быть составлены, используя сервер MySQL и клиент. Таблицы и другие
объекты базы данных, созданные с использованием API NDB (например,
Dictionary::createTable()),
невидимы серверу MySQL и не копируются. Могут копироваться обновления
приложениями API NDB к существующим таблицам, которые были составлены,
используя сервер MySQL.
8.3. Известные проблемы в NDB Cluster Replication
MaxBufferedEpochs и
TimeBetweenEpochs). Если это происходит,
для новых данных возможно быть вставленными в
основной кластер, не будучи зарегистрированными в двоичном журнале
ведущего репликации. Поэтому, чтобы гарантировать высокую
доступность, чрезвычайно важно поддержать канал репликации резервных данных,
контролировать основной канал и быть в состоянии перейти к вторичному каналу
репликации при необходимости сохранить ведомый кластер
синхронизированным с ведущим. NDB Cluster не разработан, чтобы выполнить
такой контроль самостоятельно, для этого требуется внешнее приложение.SHOW SLAVE STATUS
и указывает, что поток SQL остановился из-за инцидента, зарегистрированного в
потоке репликации, и что ручное вмешательство требуется. Посмотрите
главу 8.8
для получения дополнительной информации о том, что сделать
при таких обстоятельствах.log_slave_updates.
log_slave_updates.
Этот тип кольцевой схемы репликации NDB Cluster, в которой линия репликации
(снова обозначена кривыми стрелками на диаграмме) прерывиста, должен быть
возможным, но нужно отметить, что это полностью еще не проверили и поэтому
все еще считается экспериментальным.NDB
использует идемпотентный способ выполнения,
который подавляет дублирование ключа и другие ошибки, которые иначе ломают
кольцевую репликацию в NDB Cluster. Это эквивалентно урегулированию
глобальной системной переменной
slave_exec_mode в
IDEMPOTENT, хотя это не необходимо в
репликации NDB Cluster, так как NDB Cluster
устанавливает эту переменную автоматически и игнорирует любые
попытки установить ее явно.NDB, таблицы
без первичных ключей могут все еще произойти, из-за возможности
дублирующихся строк, вставляемых в таких случаях.
Поэтому настоятельно рекомендовано всем таблицам
NDB
иметь первичные ключи.NDB,
могли привести к ошибкам дублирования ключа, когда копируются.
Эта проблема решена для репликации между таблицами
NDB, отсрочивая проверки
уникального ключа до окончания всех обновлений строки таблицы.NDB.
Таким образом, обновления уникальных ключей, копируя от
NDB
к различному механизму хранения, такому как
MyISAM или
InnoDB,
все еще не поддерживаются.NDB. Например, таблица
t создается на ведущем (и копируется ведомому,
который не поддерживает отсроченные обновления уникального ключа),
как показано здесь:
CREATE TABLE t (p INT PRIMARY KEY, c INT, UNIQUE KEY u (c)) ENGINE NDB;
INSERT INTO t VALUES (1,1), (2,2), (3,3), (4,4), (5,5);
UPDATE на
t выполняется на ведущем, так как затронутые
строки обрабатываются в порядке, определенном
ORDER BY:
UPDATE t SET c = c - 1 ORDER BY p;
NDB
неявно разделена ключом, когда это создается. Посмотрите
KEY Partitioning.NDB,
и не поддерживается. Предоставление возможности GTID, вероятно, заставит
репликацию NDB Cluster Replication отвалится.slave_parallel_workers,
slave_checkpoint_group и
slave_checkpoint_group
(или аналогичные опции запуска
mysqld) не работают.NDB,
включает по крайней мере две базы данных: целевую и системную
mysql из-за требования для обновления таблицы
mysql.ndb_apply_status (см.
глава 8.4).
Это в свою очередь ломает требование для мультипоточности, что транзакция
определена для данной базы данных.--initial
заставляет последовательность GCI и чисел эпохи начинаться с
0. Это обычно верно для NDB Cluster
и не ограничено сценариями репликации, включающими Cluster.
Серверы MySQL, вовлеченные в репликацию, должны в этом случае быть
перезапущены. После этого необходимо использовать
RESET MASTER и
RESET SLAVE, чтобы очистить
таблицы ndb_binlog_index и
ndb_apply_status.NDB на ведущем к таблицам, используя
иной механизм хранения на ведомом, принимая во внимание
ограничения, перечисленные здесь:NDB для этого).--ndb-log-update-as-write=0 или
--ndb-log-update-as-write=OFF.NDB к иному
механизму хранения отношения между этими двумя базами данных должны быть
просто "главный-подчиненный". Это означает, что кольцевая или
ведущий-ведущий репликация не поддерживается между NDB Cluster
и другими механизмами хранения.NDB
и другим механизмом хранения. Однако, база данных NDB Cluster
может
одновременно копироваться к многим ведомым базам данных NDB Cluster.
Если ведущий использует таблицы
NDB, все еще возможно иметь больше, чем один MySQL Server,
который поддерживает двоичную регистрацию всех изменений.
Однако, для ведомого, чтобы изменить ведущих, новые отношения
"главный-подчиненный" должны быть явно определены на ведомом.sql_log_bin = 0.ALTER TABLE
mysql.ndb_apply_status ENGINE=MyISAM на ведомом.
Безопасно сделать это, используя
не-NDB
механизм хранения на ведомом, так как вы не должны тогда волноваться по
поводу поддержания синхронизированными узлов SQL.
--replicate-ignore-table=mysql.ndb_apply_status.
Если вы должны для других таблиц проигнорировать репликацию, вы могли бы
использовать соответствующую опцию
--replicate-wild-ignore-table.
mysql.ndb_apply_status
или изменять механизм хранения, используемый для этой таблицы, копируя от
одного NDB Cluster к другому. См.
здесь.NDB
к нетранзакционному механизму хранения, такому как
MyISAM,
можно столкнуться с ошибками дублирования ключа, копируя
INSERT ... ON DUPLICATE KEY UPDATE
. Можно подавить их при помощи
--ndb-log-update-as-write=0,
который вынуждает обновления быть зарегистрированными как записи,
а не как обновления.--replicate-do-*,
--replicate-ignore-*,
--binlog-do-db или
--binlog-ignore-db,
чтобы отфильтровать базы данных или копируемые таблицы, нужно соблюдать
осторожность, чтобы не заблокировать репликацию или двоичный журнал
mysql.ndb_apply_status,
что требуется для репликации между NDB Cluster.
В частности необходимо иметь в виду следующее:--replicate-do-db=
(но не других db_name--replicate-do-* или
--replicate-ignore-*), означает что
ТОЛЬКО таблицы в базе данных
db_name
копируются. В этом случае необходимо также использовать
--replicate-do-db=mysql,
--binlog-do-db=mysql или
--replicate-do-table=mysql.ndb_apply_status, чтобы
гарантировать, что mysql.ndb_apply_status
заполнена на ведомых.--binlog-do-db=
(но не других
db_name--binlog-do-db)
означает что изменения только
таблиц в базе данных db_name
написаны двоичной регистрации. В этом случае необходимо также использовать
--replicate-do-db=mysql,
--binlog-do-db=mysql или
--replicate-do-table=mysql.ndb_apply_status,
чтобы гарантировать, что mysql.ndb_apply_status
заполнена на ведомых.--replicate-ignore-db=mysql
значит, что никакие таблицы в БД mysql
не копируются. В этом случае необходимо также использовать
--replicate-do-table=mysql.ndb_apply_status, чтобы скопировать
to ensure that mysql.ndb_apply_status.--binlog-ignore-db=mysql
значит, что никакие изменения таблиц в БД mysql
не написаны двоичной регистрации. В этом случае необходимо также использовать
--replicate-do-table=mysql.ndb_apply_status, чтобы скопировать
mysql.ndb_apply_status.--replicate-do-* или
--replicate-ignore-*
и что многочисленные правила нельзя выразить в единственном выборе фильтрации
репликации. Для получения информации об этих правилах посмотрите
Replication and Binary Logging Options and Variables
.--binlog-do-db или
--binlog-ignore-db
и что многочисленные правила нельзя выразить в единственной двоичной
регистрации, фильтрующей выбор. Для получения информации об этих правилах
посмотрите The Binary Log.NDB,
эти соглашения могут не работать.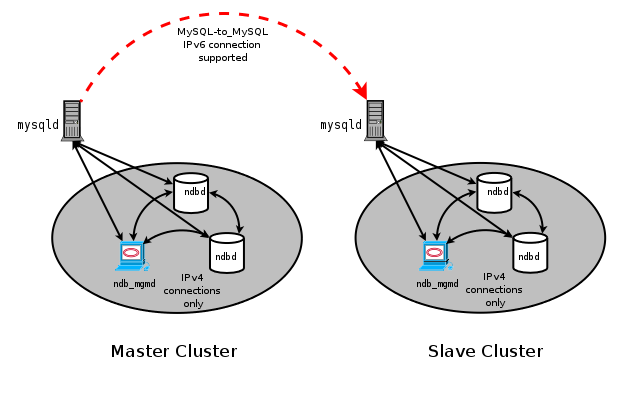
slave_type_conversions.NDB, в отличие от
InnoDB или
MyISAM,
не пишет изменения виртуальных колонок в двоичный журнал.
