|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
|
|
|
|
|
|
| WebMoney: WMZ Z294115950220 WMR R409981405661 WME E134003968233 |
Visa 4274 3200 2453 6495 |
NDB Cluster
технология, которая позволяет кластеризовать базы данных в памяти.
Эта архитектура позволяет системе работать с очень недорогими аппаратными
средствами, и с минимумом определенных требований для аппаратных средств
или программного обеспечения. NDB Cluster разработан, чтобы не иметь единственную точку сбоя. У каждого
компонента, как ожидают, будут своя собственная память и диск, использование
механизмов совместно используемой памяти, таких как сетевые ресурсы, сетевые
файловые системы и SAN не рекомендуется или поддерживается. NDB Cluster объединяет стандартный сервер MySQL с механизмом
кластерной системы хранения в памяти
NDB Cluster состоит из ряда компьютеров, известных как
хосты, каждый управляет одним или более
процессами. Эти процессы, известные как
узлы,
могут включать серверы MySQL (для доступа к данным NDB), узлы данных (для
хранения данных), один или несколько серверов управления и возможно другие
специализированные программы доступа к данным. Отношения этих компонентов в
NDB Cluster показывают здесь: Рис. 3.1. Компоненты NDB Cluster Все эти программы сотрудничают, чтобы сформировать NDB Cluster (см.
главу 6. Когда данные хранятся в механизме
Хотя в NDB Cluster узел SQL использует
mysqld, он отличается по многим
критическим отношениям от
mysqld в MySQL 5.7, эти две
версии mysqld
не взаимозаменяемые. Кроме того, сервер MySQL, который не связан с NDB Cluster, не может
использовать механизм Данные в узлах данных для NDB Cluster
могут быть отражены, группа может обращаться с неудачами отдельных узлов
данных без другого воздействия, небольшое количество транзакций прерывается
из-за потери операционного состояния. Поскольку транзакционные приложения,
как ожидают, будут обращаться со сбоем транзакции, это не должно
быть источником проблем. Отдельные узлы могут быть остановлены и перезапущены и могут тогда
воссоединиться с системой. Катящийся перезапуск (в котором все узлы
перезапущены в свою очередь) используется в создании изменений конфигурации и
обновлений программного обеспечения (см.
раздел 7.5).
Катящиеся перезапуски также используются в качестве части процесса добавления
новых узлов данных онлайн (см.
раздел 7.15).
Для получения дополнительной информации об узлах данных, как они организованы
в NDB Cluster, и как они обращаются и хранят данные NDB Cluster см.
раздел 3.2. Поддержка и восстановление баз данных NDB Cluster могут быть сделаны,
используя функциональность Узлы NDB Cluster могут использовать различные транспортные механизмы для
коммуникаций междоузлия, TCP/IP по стандарту, 100 Мбит/с или более быстрые
аппаратные средства Ethernet, используется в большей
части реального развертывания. Механизм Кластерная часть NDB Cluster
формируется независимо от серверов MySQL. В NDB Cluster каждая
часть считается узлом. Во многих контекстах термин узел
используется, чтобы указать на компьютер, но обсуждая NDB Cluster
это означает процесс.
Возможно управлять многократными узлами на одиночном компьютере,
для компьютера, на котором управляют одним или большим количеством узлов
кластера, мы используем термин
хост кластера. Есть три типа узлов, в минимальной конфигурации NDB будет по крайней мере
три узла, один из каждого из этих типов: Узел управления:
роль этого типа узла должна управлять другими узлами в NDB Cluster,
выполняя такие функции как обеспечение данных конфигурации, старт и остановка
узлов и управление резервными копиями. Поскольку этот тип узла управляет
конфигурацией других узлов, узел этого типа должен быть начат сначала перед
любым другим узлом. Узел MGM начат командой
ndb_mgmd. Узел данных:
Этот тип узла хранит данные. Есть столько же узлов данных, сколько есть
точных копий, помноженных на количество фрагментов (см.
раздел 3.2).
Например, с двумя точными копиями, каждая с двумя фрагментами, вам нужны
четыре узла данных. Одна точная копия достаточна для хранения данных, но не
обеспечивает избыточности, поэтому, рекомендуется иметь 2 (или больше) точных
копии, чтобы обеспечить избыточность и таким образом высокую доступность.
Узел данных начат командой
ndbd (см.
раздел 6.1) или
ndbmtd (см.
раздел 6.3). Таблицы NDB Cluster обычно хранятся полностью в памяти, а не на диске.
Однако некоторые данные NDB Cluster могут храниться на диске, см.
раздел 7.13. Узел SQL:
Это узел, который получает доступ к данным. В случае NDB Cluster
узел SQL традиционный сервер MySQL, который использует механизм
Узел SQL на самом деле просто специализированный тип
узла API,
который определяет любое применение, которому доступны данные NDB Cluster.
Другой пример узла API это утилита
ndb_restore, которая
используется, чтобы восстановить резервную копию.
Возможно написать такие запросы, используя API NDB. Для основной информации
о API NDB посмотрите
здесь. Нереалистично ожидать использовать установку с тремя узлами в
производственной среде. Такая конфигурация не обеспечивает избыточности,
чтобы извлечь выгоду из высоконадежных особенностей NDB Cluster, необходимо
использовать многократные узлы SQL и данных. Использование многократных узлов
управления также настоятельно рекомендовано. Для краткого введения в отношения между узлами, группами узлов, точными
копиями и разделами в NDB Cluster см.
раздел 3.2. Конфигурация группы вовлекает формирование каждого отдельного узла и
соединений между ними. NDB Cluster в настоящее время разрабатывается с
намерением, что узлы данных гомогенные с точки зрения питания процессора,
пространства памяти и пропускной способности. Кроме того, чтобы обеспечить
единственный пункт конфигурации, все данные конфигурации для группы в целом
расположены в одном конфигурационном файле. Сервер управления управляет файлом кластерной конфигурации и
журналом кластера. Каждый узел в группе получает данные конфигурации от
сервера управления, это требует способ определить, где искать сервер
управления. Когда интересные события имеют место в узлах данных, узлы
передают информацию об этих событиях серверу управления, который
пишет информацию в журнал. Кроме того, может быть любое количество клиентских процессов.
Они включают типичных клиентов MySQL, программы
Типичные клиенты MySQL. NDB Cluster может использоваться с
существующими приложениями MySQL, написанными на PHP, Perl, C, C++, Java,
Python, Ruby и т.д. Такие клиентские приложения посылают SQL-операторы и
получают ответы от серверов MySQL, действующих как узлы SQL в NDB Cluster
почти таким же способом, которым они взаимодействуют с
автономными серверами MySQL. Клиенты MySQL, использующие NDB Cluster в качестве источника данных, могут
быть изменены, чтобы использовать в своих интересах способность соединиться с
многими серверами MySQL, чтобы достигнуть выравнивания нагрузки и
отказоустойчивости. Например, клиенты Java через Connector/J 5.0.6 и позже
могут использовать URL
Программы клиента NDB. Программы клиента могут быть написаны
для доступа к NDB Cluster непосредственно из механизма хранения
NDB Cluster также поддерживает приложения, написанные на JavaScript с
Node.js. MySQL Connector для JavaScript включает адаптеры для прямого доступа
к Memcache API для NDB Cluster работает как загружаемый механизм хранения
ndbmemcache для memcached версии 1.6 и позже,
может использоваться, чтобы обеспечить постоянному хранилищу данных NDB
Cluster доступ к использованию протокола кэш-памяти. Стандартное кэширование memcached
включено в NDB Cluster 7.5. Ккаждый сервер
memcached
имеет прямой доступ к данным в NDB Cluster,
но также в состоянии обратиться к данным кэша в местном масштабе. См. ndbmemcache Memcache API for NDB Cluster. Клиенты управления. Эти клиенты соединяются с сервером управления и
обеспечивают команды для старта и остановки узлов, старта и остановки
отслеживания сообщения (только отладочные версии), показ версий узла и
статуса, старта и остановки резервных копий и так далее. Пример этого типа
программы:
ndb_mgm (см.
раздел 6.5).
Такие запросы могут быть написаны, используя
MGM API, C-подобный API
который общается непосредственно с одним или более серверами управления
NDB Cluster. См. The MGM API. Oracle также делает доступным MySQL Cluster Manager,
который обеспечивает современный интерфейс командной строки, упрощающий
многие сложные задачи управления NDB Cluster, например, перезапуск NDB
Cluster с большим количеством узлов. Клиент MySQL Cluster Manager
также поддерживает команды для того, чтобы получить и установить значения
большинства параметров конфигурации узла, а также опции и переменные сервера
mysqld, связанные с
NDB Cluster. См.
MySQL Cluster Manager 1.4.8 User Manual. Журналы событий. NDB Cluster регистрирует события по категориям
(запуск, закрытие, ошибки, контрольные точки и так далее), приоритету и
серьезности. Полный список всех заслуживающих публикации событий может быть
найден в
разделе 7.6. Журналы событий имеют эти два типа: Cluster log:
Ведет учет всех желаемых заслуживающих публикации событий
для группы в целом. Node log:
отдельная регистрация, которая также сохранена для
каждого отдельного узла. При нормальных обстоятельствах необходимо и достаточно держать и
исследовать только регистрацию группы. Регистрации узла нужны
только в целях разработки приложений и отладки. Контрольная точка. Вообще говоря, когда данные сохраняются на диск,
сказано, что контрольная точка
была достигнута. Более определенно для NDB Cluster,
контрольная точка это момент времени, где все переданные транзакции сохранены
на диске. Относительно Local Checkpoint (LCP):
Это контрольная точка, которая является определенной для единственного узла,
однако, LCP происходят для всех узлов в группе более или менее одновременно.
LCP обычно происходит каждые несколько минут, точный интервал варьируется и
зависит от объема данных, сохраненного узлом,
уровня деятельности группы и других факторов. До NDB 7.6.4 LCP включала сохранение на диск всех данных узла. NDB 7.6.4
вводит поддержку частичной LCP, что может значительно улучшить время
восстановления при некоторых условиях. Посмотрите
раздел 3.4.2,
а также описания параметров конфигурации
Global Checkpoint (GCP):
GCP происходит каждые несколько секунд, когда транзакции для всех узлов
синхронизированы, а журнал отката сбрасывается на диск. Для получения дополнительной информации о файлах и каталогах, созданных
местными контрольными точками и глобальными контрольными точками, см.
NDB Cluster Data Node File System Directory Files. Эта секция обсуждает способ, которым NDB Cluster
делит и дублирует данные для хранения. Много понятий, важных в понимании этой темы, обсуждены в
следующих нескольких параграфах. Узел данных.
Процесс
ndbd или
ndbmtd, который хранит одну или более
точных копий то есть, копии
разделов,
назначенных на группу узлов, членом которой является узел. Каждый узел данных должен быть расположен на отдельном компьютере. В то
время как также возможно запустить многократные процессы узла данных на
одном компьютере, такая конфигурация обычно не рекомендуется. Терминам узел и
узел данных
свойственно использоваться попеременно, относясь к процессам
ndbd или
ndbmtd, где упомянуто, узлам управления
(процесс
ndb_mgmd) и
узлам SQL (процесс mysqld). Группа узла.
Группа узла состоит из одного или более узлов и хранит разделение или наборы
точных копий. Количество групп узла в NDB Cluster не конфигурируемо непосредственно,
это функция количества узлов данных и количества точных копий
(параметр конфигурации
Таким образом у NDB Cluster с 4 узлами данных есть 4 группы узла, если
У всех групп узлов в NDB Cluster
должно быть то же самое количество узлов данных. Можно добавить новые группы узлов
(и таким образом новые узлы данных) онлайн к работающему NDB Cluster, см.