Однако, это не имеет никаких неблагоприятных эффектов на репликацию NDB
Cluster или репликацию между NDB
и другими механизмами хранения. Изменения сохраненных
произведенных колонок зарегистрированы.
8.4. Схема репликации и таблицы NDB Cluster
mysql на каждом MySQL Server, действующим
как узел SQL, в копируемой группе и в ведомом репликации. Эти таблицы
составлены во время процесса установки MySQL и включают таблицу для того,
чтобы хранить данные об индексации двоичной регистрации. Начиная с
ndb_binlog_index
таблицы местные к каждому серверу MySQL и не участвуют в объединении в
кластеры, это использует механизм InnoDB.
Это означает, что должно быть создано отдельно на каждом
mysqld, участвующем в основном
кластере. Однако, сама двоичная регистрация содержит обновления от всех
серверов MySQL в кластере, который будет копироваться.
Эта таблица определяется следующим образом:
CREATE TABLE `ndb_binlog_index` (`Position` BIGINT(20) UNSIGNED NOT NULL,
`File` VARCHAR(255) NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`inserts` INT(10) UNSIGNED NOT NULL,
`updates` INT(10) UNSIGNED NOT NULL,
`deletes` INT(10) UNSIGNED NOT NULL,
`schemaops` INT(10) UNSIGNED NOT NULL,
`orig_server_id` INT(10) UNSIGNED NOT NULL,
`orig_epoch` BIGINT(20) UNSIGNED NOT NULL,
`gci` INT(10) UNSIGNED NOT NULL,
`next_position` bigint(20) unsigned NOT NULL,
`next_file` varchar(255) NOT NULL,
PRIMARY KEY (`epoch`,`orig_server_id`,
`orig_epoch`)) ENGINE=InnoDB
DEFAULT CHARSET=latin1;
MyISAM.
Если вы модернизируете от более раннего выпуска, можно использовать
mysql_upgrade с опциями
--force и
--upgrade-system-tables,
чтобы заставить его выполнять
ALTER TABLE ...
ENGINE=INNODB на этой таблице. Использование
MyISAM для этой таблицы продолжает
поддерживаться в NDB 7.5.2 и позже для обратной совместимости.ndb_binlog_index
может потребовать дополнительного дискового пространства, будучи
преобразованной в InnoDB.
Если это становится проблемой, можно быть в состоянии сохранить
пространство при помощи табличного пространства
InnoDB для этой таблицы, изменяя
ROW_FORMAT на
COMPRESSED. См.
see CREATE TABLESPACE Statement и
CREATE TABLE Statement, а также
Tablespaces.ndb_binlog_index,
даже когда
--ndb-log-empty-epochs =
OFF,
то есть количество записей на файл зависит от отрезка времени,
которое файл используется.
[Число эпох на файл] = [time spent per file] /
TimeBetweenEpochs
--ndb-log-empty-epochs=ON
может на самом деле иметь намного более высокое количество строк
ndb_binlog_index
на файл, чем кластер с большой деятельностью.--ndb-log-orig,
orig_server_id и
orig_epoch хранят ID сервера, на котором
порождено событие, и эпоху, в которую событие произошло на сервере, что
полезно в установках репликации NDB Cluster, используя многократных ведущих.
SELECT
раньше находил самое близкое положение двоичной регистрации к самой высокой
прикладной эпохе на ведомом в мультиосновной установке (см.
главу 8.10
), используя эти две колонки, которые не внесены в индекс.
Это может привести к исполнительным проблемам, пытаясь свалиться, так как
запрос должен выполнить сканирование таблицы, особенно когда ведущий работал
с
--ndb-log-empty-epochs=ON.
Можно улучшить времена отказоустойчивости, добавляя индекс к этим колонкам,
как показано здесь:
ALTER TABLE mysql.ndb_binlog_index
ADD INDEX orig_lookup USING BTREE (orig_server_id, orig_epoch);
orig_server_id или
orig_epoch.next_position и
next_file.mysql.ndb_binlog_index.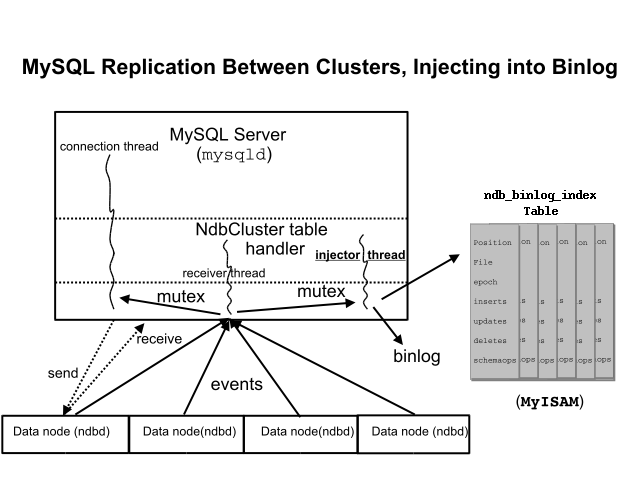
ndb_apply_status
используется, чтобы вести учет операций, которые копировались от ведущего
ведомому. В отличие от случая с
ndb_binlog_index,
данные в этой таблице не определены ни для какого узла SQL в (ведомом)
кластере, и таким образом,
ndb_apply_status может использовать механизм
NDBCLUSTER:
CREATE TABLE `ndb_apply_status` (`server_id` INT(10) UNSIGNED NOT NULL,
`epoch` BIGINT(20) UNSIGNED NOT NULL,
`log_name`VARCHAR(255) CHARACTER SET latin1
COLLATE latin1_bin NOT NULL,
`start_pos` BIGINT(20) UNSIGNED NOT NULL,
`end_pos` BIGINT(20) UNSIGNED NOT NULL,
PRIMARY KEY (`server_id`) USING HASH)
ENGINE=NDBCLUSTER DEFAULT CHARSET=latin1;
ndb_apply_status
наполнена только на ведомых, что означает, что на ведущем эта таблица никогда
не содержит строк, таким образом нет никакой потребности допускать
DataMemory или
IndexMemory для
ndb_apply_status там.ndb_apply_status
или ведущий написал в двоичный журнал, может блокировать репликацию.
Для получения дополнительной информации о потенциальных проблемах, являющихся
результатом таких правил фильтрации, посмотрите
здесь.ndb_binlog_index и
ndb_apply_status составлены в БД
mysql потому,
что они не должны явно копироваться пользователем. Вмешательство пользователя
обычно не требуется, чтобы создать или поддержать любую из этих таблиц,
начиная с ndb_binlog_index и
ndb_apply_status. Это сохраняет основной процесс
mysqld
обновленным к изменениям, выполненным
NDB.
NDB
binlog injector thread
получает события непосредственно из механизма
NDB.
NDB
инжектор ответственен за захват всех событий данных в группе и гарантирует,
чтобы все события, которые изменили, вставили или удалили данные,
зарегистрированы в таблице ndb_binlog_index.
Ведомый поток I/O передает события от двоичной регистрации ведущего
до регистрации ведомого.mysql.ndb_binlog_index
непосредственно на ведущем. Это может быть также быть достигнуто, используя
SHOW BINLOG EVENTS
о ведущем или о ведомом сервере репликации MySQL. См.
SHOW BINLOG EVENTS Statement.SHOW ENGINE NDB STATUS.NDB,
запросы должны ждать окончания запроса
ALTER TABLE на связи с
клиентом MySQL, который сделал запрос, прежде чем попытаться использовать
обновленное определение таблицы.ndb_apply_status нет,
на ведомом,
ndb_restore
ее пересоздаст.mysql.ndb_replication.
В настоящее время эта таблица должна быть составлена вручную.
Для получения информации о том, как сделать это, посмотрите
главу 8.11.