раздел 7.15. Разделы.
Это часть данных. Каждый узел ответственен за хранение по крайней мере одной
копии любого разделения, назначенного на него (то есть, по крайней мере
одной точной копии). Количество разделов, используемых по умолчанию NDB Cluster,
зависит от количества узлов данных и количества потоков
LDM, задействованных узлами: Используя узлы данных, работающие с
ndbmtd, число потоков LDM
управляется
NDB и определенное пользователями разделение. NDB Cluster
обычно разделяет таблицы
Только схемы Максимальное количество разделов, которое может быть определено явно
для любой таблицы См. раздел 6.3.
Для получения дополнительной информации о NDB Cluster
и определенного пользователями разделения посмотрите разделы
3.7 и
Partitioning Limitations Relating to Storage Engines. Точная копия.
Это копия разделения группы. Каждый узел в группе узлов хранит точную копию.
Также иногда известно как
точная копия разделения.
Количество точных копий равно количеству узлов на группу узлов. Точная копия принадлежит полностью единственному узлу, узел может (и
обычно так и делает) хранить несколько точных копий. Следующая диаграмма иллюстрирует NDB Cluster с четырьмя узлами данных,
работающими с
ndbd,
в двух группах из двух узлов каждая,
узлы 1 и 2 принадлежат группе узлов 0, а узлы 3 и 4 принадлежат группе 1. Только узлы данных показывают здесь, хотя работа NDB Cluster
требует процесса
ndb_mgmd
для управления и по крайней мере одного узла SQL для доступа к данным,
они были опущены на рисунке для ясности. Рис. 3.2. NDB Cluster с двумя группами узлов Данные, хранившие группой, разделены на четыре раздела,
пронумерованных 0, 1, 2 и 3. Каждый раздел сохранен в многочисленных копиях
в той же самой группе узлов. Разделение сохранено в дополнительных группах
узлов следующим образом: Раздел 0 сохранен в группе 0,
основная точная копия (основная копия)
сохранена на узле 1, резервная точная копия
(резервная копия раздела) сохранена на узле 2. Раздел 1 сохранен в другой группе узлов (группа 1),
основная точная копия этого разделения находится на узле 3,
его резервная точная копия находится на узле 4. Раздел 2 сохранен в группе узлов 0.
Однако размещение его двух точных копий полностью иное: основная точная копия
сохранена на узле 2, резервная копия на узле 1. Раздел 3 сохранен в группе узлов 1,
размещение его двух точных копий полностью отлично от раздела 1.
Таким образом, его основная точная копия расположена на узле 4 с
резервной копией на узле 3. Вот что это означает относительно длительной работы NDB Cluster:
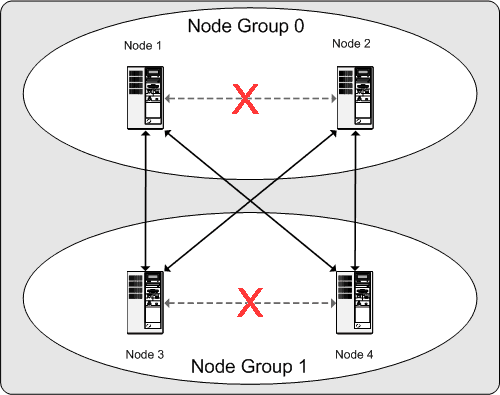
пока у каждой группы узлов есть по крайней мере один рабочий узел,
группа имеет полную копию всех данных и остается жизнеспособной.
Это иллюстрировано на следующей диаграмме. Рис. 3.3. Узлы, необходимые для 2x2 группы NDB Cluster В этом примере кластер состоит из двух групп узлов, каждая
из двух узлов данных. Каждый узел данных управляет
ndbd.
Любая комбинация из по крайней мере одного узла группы 0 и по крайней мере
одного узла группы 1 достаточна, чтобы поддержать кластер.
Однако, если оба узла от единственной группы узлов
терпят неудачу, комбинация, состоящая из
двух узлов в другой группе узла, недостаточна.
В этой ситуации кластер потерял все разделение и больше не может обеспечивать
доступ к полному набору всех данных. В NDB 7.5.4 и позже максимальное количество групп узлов для единственного
экземпляра NDB Cluster = 48 (Bug#80845, Bug #22996305). Одно из преимуществ NDB Cluster: им
можно управлять на потребительском оборудовании и не имеется никаких
необычных требований в этом отношении, кроме больших объемов RAM, вследствие
того, что все живое хранение данных сделано в памяти.
Возможно уменьшить это требование, используя таблицы Disk Data, см
раздел 7.13.
Естественно, многократные и более быстрые CPU могут увеличить
производительность. Требования к памяти для других процессов NDB
Cluster относительно небольшие. Требования к программному обеспечению для NDB Cluster
также скромны. Хостовые операционные системы не требуют, чтобы любые
необычные модули, сервисы, запросы или конфигурация поддерживали NDB Cluster.
Для поддержанных операционных систем стандартная установка должна быть
достаточной. Требования к программному обеспечению MySQL просты: все, что
необходимо, является производственным выпуском NDB Cluster.
Не строго необходимо собрать MySQL самостоятельно просто, чтобы быть
в состоянии использовать NDB Cluster.
Мы предполагаем, что вы используете двоичные модули, соответствующие вашей
платформе, доступные из программного обеспечения NDB Cluster со страницы
https://dev.mysql.com/downloads/cluster/. Для связи между узлами NDB Cluster поддерживает TCP/IP
поддерживает TCP/IP, общающийся через Интернет в любой стандартной топологии,
и минимум, ожидаемый для каждого хоста,
является стандартной картой Ethernet на 100 Мбит/с плюс роутер, свитч или
хаб, чтобы обеспечить сетевое соединение для группы в целом.
Мы сильно рекомендуем, чтобы NDB Cluster работал в
собственной подсети, которая не разделена с машинами, не являющимися
частью группы по следующим причинам: Безопасность. Связи между узлами не зашифрованы.
Единственное средство защиты передач состоит в том, чтобы управлять вашим NDB
Cluster в защищенной сети. Если вы намереваетесь использовать NDB
Cluster для Web, кластер должен определенно находиться позади вашего
брандмауэра, а не в De-Militarized Zone
(DMZ) или в другом месте. См.
раздел 7.12.1. Эффективность.
NDB Cluster в частной или защищенной сети позволяет
сделать исключительное использование пропускной способности между
хостами группы. Использование отдельного коммутатора для NDB Cluster
не только помогает защититься от несанкционированного доступа к данным,
это также гарантирует, что узлы ограждены от вмешательства, вызванного
передачами между другими компьютерами в сети. Для расширенной надежности
можно использовать двойные коммутаторы и двойные карты, чтобы удалить
сеть как единственный пункт сбоя,
много драйверов устройств поддерживают отказоустойчивость для
таких линий связи.
Сетевая коммуникация и время ожидания. NDB Cluster требует связи между
узлами данных и узлами API (включая узлы SQL), а также между узлами данных и
другими узлами данных, чтобы выполнить запросы и обновления. Коммуникационное
время ожидания между этими процессами может непосредственно затронуть
наблюдаемую работу и время ожидания пользовательских запросов. Кроме того,
чтобы поддержать последовательность и обслуживание несмотря на тихую неудачу
узлов, NDB Cluster использует механизмы тайм-аута, которые рассматривают
расширенную потерю сообщения узла как сбой узла. Это может привести к
уменьшенной избыточности. Вспомните, что, чтобы поддержать непротиворечивость
данных, NDB Cluster закрывается, когда последний узел в группе узлов
терпит неудачу. Таким образом, чтобы избежать увеличения риска
принудительного закрытия, перерывов в связи между узлами нужно избегать
по мере возможности. Неудача узла данных или API приводит к аварийному прекращению работы всех
нейтральных транзакций, включающих неудавшийся узел.
Восстановление узла данных требует синхронизации данных неудавшегося узла из
выживающего узла данных, и восстановление находящихся на диске журналов
контрольной точки, прежде чем узел данных возвратится к работе.
Это восстановление может занять время, во время которого кластер
работает с уменьшенной избыточностью. Синхронизация полагается на своевременную генерацию
сигналов всеми узлами. Это может не быть возможно, если узел перегружен,
имеет недостаточной мощный CPU из-за разделения с другими программами или
испытывает задержки из-за обмена. Если генерация достаточно задержана, другие
узлы рассматривают узел, который не спешит отвечать, как сбойный. Эта обработка медленного узла может не быть желательной при некоторых
обстоятельствах, в зависимости от воздействия замедленного действия узла на
кластер. Устанавливая значения тайм-аута
Где коммуникационные времена ожидания между узлами данных, как ожидают,
будут выше, чем ожидалось бы в окружающей среде LAN (примерно 100 мкс),
параметры перерыва должны быть увеличены, чтобы гарантировать, что любые
позволенные периоды ожидания укладываются в настройки.
Увеличение перерывов таким образом имеет соответствующий эффект на время
худшего случая, чтобы обнаружить сбой. Окружающая среда LAN может, как правило, формироваться со стабильным
низким временем ожидания и таким образом,
может предоставить избыточность и быструю отказоустойчивость.
Отдельные неудачи связи могут быть восстановлены с минимальным временем
ожидания на уровне TCP (где NDB Cluster нормально работает).
Окружающая среда WAN может предложить диапазон времен ожидания, а также
избыточность с более медленными временами отказоустойчивости.
Отдельные неудачи связи могут потребовать, чтобы изменения маршрута
размножились, прежде чем непрерывная возможность соединения будет
восстановлена. На уровне TCP это может проявиться как большие времена
ожидания на отдельных каналах. Худший случай времени ожидания TCP в этих
сценариях связан со временем худшего случая для слоя IP,
чтобы изменить маршрут. Следующие разделы описывают изменения в
NDB Cluster в MySQL NDB Cluster 7.6 5.7.29-ndb-7.6.13 и в NDB Cluster 7.5
5.7.29-ndb-7.5.17 по сравнению с более ранним рядом выпусков. NDB Cluster 8.0
доступен как General Availability (GA), начиная с NDB 8.0.19, см.
What is New in NDB Cluster. NDB Cluster 7.6 и 7.5
являются предыдущими GA releases, они все еще поддержанные в производстве,
для получения информации о NDB Cluster 7.6 см.
раздел 3.4.2.
Для подобной информации о NDB Cluster 7.5 см.
раздел 3.4.1.
NDB Cluster 7.4 и 7.3 являются предыдущими GA releases, они все еще
поддержанные в производстве, хотя мы рекомендуем, чтобы новое развертывание
для производства использовало NDB Cluster 8.0, см.
MySQL NDB Cluster 7.3 and NDB Cluster 7.4. NDB Cluster 7.2
является прошлой серией GA release, которая больше не поддерживается для
нового развертывания, пользователи NDB 7.2 должны модернизировать систему до
более поздней версии. Для получения дополнительной информации о NDB Cluster
7.2 см. MySQL NDB Cluster 7.2. Существенные изменения и новые особенности в NDB Cluster 7.5, которые,
вероятно, будут представлять интерес, показывают в следующем списке: Улучшения ndbinfo. Много изменений внесены в базу данных
Таблица
Строка в таблице
Используя эти отношения, можно написать соединение на этих двух таблицах,
чтобы получить умолчание, максимум, минимум и текущее значение для одного или
более параметров кластерной конфигурации NDB по имени. SQL-оператор в
качестве примера, используя такое соединение показывают здесь: См. разделы
7.10.8 и
раздел 7.10.9. Кроме того, база данных Несколько новых таблиц в
См. описания отдельных таблиц для
получения дополнительной информации. Строка по умолчанию и изменения формата столбца.