8.5. Подготовка NDB Cluster для репликации
mysqlM> GRANT REPLICATION SLAVE ON *.*
TO 'slave_user'@'slave_host'
IDENTIFIED BY 'slave_password';
slave_user это имя пользователя,
slave_host это имя хоста или
IP-адрес ведомого репликации и
slave_password это пароль.myslave для входа в систему от хоста
rep-slave с паролем
53cr37, используйте такой запрос
GRANT:
mysqlM> GRANT REPLICATION SLAVE
ON *.* TO 'myslave'@'rep-slave'
IDENTIFIED BY '53cr37';
CHANGE MASTER TO:
mysqlS> CHANGE MASTER TO MASTER_HOST='master_host',
MASTER_PORT=master_port, MASTER_USER='slave_user',
MASTER_PASSWORD='slave_password';
master_host
это имя хоста или IP-адрес ведущего репликации,
master_port это порт для ведомого,
чтобы использовать для соединения с ведущим,
slave_user
это имя пользователя, настроенное для ведомого на ведущем, и
slave_password
пароль для этой учетной записи пользователя.rep-master, с использованием ведомого
репликации, созданного на предыдущем шаге, используйте следующий запрос:
mysqlS> CHANGE MASTER TO MASTER_HOST='rep-master',
MASTER_PORT=3306, MASTER_USER='myslave',
MASTER_PASSWORD='53cr37';
--ndb-connectstring в файл
my.cnf ведомого до старта процесса репликации.
Посмотрите
главу 8.9.my.cnf для ведомых репликации посмотрите
Replication and Binary Logging Options and Variables
.
ndb-connectstring=management_host[:port]
shellM> mysqldump --master-data=1
dump_file это
название файла, который был произведен, используя
mysqldump
на ведущем, а db_name это
название базы данных, которая будет копироваться:
shellS> mysql -u root -p db_name < dump_file
--skip-slave-start
или иначе включить skip-slave-start в его файл
my.cnf, чтобы помешать ему пытаться соединиться
с ведущим, чтобы начать копировать до загрузки всех данных.
Как только загрузка данных закончена, выполните дополнительные шаги,
обрисованные в общих чертах в следующих двух секциях.my.cnf главного сервера
или в командной строке, начиная основной процесс
mysqld. См.
главу 8.6.
8.6. Старт NDB Cluster Replication (единственный канал репликации)
shellM> mysqld --ndbcluster --server-id=id --log-bin &
id это
уникальный идентификатор этого сервера (см.
главу 8.2).
Это начинает процесс mysqld
с включенным двоичным журналом, чтобы использовать
надлежащий формат регистрации.--binlog-format=MIXED,
в этом случае построчная репликация используется автоматически, копируя между
группами. Журнал в режиме STATEMENT
не поддерживается для NDB Cluster Replication (см.
главу 8.2
).
shellS> mysqld --ndbcluster --server-id=id &
id это уникальный
идентификатор сервера ведомого. Нет необходимости включать
журналирование ведомого репликации.--skip-slave-start
с этой командой или иначе необходимо включать
skip-slave-start в файле
my.cnf ведомого, если вы не хотите, чтобы
репликация немедленно началась. С использованием этого выбора начало
репликации задержано до соответствующей команды
appropriate START SLAVE, как
объяснено в шаге 4 ниже.
mysqlS> CHANGE MASTER TO MASTER_LOG_FILE='', MASTER_LOG_POS=4;
MASTER_LOG_FILE и
MASTER_LOG_POS в таких случаях.
mysql
S> START SLAVE;
slave_allow_batching на ведомом
mysqld.
Обычно обновления применяются, как только они получены.
Однако, использование группирования обновлений собирает их в пакеты
по 32 КБ, что может привести к более высокой пропускной способности и
меньшему использованию CPU, особенно там, где отдельные
обновления относительно маленькие.
SET GLOBAL slave_allow_batching = 1;
SET GLOBAL slave_allow_batching = ON;
SET GLOBAL slave_allow_batching = 0;
SET GLOBAL slave_allow_batching = OFF;
SHOW VARIABLES:
mysql> SHOW VARIABLES LIKE 'slave%';
+---------------------------+-------+
| Variable_name | Value |
+---------------------------+-------+
| slave_allow_batching | ON |
| slave_compressed_protocol | OFF |
| slave_load_tmpdir | /tmp |
| slave_net_timeout | 3600 |
| slave_skip_errors | OFF |
| slave_transaction_retries | 10 |
+---------------------------+-------+
6 rows in set (0.00 sec)
8.7. Используя два канала репликации для NDB Cluster Replication
Server ID Описание 1
Ведущий основной канал
(M) 2
Ведущий вторичный канал
(M') 3
Ведомый основной канал
(S) 4
Ведомый вторичный канал
(S') START SLAVE
на каждом из ведомых. Команды и порядок, в котором они должны быть
выпущены, показывают здесь:
shellM> mysqld --ndbcluster --server-id=1 --log-bin &
shellM'> mysqld --ndbcluster --server-id=2 --log-bin &
shellS> mysqld --ndbcluster --server-id=3 --skip-slave-start &
shellS'> mysqld --ndbcluster --server-id=4 --skip-slave-start &
START SLAVE
на основном ведомом как показано здесь:
mysql
S> START SLAVE;
8.8. Осуществление отказоустойчивости с NDB Cluster Replication
ndb_apply_status на ведомом, которая
может быть найдена, используя следующий запрос:
mysqlS'> SELECT @latest:=MAX(epoch) FROM mysql.ndb_apply_status;
ndb_log_apply_status=1, эпохи NDB Cluster
написаны в двоичный журнал ведомого. Это означает, что таблица
ndb_apply_status
содержит информацию для ведомого на этом хосте, а также для любого другого
хоста, который действует как ведомый ведущего на этом хосте.IGNORE_SERVER_IDS запроса
CHANGE MASTER TO,
которым раньше настраивали этого ведомого. Причина исключения таких эпох
в том, что строки в таблице
mysql.ndb_apply_status, у сервера которых ID
совпадает с IGNORE_SERVER_IDS в списке,
используемом с CHANGE MASTER TO, которым раньше готовили ведущего этого
ведомого, также считается от локальных серверов, в дополнение к тем, которые
имеют собственный ID сервера ведомого. Можно восстановить этот список как
Replicate_Ignore_Server_Ids из вывода
SHOW SLAVE STATUS.
Мы предполагаем, что вы получили этот список и заменяете им
ignore_server_ids
в запросе, показанном здесь, который как предыдущая версия запроса, выбирает
самую большую эпоху в переменную
@latest:
mysqlS'> SELECT @latest:=MAX(epoch) FROM mysql.ndb_apply_status
WHERE server_id NOT IN (ignore_server_ids);
server_id IN
в части
server_id_listWHERE предыдущего запроса.ndb_binlog_index на основном кластере.ndb_binlog_index ведущего:
mysqlM'> SELECT @file:=SUBSTRING_INDEX(next_file, '/', -1),
@pos:=next_position FROM mysql.ndb_binlog_index
WHERE epoch >= @latest ORDER BY epoch ASC LIMIT 1;
@latest, чтобы
представлять значение, полученное в шаге 1. Конечно, невозможно для
одного mysqld
обратиться к переменным пользователя на другом экземпляре сервера
непосредственно. Эти значения должны быть вставлены
во второй запрос вручную или в коде приложения.--slave-skip-errors=ddl_exist_errors
перед выполнением
START SLAVE.
Иначе репликация может остановиться с ошибками дублирования DDL.
mysqlS'> CHANGE MASTER TO MASTER_LOG_FILE='@file', MASTER_LOG_POS=@pos;
@file и @pos),
чтобы представлять значения, полученные в шаге 2 и примененные в шаге 3.
На практике эти значения должны быть вставлены вручную или используя код
приложения, которое может получить доступ к обоим из включенных серверов.@file это значение последовательности, такое
как '/var/log/mysql/replication-master-bin.00001'
, оно должно быть указано, когда используется в SQL или коде
приложения. Однако, значение, представленное
@pos,
НЕ должно быть цитировано.
Хотя MySQL обычно пытается преобразовать последовательности в числа,
этот случай исключение.
mysql
S'> START SLAVE;
M на
S' или от
M' на
S.
Однако, это еще не было проверено.
8.9. Резервирование NDB Cluster с NDB Cluster Replication
[mysql_cluster] файла
my.cnf file, где
management_host это
IP-адрес или имя хоста сервера управления
NDB
для основного кластера, а port
это номер порта сервера управления:
ndb-connectstring=management_host[:port]
shellM> ndb_mgm -e "START BACKUP"
my.cnf не определяет, где найти хост
управления, можно начать процесс резервного копирования, передав эту
информацию клиенту управления
NDB как часть команды
START BACKUP.