Начиная с NDB 7.5.1, значения по умолчанию для обоих опций
Формат строки и формат столбца, используемый существующими столбцами
таблицы, не затронуты этим изменением. Новые колонки, добавленные к таким
таблицам, используют новые умолчания для них (возможно отвергнуть
Копирование ndb_binlog_index больше не связан с MyISAM.
С NDB 7.5.2 таблица Выгода этого изменения: оно позволяет зависеть от транзакционного
поведения и без блокировок читает таблицы, что может помочь облегчить
проблемы параллелизма во время операций по чистке и ротации
регистрации, а также улучшить доступность этой таблицы. Новое в ALTER TABLE. NDB Cluster раньше поддерживал
альтернативный синтаксис для онлайн
Другое изменение, затрагивающее использование этого запроса,
в том, что Устарел параметр ExecuteOnComputer.
Параметр Оптимизация records-per-key.
Обработчик NDB теперь использует интерфейс records-per-key
для статистики индекса, осуществленной для оптимизатора в MySQL
5.7.5. Некоторые преимущества от этого изменения включают: Оптимизатор теперь выбирает лучшие планы выполнения во многих
случаях, где менее оптимальный индекс соединения или порядок
соединения таблицы были бы ранее выбраны. Оценки строки, показанные
Оценки количества элементов, показанные
Пул связей узлов.
NDB 7.5.0 добавляет опцию mysqld
Можно установить размер пула связи, используя опцию
Удалено create_old_temporals. Системная переменная
Команда PROMPT в клиенте ndb_mgm. NDB Cluster 7.5
добавляет новую команду для урегулирования приглашения командной строки
клиента. Следующий пример иллюстрирует использование команды
См.
раздел 7.2. Увеличенное хранение колонки FIXED на фрагмент.
NDB Cluster 7.5 и позже поддерживает максимум 128 TB на фрагмент данных в
столбце Убраны устаревшие параметры.
Следующие параметры конфигурации узла данных NDB Cluster
устарели в предыдущих выпусках NDB Cluster и удалены в NDB 7.5.0: Архаичный и неиспользуемый (поэтому также ранее недокументированный)
параметр конфигурации компьютера Эти параметры не поддерживаются в NDB 7.5. Попытка использовать любой из
этих параметров в файле кластерной конфигурации NDB
теперь приводит к ошибке. Улучшения сканирования DBTC.
Просмотры были улучшены, сократив количество сигналов, используемых для связи
между ядерными блоками Также, поскольку результат этого времени отклика должен быть значительно
улучшен, это может помочь предотвратить проблемы с перегрузкой главных
потоков. Кроме того, просмотры, сделанные в ядерном блоке
Поддержка столбцов JSON.
NDB 7.5.2 и позже понимает тип столбцов
Чтение от любой точной копии,
определите количество hashmap фрагментов раздела.
Ранее все чтения были направлены к основной точной копии, за исключением
простого чтения. Простым является чтение, которое захватывает
строку, читая ее. Начиная с NDB 7.5.2, возможно позволить чтение от любой
точной копии. Это отключено по умолчанию, но может быть позволено для данного
узла SQL, используя системную переменную
Ранее было возможно определить таблицы только с одним типом отображения
разделения с одним основным разделом на каждом LDM в каждом узле, но в
NDB 7.5.2 становится возможно быть более гибким в назначении разделения,
устанавливая баланс разделения (тип количества фрагментов).
Возможные схемы баланса: один на узел, один на группу узлов, один на LDM на
узел и один на LDM на группу узлов. Этим урегулированием можно управлять для отдельных таблиц посредством
опции В приложениях NDB API баланс разделения таблицы может также быть
получен и задан соответствующими методами, см.
Table::getPartitionBalance() и
Table::setPartitionBalance(), а также
Object::PartitionBalance. Как часть этой работы, NDB 7.5.2 также вводит системную переменную
Кроме того, при восстановлении схем таблицы,
ndb_restore
NDB 7.5.3 добавляет дальнейшее улучшение к
Улучшения ThreadConfig.
Много улучшений и дополнений осуществляются в NDB 7.5.2 для
Неисключительный захват CPU теперь поддерживается на FreeBSD и
Windows, используя Приоритетизация потока теперь доступна, управляется новым параметром
Параметр Разделение больше 16 ГБ.
Из-за улучшения внедрения индекса хэша, используемого узлами данных,
разделения таблиц Печать SQL-операторов от ndb_restore.
NDB 7.5.4 добавляет опцию
См.
раздел 6.24. Организация пакетов RPM.
С NDB 7.5.4 обозначение и организация пакетов RPM NDB Cluster
выравнивают более тесно с выпущенными для сервера MySQL. Названия всех
NDB Cluster RPM теперь имеют префикс
Для подробного списка NDB Cluster RPM и другой информации посмотрите
раздел 4.3.2. Таблицы ndbinfo processes и config_nodes.
NDB 7.5.7 добавляет две таблицы к информационной база данных
The
Имя системы.
Имя системы кластера NDB может использоваться, чтобы определить определенный
кластер. Начиная с NDB 7.5.7, MySQL Server показывает это имя как значение
переменной статуса
Имя системы дается на основе времени, когда сервер управления был начат.
Можно отвергнуть это значение, добавив раздел
Опции ndb_restore. С NDB 7.5.13 опции
Изменения в ndb_blob_tool. С NDB 7.5.18, the
ndb_blob_tool
может обнаружить недостающие части blob, для которых действующие части
существуют и заменяют их частями заполнителя (состоящего из пробелов)
правильной длины. Чтобы проверить наличие частей используйте опцию
См. раздел 6.6
. NDB Cluster 7.5 также поддерживается MySQL Cluster Manager,
который обеспечивает современный интерфейс командной строки, который может
упростить многие сложные задачи управления NDB Cluster. См.