Это может быть сделано как показано здесь, где
management_host и
port
имя хоста и номер порта сервера управления:
shellM> ndb_mgm management_host:port -e "START BACKUP"
shellM> ndb_mgm rep-master:1186 -e "START BACKUP"
/var/BACKUPS/BACKUP-1.--skip-slave-start,
чтобы предотвратить преждевременный запуск процесса репликации.CREATE DATABASE (или
CREATE SCHEMA),
соответствующий каждой базе данных, которая будет копироваться, должен быть
выполнен на каждом узле SQL в ведомой группе.
mysql
S> RESET SLAVE;
-m, чтобы
восстановить метаданные группы:
shellS> ndb_restore -c slave_host:port -n node-id \
-b backup-id -m -r dir
dir это
путь к каталогу, куда резервные файлы были помещены в ведомом репликации.
Для
ndb_restore
соответствующих остающимся резервным файлам, опция
-m
НЕ используется./var/BACKUPS/BACKUP-1,
надлежащая последовательность команд, которые будут выполнены на ведомом,
могла бы быть похожей на это:
shellS> ndb_restore -c rep-slave:1186 -n 2 -b 1 -m \
-r ./var/BACKUPS/BACKUP-1
shellS> ndb_restore -c rep-slave:1186 -n 3 -b 1 \
-r ./var/BACKUPS/BACKUP-1
shellS> ndb_restore -c rep-slave:1186 -n 4 -b 1 \
-r ./var/BACKUPS/BACKUP-1
shellS> ndb_restore -c rep-slave:1186 -n 5 -b 1 -e \
-r ./var/BACKUPS/BACKUP-1
-e (или
--restore-epoch) в заключительном вызове
ndb_restore
в этом примере требуется, чтобы эпоха была написана ведомому
mysql.ndb_apply_status.
Без этой информации ведомый не будет в состоянии синхронизироваться
правильно с ведущим (см.
главу 6.24
).ndb_apply_status на ведомом (как обсуждено в
главе 8.8):
mysqlS> SELECT @latest:=MAX(epoch) FROM mysql.ndb_apply_status;
@latest как
значение эпохи в предыдущем шаге, можно получить правильную стартовую позицию
@pos в правильном файле двоичного журнала
@file из таблицы
mysql.ndb_binlog_index ведущего,
используя запрос, показанный здесь:
mysqlM> SELECT @file:=SUBSTRING_INDEX(File, '/', -1), @pos:=Position
FROM mysql.ndb_binlog_index WHERE epoch >= @latest
ORDER BY epoch ASC LIMIT 1;
SHOW MASTER STATUS
на ведущем и используя значения в столбце
Position
для файла, у имени которого есть суффикс с самым большим значением
для всех файлов, показанных в столбце File.
Однако, в этом случае необходимо определить это и поставлять его в следующем
шаге вручную или разбирая вывод скриптом.CHANGE MASTER TO
в клиенте mysql на ведомом:
mysqlS> CHANGE MASTER TO MASTER_LOG_FILE='@file', MASTER_LOG_POS=@pos;
mysql
S> START SLAVE;
8.9.1. NDB Cluster Replication: автоматизация синхронизации ведомого
репликации с основной двоичной регистрацией
reset-slave.pl
служит примером того, как можно сделать это.
#!/user/bin/perl -w
#file: reset-slave.pl
#Copyright б╘2005 MySQL AB
#This program is free software; you can redistribute it and/or modify
#it under the terms of the GNU General Public License as published by
#the Free Software Foundation; either version 2 of the License, or
#(at your option) any later version.
#This program is distributed in the hope that it will be useful,
#but WITHOUT ANY WARRANTY; without even the implied warranty of
#MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.See the
#GNU General Public License for more details.
#You should have received a copy of the GNU General Public License
#along with this program; if not, write to:
#Free Software Foundation, Inc.
#59 Temple Place, Suite 330
#Boston, MA 02111-1307 USA
#
#Version 1.1
######################## Includes ###############################
use DBI;
######################## Globals ################################
my$m_host='';
my$m_port='';
my$m_user='';
my$m_pass='';
my$s_host='';
my$s_port='';
my$s_user='';
my$s_pass='';
my$dbhM='';
my$dbhS='';
####################### Sub Prototypes ##########################
sub CollectCommandPromptInfo;
sub ConnectToDatabases;
sub DisconnectFromDatabases;
sub GetSlaveEpoch;
sub GetMasterInfo;
sub UpdateSlave;
######################## Program Main ###########################
CollectCommandPromptInfo;
ConnectToDatabases;
GetSlaveEpoch;
GetMasterInfo;
UpdateSlave;
DisconnectFromDatabases;
################## Collect Command Prompt Info ##################
sub CollectCommandPromptInfo
{
### Check that user has supplied correct number of command line args
die "Usage:\n
reset-slave >master MySQL host< >master MySQL port< \n
>master user< >master pass< >slave MySQL host< \n
>slave MySQL port< >slave user< >slave pass< \n
All 8 arguments must be passed. Use BLANK for NULL passwords\n"
unless @ARGV == 8;
$m_host=$ARGV[0];
$m_port=$ARGV[1];
$m_user=$ARGV[2];
$m_pass=$ARGV[3];
$s_host=$ARGV[4];
$s_port=$ARGV[5];
$s_user=$ARGV[6];
$s_pass=$ARGV[7];
if ($m_pass eq "BLANK") { $m_pass = '';}
if ($s_pass eq "BLANK") { $s_pass = '';}
}
###############Make connections to both databases #############
sub ConnectToDatabases
{
### Connect to both master and slave cluster databases
### Connect to master
$dbhM = DBI->connect("dbi:mysql:database=mysql;host=$m_host;port=$m_port",
"$m_user", "$m_pass")
or die "Can't connect to Master Cluster MySQL process!
Error: $DBI::errstr\n";
### Connect to slave
$dbhS = DBI->connect("dbi:mysql:database=mysql;host=$s_host",
"$s_user", "$s_pass")
or die "Can't connect to Slave Cluster MySQL process!
Error: $DBI::errstr\n";
}
################Disconnect from both databases ################
sub DisconnectFromDatabases
{
### Disconnect from master
$dbhM->disconnect
or warn " Disconnection failed: $DBI::errstr\n";
### Disconnect from slave
$dbhS->disconnect
or warn " Disconnection failed: $DBI::errstr\n";
}
######################Find the last good GCI ##################
sub GetSlaveEpoch
{
$sth = $dbhS->prepare("SELECT MAX(epoch) FROM mysql.ndb_apply_status;")
or die "Error while preparing to select epoch from slave: ",
$dbhS->errstr;
$sth->execute
or die "Selecting epoch from slave error: ", $sth->errstr;
$sth->bind_col (1, \$epoch);
$sth->fetch;
print "\tSlave Epoch =$epoch\n";
$sth->finish;
}
#######Find the position of the last GCI in the binary log ########
sub GetMasterInfo
{
$sth = $dbhM->prepare("SELECT SUBSTRING_INDEX(File, '/', -1), Position
FROM mysql.ndb_binlog_index
WHERE epoch > $epoch
ORDER BY epoch ASC LIMIT 1;")
or die "Prepare to select from master error: ", $dbhM->errstr;
$sth->execute
or die "Selecting from master error: ", $sth->errstr;
$sth->bind_col (1, \$binlog);
$sth->bind_col (2, \$binpos);
$sth->fetch;
print "\tMaster binary log =$binlog\n";
print "\tMaster binary log position =$binpos\n";
$sth->finish;
}
##########Set the slave to process from that location #########
sub UpdateSlave
{
$sth = $dbhS->prepare("CHANGE MASTER TO MASTER_LOG_FILE='$binlog',
MASTER_LOG_POS=$binpos;")
or die "Prepare to CHANGE MASTER error: ", $dbhS->errstr;
$sth->execute
or die "CHANGE MASTER on slave error: ", $sth->errstr;
$sth->finish;
print "\tSlave has been updated. You may now start the slave.\n";
}
# end reset-slave.pl
8.9.2. Восстановление момента времени, используя
NDB Cluster Replication
NDB
(сделанную через
CREATE BACKUP в клиенте
ndb_mgm) и восстановление
таблицы ndb_binlog_index (из дампа
изготовленного mysqldump).NDB в кластере,
используя
START BACKUP в клиенте
ndb_mgm (см.
главу 7.3).mysql.ndb_binlog_index.
Вероятно, самое простое использовать для этого
mysqldump.
Также зарезервируйте файлы двоичного журнала в это время.
--initial или
ndbmtd
--initial).--initial.
Необходимо удалить их вручную.DROP TABLE или
TRUNCATE TABLE для таблицы
mysql.ndb_binlog_index.
--restore-epoch при выполнении
ndb_restore,
чтобы таблица ndb_apply_status
наполнялась правильно. См.