MySQL Cluster Manager 1.4.8 User Manual. Новые особенности и другие важные изменения в NDB Cluster 7.6, которые,
вероятно, будут представлять интерес, показывают в следующем списке: Новый формат файла таблиц Disk Data.
Новый формат файла был введен в NDB 7.6.2 для таблиц NDB Disk Data,
который позволяет каждой таблице быть однозначно определенной, не используя
снова ID таблицы. Формат был улучшен далее в NDB 7.6.4.
Это должно помочь решить вопросы со страницей и обработкой экстента, которые
были видимы пользователю как проблемы с быстрым созданием и удалением таблиц
Disk Data, для которых старый формат не обеспечил готовое средство. Новый формат теперь используется каждый раз, когда новый файл журнала
отмен и файлы данных табличного пространства создаются. Файлы, касающиеся
существующих таблиц, продолжают использовать старый формат, пока их табличные
пространства и группы файла журнала отмен не воссоздаются. Старые и новые форматы несовместимы,
различные файлы данных или журнала отмен, которые используются той же самой
таблицей, или табличное пространство не могут
использовать соединение форматов. Чтобы избежать проблем, касающихся изменений в формате, необходимо
воссоздать любые существующие табличные пространства и группы журнала отмен,
модернизируя до NDB 7.6.2 или NDB 7.6.4. Можно сделать это, выполнив
начальный перезапуск каждого узла данных (то есть, используя
При использовании таблицы Disk Data переход от
любого выпуска NDB 7.6
безотносительно к какому статусу выпуска NDB 7.5 или ранее
требует, чтобы вы перезапустили все узлы данных с опцией
См.
раздел 4.9. Объединение памяти данных и динамическая память индекса.
Память, требуемая для индексов на столбцах таблицы
Начиная с NDB 7.6.2, если Кроме того, значение по умолчанию для
Объединение вместе памяти индекса с памятью данных упрощает конфигурацию
Как часть этой работы, много экземпляров
Поэтому может быть необходимо на некоторых системах увеличить
Кроме того, узлы данных теперь производят события
Другие связанные изменения перечисляются здесь: Таблица
ndbinfo и таблица config_nodes.
NDB 7.6.2 добавляет две таблицы к информационной база данных
Имя системы. Имя системы NDB cluster
может использоваться, чтобы определить кластер. Начиная с NDB 7.6.2, MySQL
Server показывает это имя как значение переменной статуса
Имя системы произведено автоматически на основе времени, когда сервер
управления был запущен, можно отвергнуть это значение, добавив раздел
Улучшенный инсталлятор GUI.
NDB Cluster Auto-Installer был изменен во многих отношениях, как
описано в следующем списке: Инсталлятор теперь обеспечивает постоянное хранение в
зашифрованном файле Установщик теперь использует безопасные связи (HTTPS) по умолчанию
между клиентом браузера и бэкендом веб-сервера. Библиотека безопасности Paramiko, использовавшаяся инсталлятором, была
модернизирована до версии 2. Другие улучшения функциональности установщика
SSH включают способность использовать пароли для зашифрованных закрытых
ключей и использовать различные параметры
авторизации с различными хостами. Поиск информации о хосте
был улучшен, и инсталлятор теперь предоставляет точные значения
для суммы дискового пространства, доступного на хостах. Конфигурация была улучшена с большинством параметров узла, теперь
доступных для урегулирования в GUI. Кроме того, параметрам, чьи разрешенные
значения перечислены, показали те значения
для выбора, устанавливая их. Также теперь возможно переключить
показ продвинутых параметров конфигурации на глобальной основе или на узел.
См. раздел 4.2. ndb_import CSV.
ndb_import,
добавлена в NDB Cluster 7.6.2, загружает CSV отформатированные данные
непосредственно в таблицу Предполагая, что база данных и целевая таблица
См. раздел 6.14
. ndb_top.
Добавлена утилита
ndb_top,
которая показывает загрузку ЦП и информацию об использовании для
узла данных
ndb_top
соединяется с узлом SQL в NDB Cluster (с MySQL Server).
Поэтому программа должна быть в состоянии соединиться как пользователь
MySQL, имеющий право
ndb_top
доступна для Linux, Solaris и macOS с NDB 7.6.3.
Это в настоящее время недоступно для платформ Windows. См. раздел 6.30
. Кодовая очистка. Значительное количество отладочных операторов,
не необходимых для нормального функционирования, было перемещено в код,
используемый только, проверяя или отлаживая
Поток LDM и улучшения LCP.
Ранее, когда местный поток управления данными испытывал
задержку I/O, он писал местные контрольные точки более медленно.
Это могло произойти, например, во время дисковой перегрузки.
Проблемы могли произойти, потому что другие потоки LDM не всегда наблюдали
это состояние или делали аналогично.
Ошибочная идентификация NDB.
Сообщения об ошибках и информация могут быть получены, используя клиент
mysql в NDB 7.6.4 и позже
из новой таблицы
Улучшения SPJ.
Выполняя просмотр как выдвинутое соединение (то есть, корень запроса
это просмотр), блок Теперь Эта работа, как ожидают, увеличит производительность
выдвинутых соединений по следующим причинам: Так как многократные корневые фрагменты
могут быть просмотрены для каждого запроса SPJ, необходимо запросить меньше
экземпляров SPJ, выполняя выдвинутое соединение. Увеличенное доступное пакетное распределение размера для каждого
фрагмента должно также в большинстве случаев привести к меньшему количеству
запросов, необходимых, чтобы закончить соединение. Улучшенная обработка O_DIRECT для журналов отката.
NDB 7.6.4 вводит новый параметр конфигурации узла данных
Необходимо принять во внимание, что урегулирование для этого параметра
проигнорировано, когда по крайней мере одно из следующих условий верно: Захват CPU потоком построения оффлайновых индексов.
В NDB 7.6.4 и позже поток построения оффлайновых индексов по умолчанию
использует все ядра, доступные
ndbmtd
вместо того, чтобы быть ограниченным одним ядром, зарезервированным для
потока I/O. Также становится возможно определить желаемый набор ядер, которые
будут использоваться для потоков I/O многопоточного построения
оффлайн индексов. Это может улучшить перезапуск, время и
производительность восстановления, а также доступность. Offline как используется здесь,
относится к построению индексу, который происходит в то время, как данная
таблица не пишется. Такой индекс создается во время узлового или системного
перезапуска или восстанавливая кластер из резервной копии, используя
ndb_restore
Это улучшение включает несколько связанных изменений.
Первое из них должно изменить значение по умолчанию для параметра
Как часть этой работы, NDB 7.6.4 также вводит параметр Переменные пакетные размеры для операций DDL по данным.
Как часть работы, продолжающейся, чтобы оптимизировать большую часть
работы DDL
ndbmtd,
теперь возможно получить повышения производительности, увеличивая пакетный
размер для оптовых частей данных операций DDL,
обрабатывающих данные, используя просмотры.
Пакетные размеры теперь сделаны конфигурируемыми для создания уникального
индекса, создания внешних ключей
и онлайн-перестройки, устанавливая соответствующие параметры конфигурации
узла данных, перечисленные здесь:
Для каждого из перечисленных параметров
значение по умолчанию равняется 64, минимум равняется 16, максимум 512. Увеличение соответствующего пакетного размера или размеров может помочь
уменьшить времена ожидания междоузлия и использовать больше параллельных
ресурсов, чтобы помочь масштабировать работу DDL. В каждом случае может быть
согласование с продолжающимся трафиком. Частичные LCP.
NDB 7.6.4 вводит частичные местные контрольные точки. Раньше LCP всегда делал
копию всей базы данных. Работая с терабайтами данных, этот процесс мог
потребовать большого количества времени с неблагоприятным воздействием на
узел и перезапуски кластера, а также больше пространства для журналов отката.
Теперь LCP по умолчанию сохраняет только много записей, которые основаны на
количестве данных, измененных начиная с предыдущего LCP.
Это может измениться между полной контрольной точкой и контрольной точкой,
которая не изменяет ничего вообще.
Если контрольная точка отражает любые изменения, как минимум надо написать
одну часть в 2048 байта, составив местный LCP. Как часть этого изменения, два новых параметра конфигурации узла данных
добавлены:
Необходимо отключить частичный LCP явно, установив
Значение по умолчанию для Кроме того, параметры конфигурации узла данных
Как часть этого улучшения, работа была сделана, чтобы исправить несколько
проблем с перезапусками узла, где
было возможно исчерпать журнал отмен
в различных ситуациях, чаще всего восстанавливая узел, который
долго был выключен в период интенсивных записей. Дополнительная работа была сделана, чтобы улучшить выживание узла данных
в длительные периоды синхронизации, обновив контрольный модуль
LCP во время этого процесса и отслеживая прогресс дисковой синхронизации
данных. Ранее, была возможность поддельных предупреждений или даже неудач
узла, если синхронизация заняла больше времени, чем защитный тайм-аут LCP. Модернизируя NDB Cluster, который использует дисковые таблицы данных для
NDB 7.6.4 или снижаясь от NDB 7.6.4 необходимо перезапустить все узлы
данных с
Параллельная обработка записей журнала отмены.
Раньше ядерный блок Количество записей журнала для каждого LDM в
Несколько типов записей продолжают обрабатываться последовательно:
Нет никаких видимых пользователем изменений в функциональности,
непосредственно связанной с этим исполнительным улучшением,
это часть работы, сделанной, чтобы улучшить длительную обработку журналов и
поддержку частичных местных контрольных точек в NDB Cluster 7.6.4. Чтение таблиц и ID фрагментов из экстента для журнала отмены.
Применяя журнал отмен, необходимо получить ID таблицы
и ID фрагмент со страницы ID. Это было сделано ранее, читая страницу
из ядерного блока Используя См. описание
Улучшения в NDB Cluster Auto-Installer.
В NDB 7.6.4 параметры конфигурации узла, их значения по умолчанию и их
документация в Auto-Installer были приведены в соответствие с NDB Cluster.
Поддержка SSH и конфигурация были также улучшены. Кроме того, HTTPS теперь
используется по умолчанию для веб-подключений и больше не используются
cookies как постоянный механизм хранения данных. Больше информации об этих и
других изменениях в Auto-Installer дано в следующих нескольких параграфах. Auto-Installer теперь осуществляет механизм для урегулирования параметров
конфигурации, которые берут дискретные значения. Например, параметр узла
данных Auto-Installer также теперь получает и показывает сумму дискового
пространства, доступного на хосте (как
Поддержка безопасного соединения в автоинсталляторе MySQL NDB Cluster
Auto-Installer была обновлена или улучшена в NDB Cluster 7.6.4: Добавлен механизм для урегулирования членства SSH
для каждого хоста. Обновлен модуль Paramiko Python до
последней доступной версии (2.6.1). Добавлено место в GUI для зашифрованных паролей с закрытым ключом и
прекращено использование жестко заданных паролей с
Другие улучшения, касающиеся безопасности данных, которые осуществляются в
NDB 7.6.4, включают следующее: Прекращено использование cookies для хранения информации
конфигурации NDB Cluster, они не были безопасны и шли с большим
верхним пределом хранения. Теперь автоустановщик использует зашифрованный
файл с этой целью. Чтобы обеспечить передачу данных между фронтэндом JavaScript в
веб-браузере пользователя и веб-сервером Python на бэкэнде, коммуникационный
протокол по умолчанию для этого был переключен от HTTP на HTTPS. См.
раздел 4.1. Транспортер общей памяти. Определенная пользователями общая
память (SHM) связи между узлом данных и узлом API на том же самом компьютере
поддерживается в NDB 7.6.6 и позже и больше не считается экспериментальной.
Можно позволить явное сопряжение с общей памятью, установив
Выполнение связей SHM может быть увеличено посредством установки
параметров
Параметр См.