главу 6.24
.ndb_binlog_index
от вывода mysqldump
и файлы двоичного журнала из резервной копии при необходимости.epoch таблицы
ndb_apply_status
как пользовательская переменная
@LATEST_EPOCH:
SELECT @LATEST_EPOCH:=MAX(epoch)
FROM mysql.ndb_apply_status;
@FIRST_FILE) и позицию
(значение столбца Position)
в этом файле, которые соответствуют
@LATEST_EPOCH в таблице
ndb_binlog_index:
SELECT Position, @FIRST_FILE:=File FROM mysql.ndb_binlog_index
WHERE epoch > @LATEST_EPOCH
ORDER BY epoch ASC LIMIT 1;
8.10. NDB Cluster Replication: несколько ведущих и кольцевая репликация
log_slave_updates.
log_slave_updates.
Этот тип кольцевой схемы репликации NDB Cluster,
в которой линия репликации (снова обозначена кривыми стрелками на диаграмме)
прерывиста, должен быть возможным, но нужно отметить, что это полностью еще
не проверили и поэтому нужно все еще считать экспериментальным.BACKUP)
на одном NDB Cluster, чтобы создать резервную копию и затем применить эту
резервную копию на другом NDB Cluster через
ndb_restore.
Однако, это автоматически не создает двоичной журнал узла SQL второго
NDB Cluster, действующего как ведомый репликации. Чтобы заставить двоичные
регистрации быть созданными, вы должны выполнить
SHOW TABLES на
этом узле SQL, это должно быть сделано до выполнения
START SLAVE.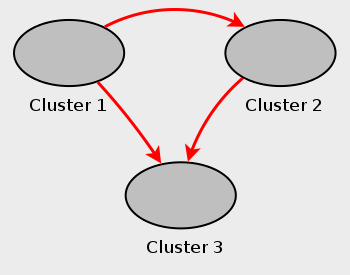
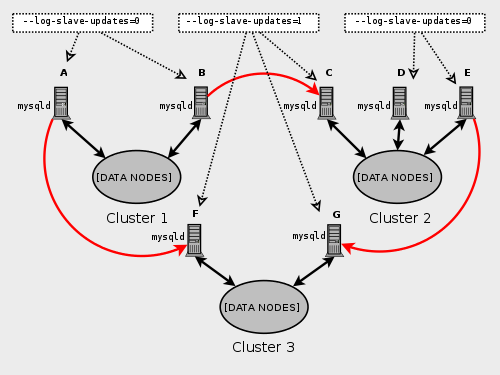
log_slave_updates.
Какие процессы mysqld
требуют эту опцию, также показано на предыдущей диаграмме.log_slave_updates не имеет
никакого эффекта на серверы, не управляемые как ведомые репликации.
mysqlC> SELECT @latest:=MAX(epoch) FROM mysql.ndb_apply_status
WHERE server_id=1;
mysqlC> SELECT @file:=SUBSTRING_INDEX(File, '/', -1), @pos:=Position
FROM mysql.ndb_binlog_index WHERE orig_epoch >= @latest
AND orig_server_id = 1 ORDER BY epoch ASC LIMIT 1;
ndb_binlog_index, см.
главу 8.4.@file и
@pos
вручную от сервера C к серверу F. Затем на сервере F выполните следующий
запрос CHANGE MASTER TO:
mysqlF> CHANGE MASTER TO MASTER_HOST = 'serverC'
MASTER_LOG_FILE='@file', MASTER_LOG_POS=@pos;
START SLAVE на MySQL-сервере
F и любые недостающие обновления, происходящие из сервера B, будут
копироваться к серверу F.CHANGE MASTER TO
также поддерживает опцию IGNORE_SERVER_IDS,
которая берет список разделенных запятой значений ID сервера и заставляет
события, происходящие из соответствующих серверов, быть проигнорированными.
Для получения дополнительной информации посмотрите
CHANGE MASTER TO Statement и
SHOW SLAVE STATUS Statement.
Для получения информации о том, как это работает с переменной
ndb_log_apply_status см.
главу 8.8.
8.11. Разрешение конфликтов NDB Cluster Replication
NDB$OLD(),
NDB$MAX(),
NDB$MAX_DELETE_WIN())
осуществляет эту определенную пользователями колонку как колонку
timestamp (хотя ее тип не может быть
TIMESTAMP,
как объяснено позже в этой секции). Эти типы разрешения конфликтов
всегда применяются на основании строки рядом, а не транзакций.
Основанные на эпохе функции разрешения конфликтов
NDB$EPOCH() и
NDB$EPOCH_TRANS() сравнивают порядок, в котором
эпохи копируются (и таким образом эти функции транзакционные). Различные
методы могут использоваться, чтобы сравнить значения столбцов резолюции на
ведомом, когда конфликты происходят, как объяснено позже в этой секции,
используемый метод может быть установлен на основе таблицы.--ndb-log-updated-only
или на табличной основе записями в таблице
mysql.ndb_replication
(см.
The ndb_replication system table).TEXT или
BLOB),
--ndb-log-updated-only
может также быть полезно для сокращения размера двоичного журнала
ведущего и ведомого и предотвращения возможных неудач репликации
из-за превышения
max_allowed_packet.mysql.ndb_replication на табличной основе
(см.
The ndb_replication system table).ndb_log_exclusive_reads = 1
на ведомом. Все строки, прочитанные конфликтом, регистрируются в таблице
исключений. Для получения дополнительной информации посмотрите
здесь.NDB$OLD(),
NDB$MAX() и
NDB$MAX_DELETE_WIN()
для основанного на метке времени разрешения конфликтов, мы часто обращаемся к
колонке, используемой для определения обновлений как к колонке
timestamp.
Однако, тип данных этой колонки никогда не
TIMESTAMP,
вместо этого ее тип данных должен быть
INT
(INTEGER) или
BIGINT. Столбец
timestamp должен также быть
UNSIGNED и
NOT NULL.NDB$EPOCH() и
NDB$EPOCH_TRANS(), обсужденные позже в этой
секции, работают, сравнивая относительный порядок
эпох репликации, примененных на основном и вторичном
NDB Cluster, и не используют метки времени.--ndb-log-update-as-write
для mysqld,
как описано позже в этой секции.Регистрация полных или частичных строк
(опция --ndb-log-updated-only)
Свойство Значение
Формат командной строки
--ndb-log-updated-only[={OFF|ON}]Системная
ndb_log_updated_onlyОбласть действия
Global Динамическая
Да Тип
Boolean Значение по умолчанию
ON--ndb-log-updated-only для
mysqld:--ndb-log-updated-only =
0 или OFF.
Опция --ndb-log-update-as-write:
регистрация измененных данных как обновления
Свойство Значение
Формат командной строки
--ndb-log-update-as-write[={OFF|ON}]Системная
ndb_log_update_as_writeОбласть действия
Global Динамическая
Да Тип
Boolean Значение по умолчанию
ON--ndb-log-update-as-write
определяет, выполняется ли регистрация с или без образа
до. Поскольку разрешение конфликтов сделано в
обработчике обновления MySQL Server, необходимо управлять журналированием
ведущего, таким образом, что обновления это обновления, а не записи.
То есть, обновления рассматривают как изменения в существующих строках, а не
запись новых строк (даже при том, что они заменяют существующие строки).
Этот выбор включен по умолчанию, другими словами, обновления рассматривают
как записи. Таким образом, обновления по умолчанию написаны как события
write_row в журнале вместо события
update_row.--ndb-log-update-as-write=0 или
--ndb-log-update-as-write=OFF.
Необходимо сделать это, копируя от таблиц NDB до таблиц, используя
другой механизм хранения, посмотрите
здесь и
здесь для получения дополнительной информации.mysql.ndb_replication.ndb_replication в системной БД
mysql на ведущем, ведомом или на обоих, в
зависимости от типа разрешения конфликтов и метода, который будет
использоваться. Эта таблица используется, чтобы управлять функциями
регистрации и разрешения конфликтов на основе таблицы и имеет одну
строку на таблицу, вовлеченную в репликацию.
ndb_replication
создана и заполнена управляющей информацией о сервере, где конфликт должен
быть решен. В простой установке "главный-подчиненный", где данные
могут также быть изменены в местном масштабе на ведомом, это, как правило,
будет ведомым. В более сложной схеме репликации (с 2 каналами) это обычно
будет всеми ведущими. Каждая строка в
mysql.ndb_replication
соответствует копируемой таблице и определяет, как зарегистрировать и решить
конфликты (то есть, которую функцию разрешения конфликтов, если таковые
имеются, использовать) для той таблицы. Определение таблицы
mysql.ndb_replication:
CREATE TABLE mysql.ndb_replication(db VARBINARY(63), table_name VARBINARY(63),
server_id INT UNSIGNED,
binlog_type INT UNSIGNED,
conflict_fn VARBINARY(128),
PRIMARY KEY USING HASH (db, table_name,
server_id)) ENGINE=NDB
PARTITION BY KEY(db,table_name);
_ и % как часть
имени базы данных. Соответствие подобно тому, что
осуществляется для оператора
LIKE._ и %.
Соответствие подобно тому, что осуществляется для оператора
LIKE.
Значение Внутреннее значение
Описание 0
NBT_DEFAULTИспользуйте умолчание сервера 1
NBT_NO_LOGGINGНе регистрируйте эту таблицу в двоичной регистрации 2
NBT_UPDATED_ONLYТолько обновленные признаки зарегистрированы 3
NBT_FULLЗарегистрируйте полную строку, даже если не обновлено
(поведение сервера MySQL по умолчанию) 4
NBT_USE_UPDATEТолько для генерации значений
NBT_UPDATED_ONLY_USE_UPDATE и
NBT_FULL_USE_UPDATE,
не предназначено для отдельного использования5
[Not used]
--- 6
NBT_UPDATED_ONLY_USE_UPDATE
(=NBT_UPDATED_ONLY | NBT_USE_UPDATE)Используйте обновленные признаки, даже если значения неизменны 7
NBT_FULL_USE_UPDATE
(=NBT_FULL | NBT_USE_UPDATE)Используйте полные строки, даже если значения неизменны
NULL:
Указывает, что разрешение конфликтов не должно использоваться
для соответствующей таблицы.column_name
то же самое на ведущем и на ведомом, тогда обновление применяется, иначе
обновление не применяется на ведомого, и исключение написано регистрации.
Это иллюстрировано следующим псевдокодом:
if (
master_old_column_value ==
slave_current_column_value)
apply_update();
else log_exception();
if (
master_new_column_value >
slave_current_column_value)
apply_update();
NDB$MAX().
Вследствие того, что никакая метка времени недоступна для операции удаления,
удаление использует NDB$MAX()
на самом деле обрабатывая как NDB$OLD.
Однако, для некоторых вариантов использования это неоптимально. Для
NDB$MAX_DELETE_WIN(), если значение столбца
timestamp для данного добавления или обновления
существующей строки, прибывающей от ведущего, выше, чем это на ведомом, это
применяется. Однако, операции удаления рассматриваются как всегда имеющий
более высокое значение. Это иллюстрировано в следующем псевдокоде:
if ((
master_new_column_value >
slave_current_column_value)
|| operation.type == "delete")
apply_update();
NDB$MAX(), значение столбца от ведущего
образа после это
значение, используемое этой функцией.NDB$EPOCH()
отслеживает порядок, в котором копируемые эпохи применяются на ведомом NDB
Cluster относительно изменений, происходящих на ведомом. Этот относительный
порядок используется, чтобы определить, параллельны ли изменения,
происходящие на ведомом, с какими-либо изменениями, которые происходят в
местном масштабе и поэтому находятся потенциально в конфликте.NDB$EPOCH() также относится к
NDB$EPOCH_TRANS().
Любые исключения отмечены в тексте.NDB$EPOCH()
асимметрична, воздействует на один NDB Cluster
в кольцевой конфигурации репликации с двумя группами (иногда называемой
репликацией active-active).
Мы здесь называем кластер, на котором это действует, как первичный, а
другой как вторичный. Ведомый на первичном ответственен за обнаружение и
обработку конфликтов в то время, как ведомый на вторичном не вовлечен ни в
какое обнаружение или обработку конфликта.NDB$EPOCH_TRANS()
это переходное состояние, для NDB$EPOCH()
это может быть постоянное состояние.NDB$EPOCH() и
NDB$EPOCH_TRANS()
не требуют, чтобы любые пользовательские модификации схемы или изменения
приложений обеспечили обнаружение конфликта. Однако, осторожное внимание
должно быть уделено используемым схемам доступа, чтобы проверить, что полная
система ведет себя в указанных пределах.NDB$EPOCH() и
NDB$EPOCH_TRANS()
может взять дополнительный параметр. Это число битов, чтобы использовать,
чтобы представлять более низкие 32 бита эпохи и должно быть установлено
не меньше, чем в:
CEIL(LOG2(
TimeBetweenGlobalCheckpoints /
TimeBetweenEpochs), 1)
TimeBetweenGlobalCheckpoints,
TimeBetweenEpochs или вместе.
Значение, которое является слишком маленьким, может привести к ложным
положительным срабатываниям, в то время как то, которое является слишком
большим, может привести к чрезмерному потраченному впустую
пространству в базе данных.NDB$EPOCH() и
NDB$EPOCH_TRANS() вставляют записи
для противоречивых строк в соответствующие таблицы исключений при условии,
что эти таблицы были определены согласно тем же самым правилам схемы таблицы
исключений, как описано в другом месте в этой секции (см.
NDB$OLD(column_name)).
Необходимо составить любую таблицу исключений прежде, чем составить таблицу,
с которой она должна использоваться.NDB$EPOCH() и
NDB$EPOCH_TRANS(),
активируются включением соответствующих записей в таблицу
mysql.ndb_replication
(см. здесь).
Роли основных и вторичных NDB Cluster в этом сценарии полностью определяются
записями таблицы mysql.ndb_replication.NDB$EPOCH() и
NDB$EPOCH_TRANS(),
асимметричны, необходимо использовать различные значения для вторичного
ведомого и основного ведомого server_id.DELETE
недостаточен, чтобы вызвать использование конфликта
NDB$EPOCH() или
NDB$EPOCH_TRANS(), и относительное размещение в
пределах эпохи не имеет значения (Bug #18459944).NDB$EPOCH(),
так как этот ведомый был в последний раз перезапущен от текущего значения
переменной состояния системы
Ndb_conflict_fn_epoch.Ndb_conflict_fn_epoch_trans
обеспечивает количество строк, которые были найдены непосредственно в
конфликте NDB$EPOCH_TRANS().
Ndb_conflict_fn_epoch2 и
Ndb_conflict_fn_epoch2_trans
показывают количество строк, найденных в конфликте
NDB$EPOCH2() и
NDB$EPOCH2_TRANS(), соответственно.
Количество строк, на самом деле перестроенных, включая затронутые из-за их
членства или в зависимости от тех же самых транзакций
как другие противоречивые строки, дает
Ndb_conflict_trans_row_reject_count.NDB$EPOCH(), чтобы
выполнить обнаружение конфликта:TimeBetweenEpochs
(умолчание: 100 миллисекунд). Минимальное окно конфликта это минимальное
время, в течение которого параллельные обновления тех же самых данных по
обеим группам всегда сообщают о конфликте. Это всегда отрезок времени
отличный от нуля и примерно пропорциональный
2 * (latency+queueing+TimeBetweenEpochs).
Это подразумевает, что принятие умолчания для
TimeBetweenEpochs и игнорируя любое время
ожидания между группами (а также любые стоящие в очереди задержки)
минимальный размер окна конфликта приблизительно 200 миллисекунд.
Это минимальное окно нужно рассмотреть, смотря на ожидаемые прикладные
образцы шаблонов race.NDB$EPOCH() и
NDB$EPOCH_TRANS(): от 1 до 32
бит дополнительного пространства на строку требуется, в зависимости от
значения, переданного функции.NDB$EPOCH() или
NDB$EPOCH_TRANS()
для обнаружения конфликта.BLOB или
TEXT
в настоящее время не поддерживаются с
NDB$EPOCH() или
NDB$EPOCH_TRANS().NDB$EPOCH_TRANS() расширяет функцию
NDB$EPOCH(). Конфликты обнаружены и обработаны
таким же образом, используя правило primary wins
all (см.
NDB$EPOCH() и NDB$EPOCH_TRANS()), но с дополнительным условием, что любые
другие строки, обновленные в той же самой транзакции, в которой произошел
конфликт, также расцениваются как конфликтные. Другими словами, где
NDB$EPOCH()
перестраивает отдельные противоречивые строки на вторичном,
NDB$EPOCH_TRANS()
перестраивает противоречивые транзакции.NDB$EPOCH_TRANS()
подчиняется тем же самым условиям и ограничениям, как
NDB$EPOCH(), а кроме того требует, чтобы
использовались события строки двоичного журнала Version 2
(log_bin_use_v1_row_events=0),
что добавляет издержки хранения в 2 байта на событие в двоичной регистрации.
Кроме того, все ID транзакции должны быть зарегистрированы в двоичной
регистрации на вторичном
(опция
--ndb-log-transaction-id),
что добавляет переменные издержки (до 13 байтов на строку).
Ndb_conflict_fn_max предоставляет количество
раз, которые строка не была применена на текущем узле SQL из-за
разрешения конфликтов greatest timestamp wins
с прошлого раза, когда был запущен
mysqld.Ndb_conflict_fn_old.
В дополнение к увеличению
Ndb_conflict_fn_old,
первичный ключ строки, который не использовался, вставляется в
таблицу исключений,
как объяснено позже в этой секции.NDB$EPOCH2() подобна
NDB$EPOCH() за исключением того, что
NDB$EPOCH2() предусматривает
обработку удалений с кольцевой репликацией
(master-master).
В этом сценарии основные и вторичные роли назначены на этих
двух ведущих, установив системную переменную
ndb_slave_conflict_role к соответствующему значению на каждом
ведущем (обычно каждый из PRIMARY,
SECONDARY).
Когда это сделано, модификации, сделанные вторичным, отражены первичным назад
к вторичному, который тогда условно применяет их.NDB$EPOCH2_TRANS() расширяет
NDB$EPOCH2(). Конфликты обнаружены и обработаны
таким же образом, и назначение основных и вторичных ролей кластерам
репликации аналогично, но с дополнительным условием, что любые другие строки,
обновленные в той же самой транзакции, в которой произошел конфликт, также
расцениваются как конфликтные. Таким образом,
NDB$EPOCH2()
перестраивает отдельные противоречивые строки на вторичном, в то время как
NDB$EPOCH_TRANS()
перестраивает противоречивые транзакции.NDB$EPOCH() и
NDB$EPOCH_TRANS()
используют метаданные, которые определяются на строку, в прошлую измененную
эпоху, чтобы определить на первичном параллельно ли поступающее копируемое
изменение строки от вторичного с переданным локально изменением,
параллельные изменения рассматриваются как конфликт с
обновлениями таблицы исключений и перестройкой вторичного.
Проблема возникает, когда строка удалена на первичном,
таким образом, больше нет никакой измененной в последний раз эпохи,
доступной, чтобы определить, находятся ли какие-либо копируемые операции в
противоречии, что означает, что конфликт операции удаления не обнаружен.
Это может привести к расхождению, например, удалению на одном кластере,
которое параллельна с удалением и вставкой на другом,
поэтому операция удаления может быть направлена только к одному кластеру,
используя NDB$EPOCH() и
NDB$EPOCH_TRANS().NDB$EPOCH2()
обходит проблему просто описывая хранимую информацию об удаленных строках на
PRIMARY, игнорируя любой конфликт delete-delete и избегая любого
потенциального проистекающего расхождения также. Это достигается, отражая
любую успешно примененную операцию на вторичном назад на вторичного.
По возвращению на вторичный это может использоваться, чтобы повторно
использовать операцию на вторичном, которая была удалена
операцией, происходящей из перыичного.NDB$EPOCH2()
необходимо иметь в виду, что вторичное удаление из первичного, удаляет новую
строку, пока это не восстановлено отраженной операцией.
В теории последующая вставка или обновление на вторичном конфликтует с
удалением из первичного, но в этом случае, мы принимаем решение
проигнорировать это и позволить вторичному
победить,
в интересах предотвращения расхождения между группами. Другими словами, после
удаления первичный не обнаруживает конфликт, и вместо этого вторичный
принимает изменения немедленно. Из-за этого состояние вторичного
может пересмотреть многократные предыдущие переданные состояния в то время,
как оно прогрессирует до заключительного (стабильного) статуса
и некоторые из них могут быть видимы.Ndb_conflict_reflected_op_prepare_count и
Ndb_conflict_reflected_op_discard_count.
Количество примененных изменений является просто различием между этими двумя
значениями (отметьте, что
Ndb_conflict_reflected_op_prepare_count
всегда больше или равно
Ndb_conflict_reflected_op_discard_count).NDB$OLD(), также необходимо составить таблицу
исключений, соответствующую каждой таблице
NDB,
для которой должен использоваться этот тип разрешения конфликтов.
Это также верно, используя NDB$EPOCH() или
NDB$EPOCH_TRANS().
Название этой таблицы это название таблицы, для которой разрешение конфликтов
должно быть применено, с добавленной последовательностью
$EX. Например, если название оригинальной
таблицы mytable, название соответствующего имени
в таблице исключений должно быть mytable$EX.
Синтаксис для того, чтобы составить таблицу исключений:
CREATE TABLE
original_table$EX(
[NDB$]server_id INT UNSIGNED, [NDB$]master_server_id INT UNSIGNED,
[NDB$]master_epoch BIGINT UNSIGNED, [NDB$]count INT UNSIGNED,
[NDB$OP_TYPE ENUM('WRITE_ROW','UPDATE_ROW', 'DELETE_ROW',
'REFRESH_ROW', 'READ_ROW') NOT NULL,]
[NDB$CFT_CAUSE ENUM('ROW_DOES_NOT_EXIST', 'ROW_ALREADY_EXISTS',
'DATA_IN_CONFLICT', 'TRANS_IN_CONFLICT') NOT NULL,]
[NDB$ORIG_TRANSID BIGINT UNSIGNED NOT NULL,]
original_table_pk_columns,
[orig_table_column|
orig_table_column$OLD|
orig_table_column$NEW,]
[additional_columns,]
PRIMARY KEY([NDB$]server_id, [NDB$]master_server_id,
[NDB$]master_epoch, [NDB$]count)) ENGINE=NDB;
server_id,
master_server_id,
master_epoch и
count,
и что вы используете те же самые имена как в оригинальной таблице для
колонок, соответствующих им в первичном ключе оригинальной таблицы.NDB$OP_TYPE,
NDB$CFT_CAUSE или
NDB$ORIG_TRANSID,
тогда каждую из необходимых колонок нужно также назвать, используя префикс
NDB$. При желании можно использовать префикс
NDB$, чтобы назвать необходимые колонки, даже
если вы не определяете дополнительных колонок, но в этом случае все четыре
необходимые колонки нужно назвать, используя префикс.NDB.
Пример, который использует NDB$OLD()
с таблицей исключений, показывают позже в этой секции.NOT NULL. NDB Cluster
поддерживает три дополнительных предопределенных дополнительных колонки
NDB$OP_TYPE,
NDB$CFT_CAUSE и
NDB$ORIG_TRANSID.NDB$OP_TYPE:
Эта колонка может использоваться, чтобы получить тип операции, вызывающей
конфликт. При использовании эту колонку определяете, как показано здесь:
NDB$OP_TYPE ENUM('WRITE_ROW', 'UPDATE_ROW', 'DELETE_ROW',
'REFRESH_ROW', 'READ_ROW') NOT NULL
WRITE_ROW,
UPDATE_ROW и
DELETE_ROW
представляют начатые пользователями операции.
REFRESH_ROW это
операции, произведенные разрешением конфликтов в компенсации транзакциям,
переданные обратно от кластера, который обнаружил конфликт. Операции
READ_ROW начинаются пользователями как
прочитанные операции по отслеживанию, определенные с
исключительными блокировками строки.NDB$CFT_CAUSE:
Можно определить дополнительную колонку
NDB$CFT_CAUSE,
которая обеспечивает причину зарегистрированного конфликта.
Эта колонка, если используется, определяется как показано здесь:
NDB$CFT_CAUSE ENUM('ROW_DOES_NOT_EXIST', 'ROW_ALREADY_EXISTS',
'DATA_IN_CONFLICT', 'TRANS_IN_CONFLICT') NOT NULL
ROW_DOES_NOT_EXIST
может быть сообщен как причина для операций
UPDATE_ROW и
WRITE_ROW,
ROW_ALREADY_EXISTS может быть сообщен для
событий WRITE_ROW.
DATA_IN_CONFLICT
сообщается, когда основанная на строке функция конфликта обнаруживает
конфликт. TRANS_IN_CONFLICT
сообщается, когда транзакционная функция конфликта отклоняет все операции,
принадлежащие завершенной транзакции.NDB$ORIG_TRANSID: Столбец
NDB$ORIG_TRANSID,
если используется, содержит ID происходящей транзакции.
Эта колонка должна быть определена следующим образом:
NDB$ORIG_TRANSID BIGINT UNSIGNED NOT NULL
NDB$ORIG_TRANSID это 64-bit
значение, произведенное NDB.
Это значение может использоваться, чтобы коррелировать многократные записи
таблицы исключений, принадлежащие той же самой противоречивой транзакции от
тех же самых или различных таблиц исключений.colname
$OLDcolname
$NEWcolname
$OLDDELETE_ROW.
colname
$NEWWRITE_ROW,
UPDATE_ROW или обоих этих типов.
Где противоречивая операция не поставляет значение для данной справочной
колонки непервичного ключа, строка таблицы исключений содержит также
NULL или определенное значение по умолчанию
для той колонки.mysql.ndb_replication
прочитан, когда таблица данных настраивается для репликации, таким образом,
строка, соответствующая таблице, которая будет копироваться, должна быть
вставлена в mysql.ndb_replication
до того, как
таблица, которая будет копироваться, составлена.Примеры
test.t1,
с использованием колонки mycol как
timestamp.
Это может быть сделано, используя следующие шаги:--ndb-log-update-as-write=OFF.INSERT:
INSERT INTO mysql.ndb_replication
VALUES ('test', 't1', 0, NULL, 'NDB$MAX(mycol)');
server_id
указывает, что все узлы SQL, получающие доступ к этой таблице, должны
использовать разрешение конфликтов. Если вы хотите использовать разрешение
конфликтов только на определенном
mysqld,
используйте фактический ID сервер.NULL в столбец
binlog_type имеет тот же самый эффект как
вставка 0 (NBT_DEFAULT),
умолчание сервера используется.test.t1:
CREATE TABLE test.t1 (columns mycol INT UNSIGNED, columns) ENGINE=NDB;
mycol,
написана ведомому.binlog_type, например,
NBT_UPDATED_ONLY_USE_UPDATE,
должны использоваться, чтобы управлять журналированием ведущего,
использующего таблицу ndb_replication, а не при
помощи параметров командной строки.NDB,
такая как определенная здесь, копируется, и вы хотите позволить
разрешение конфликтов same timestamp wins
для обновлений этой таблицы:
CREATE TABLE test.t2(a INT UNSIGNED NOT NULL, b CHAR(25) NOT NULL,
columns,
mycol INT UNSIGNED NOT NULL,
columns,
PRIMARY KEY pk (a, b)) ENGINE=NDB;
test.t2 необходимо вставить строку в
mysql.ndb_replication:
INSERT INTO mysql.ndb_replication
VALUES ('test', 't2', 0, NULL, 'NDB$OLD(mycol)');
binlog_type
показывают ранее в этой секции. Значение
'NDB$OLD(mycol)' должно быть вставлено в столбец
conflict_fn.test.t2.
Запрос создания таблицы, показанный здесь, включает все необходимые колонки,
любые дополнительные колонки должны быть объявлены после этих колонок, но
перед определением первичного ключа таблицы.
CREATE TABLE test.t2$EX(server_id INT UNSIGNED,
master_server_id INT UNSIGNED,
master_epoch BIGINT UNSIGNED, count INT UNSIGNED,
a INT UNSIGNED NOT NULL, b CHAR(25) NOT NULL,
[
additional_columns,]
PRIMARY KEY(server_id, master_server_id,
master_epoch, count)) ENGINE=NDB;
CREATE TABLE test.t2$EX(NDB$server_id INT UNSIGNED,
NDB$master_server_id INT UNSIGNED,
NDB$master_epoch BIGINT UNSIGNED,
NDB$count INT UNSIGNED, a INT UNSIGNED NOT NULL,
NDB$OP_TYPE ENUM('WRITE_ROW','UPDATE_ROW',
'DELETE_ROW', 'REFRESH_ROW', 'READ_ROW') NOT NULL,
NDB$CFT_CAUSE ENUM('ROW_DOES_NOT_EXIST',
'ROW_ALREADY_EXISTS', 'DATA_IN_CONFLICT',
'TRANS_IN_CONFLICT') NOT NULL,
NDB$ORIG_TRANSID BIGINT UNSIGNED NOT NULL,
[
additional_columns,]
PRIMARY KEY(NDB$server_id, NDB$master_server_id,
NDB$master_epoch, NDB$count)) ENGINE=NDB;
NDB$
требуется для четырех необходимых колонок, так как мы включали по крайней
мере одну из колонок NDB$OP_TYPE,
NDB$CFT_CAUSE или
NDB$ORIG_TRANSID в определение таблицы.test.t2
как показано ранее.NDB$OLD().
Для каждой такой таблицы должна быть соответствующая строка в
mysql.ndb_replication
и должна быть таблица исключений в той же самой базе данных,
где копируемая таблица.employee и
department, чтобы смоделировать сценарий, в
который сотрудник перемещен от одного отдела в другой на основном кластере
(к которому мы обращаемся как к A)
в то время, как ведомый кластер (B)
обновляет количество сотрудников бывшего отдела
сотрудника в чередованной транзакции.
# Employee table
CREATE TABLE employee (id INT PRIMARY KEY, name VARCHAR(2000),
dept INT NOT NULL) ENGINE=NDB;
# Department table
CREATE TABLE department (id INT PRIMARY KEY, name VARCHAR(2000),
members INT) ENGINE=NDB;
SELECT:
mysql> SELECT id, name, dept FROM employee;
+------+------+------+
| id | name | dept |
+------+------+------+
...
| 998 |Mike | 3 |
| 999 |Joe | 3 |
| 1000 |Mary | 3 |
...
+------+--------+----+
mysql> SELECT id, name, members FROM department;
+----+-------------+---------+
| id | name | members |
+----+-------------+---------+
...
| 3 | Old project | 24 |
...
+----+-------------+---------+
CREATE TABLE employee$EX(NDB$server_id INT UNSIGNED,
NDB$master_server_id INT UNSIGNED,
NDB$master_epoch BIGINT UNSIGNED,
NDB$count INT UNSIGNED,
NDB$OP_TYPE ENUM('WRITE_ROW','UPDATE_ROW',
'DELETE_ROW', 'REFRESH_ROW','READ_ROW') NOT NULL,
NDB$CFT_CAUSE ENUM('ROW_DOES_NOT_EXIST',
'ROW_ALREADY_EXISTS', 'DATA_IN_CONFLICT',
'TRANS_IN_CONFLICT') NOT NULL, id INT NOT NULL,
PRIMARY KEY(NDB$server_id, NDB$master_server_id,
NDB$master_epoch, NDB$count)) ENGINE=NDB;
BEGIN;
INSERT INTO department VALUES (4, "New project", 1);
UPDATE employee SET dept = 4 WHERE id = 999;
COMMIT;
employee:
BEGIN;
SELECT name FROM employee WHERE id = 999;
UPDATE department SET members = members-1 WHERE id = 3;
commit;
SELECT)
и операцией по обновлению. Можно обойти эту проблему, выполнив
SET
ndb_log_exclusive_reads=1 на ведомом.
Приобретение исключительных блокировок чтения таким образом заставляет любые
строки, прочитанные на ведущем отметиться как нуждающиеся в разрешении
конфликтов на ведомом. Если мы позволяем исключительное чтение
таким образом до регистрации этих транзакций, чтение на кластере
B прослежено и послано на кластер
A для резолюции: конфликт на строке
сотрудника будет обнаружен, и транзакция на кластере
B прервется.READ_ROW
(см.
здесь для описания операционных типов), как показано здесь:
mysql> SELECT id, NDB$OP_TYPE, NDB$CFT_CAUSE FROM employee$EX;
+-----+-------------+-------------------+
| id | NDB$OP_TYPE | NDB$CFT_CAUSE |
+-----+-------------+-------------------+
...
| 999 | READ_ROW | TRANS_IN_CONFLICT |
+-----+-------------+-------------------+
BEGIN;
INSERT INTO department VALUES (4, "New project", 0);
UPDATE employee SET dept = 4 WHERE dept = 3;
SELECT COUNT(*) INTO @count FROM employee WHERE dept = 4;
UPDATE department SET members = @count WHERE id = 4;
COMMIT;
SET ndb_log_exclusive_reads = 1;# Must be set if not already enabled
...
BEGIN;
SELECT COUNT(*) INTO @count FROM employee WHERE dept = 3 FOR UPDATE;
UPDATE department SET members = @count WHERE id = 3;
COMMIT;
WHERE во второй транзакции
SELECT, прочитаны и таким образом
отмечаются в таблице исключений, как показано здесь:
mysql> SELECT id, NDB$OP_TYPE, NDB$CFT_CAUSE FROM employee$EX;
+------+-------------+-------------------+
| id | NDB$OP_TYPE | NDB$CFT_CAUSE |
+------+-------------+-------------------+
...
| 998 | READ_ROW | TRANS_IN_CONFLICT |
| 999 | READ_ROW | TRANS_IN_CONFLICT |
| 1000 | READ_ROW | TRANS_IN_CONFLICT |
...
+------+-------------+-------------------+
| Найди своих коллег! |
Вы можете
направить письмо администратору этой странички, Алексею Паутову.
![]()