раздел 5.3.12. Оптимизация внутреннего объединения в блоке SPJ.
В NDB 7.6.6 и позже ядерный блок Рассмотрите этот запрос соединения, где Ранее это привело бы к запросу Эта оптимизация не может быть применена, пока все узлы данных и все узлы
API в группе не были модернизированы до NDB 7.6.6 или позже. Пробуждение потоков NDB.
NDB 7.6.6 и более поздние поддерживают выгружаемые
потоком приемника задачи пробуждения других потоков к новому потоку, который
будит другие потоки по запросу (иначе просто спит),
позволяя улучшить производительность единственной связи примерно на
десять-двадцать процентов. Адаптивное управление LCP.
NDB 7.6.7 реализует адаптивный механизм управления LCP, который действует в
ответ на изменения в использовании пространства журнала отката.
Контролируя скорость записи на диск LCP, можно помочь защитить от многих
связанных с ресурсом проблем, включая следующее: Недостаточные ресурсы CPU для приложений. Дисковая перегрузка. Недостаточный буфер журнала отката. Условия остановки GCP. Недостаточное место журнала отката. Эта работа включает следующие изменения, касающиеся параметров
конфигурации Значение по умолчанию
Новый параметр конфигурации узла данных
Эта работа осуществляет контроль скорости LCP в основном, чтобы
минимизировать риск исчерпывания журнала отката. Это сделано адаптивным
способом, на основе суммы использованного пространства журнала отката,
используя аварийные уровни, с ответами, взятыми, когда
эти уровни достигнуты: Low:
использование пространства дурнала отката больше, чем на 25%, или оцененное
использование показывает недостаточное пространство журнала отката при очень
высокой скорости обработки транзакций.
В ответ использование буферов данных LCP увеличено во время просмотров LCP,
приоритет просмотров LCP увеличен, и объем данных, который может быть написан
за перерыв в реальном времени в просмотре LCP, также увеличен. High:
использование пространства журнала отката больше, чем 40%, ожидается
высокая вероятность исчерпать пространство журнала отката при высокой
скорости обработки транзакций. Когда этот уровень использования достигнут,
Critical:
использование пространства журнала отката больше 60%, или оцененное
использование показывает недостаточное пространство журнала отката при
нормальной скорости обработки транзакций. На этом уровне
Подъем уровня также имеет эффект увеличения расчетной целевой
скорости контрольной точки. Контроль LCP обладает следующими преимуществами для установки
Кластеры должны теперь пережить очень большие нагрузки,
используя конфигурации по умолчанию намного лучше, чем ранее. Должно теперь быть возможно для Опции ndb_restore.
С NDB 7.6.9
Восстановление частями.
С NDB 7.6.13 возможно разделить резервную копию на примерно равные части
и восстановить эти части в параллели, используя две новых опции,
осуществленные для
ndb_restore:
Это позволяет использовать многократные экземпляры
ndb_restore, чтобы
восстановить подмножества резервной копии параллельно, потенциально уменьшая
количество времени, требуемое, чтобы выполнить операцию восстановления. См. описания опций
ndb_restore и
Улучшения ndb_blob_tool.
С NDB 7.6.14
ndb_blob_tool
может обнаружить недостающие части blob, для которых действующие части
существуют и заменить их частями заполнителя (состоящих из пробелов)
правильной длины. Чтобы проверить, есть ли такие части, используйте опцию
См.
раздел 6.6. Этот раздел содержит информацию о параметрах конфигурации
Следующие параметры конфигурации узла были добавлены в NDB 7.5. Следующие параметры конфигурации узла устарели в NDB 7.5. Следующие параметры конфигурации узла были удалены в NDB 7.5. Никакие системные переменные, переменные статуса или опции
не устарели в NDB 7.5. Ничего не удалено в NDB 7.5. Следующие параметры конфигурации узла были добавлены в NDB 7.6. Нет таких в NDB 7.6. Ничего не устарело. Ничего не удалено. MySQL Server предлагает много выбора в механизмах хранения.
Начиная с обоих В этой секции мы обсуждаем и сравниваем некоторые особенности
NDB Cluster 7.5 тспользует mysqld
на основе MySQL 5.7, включая поддержку
Также верно, что некоторыми типами общих бизнес-приложений можно управлять
в NDB Cluster или MySQL Server (скорее всего, используя
Для получения информации об относительных особенностях механизмов
См. Alternative Storage Engines
для получения дополнительной информации о механизмах хранения MySQL. Механизм хранения Таблица 3.1.
Различия между InnoDB и NDB NDB Cluster имеет диапазон уникальных признаков, которые делают ее
идеалом, чтобы служить запросам, требующим высокой доступности, быстрой
отказоустойчивости, высокой пропускной способности и низкого времени
ожидания. Из-за распределенной архитектуры и внедрения мультиузлов, у NDB
Cluster также есть определенные ограничения, которые могут помешать некоторой
рабочей нагрузке. Много существенных различий в поведении между
Таблица 3.2. Различия между механизмами хранения InnoDB и NDB с
общими типами управляемых данными рабочих нагрузок приложений. Сравнивая требования функции приложения с возможностями
В следующей таблице перечислены особенности поддерживаемого приложения,
согласно механизму хранения, к которому, как правило, лучше
подходит каждая особенность. Таблица 3.3. Поддерживаемые возможности приложений
согласно механизму хранения, к которому, как правило, лучше
подходит каждая особенность Внешние ключи NDB Cluster 7.5 поддерживает внешние ключи Полное сканирование таблицы Очень большие базы данных, строки или транзакции Транзакции кроме
Масштабирование записи 99.999% uptime Добавление онлайн узлов и операции по схеме онлайн Многократные SQL и NoSQL API (см.
NDB Cluster APIs: Overview and Concepts) Работа в реальном времени Ограниченное использование столбцов
Внешние ключи поддерживаются, хотя их использование может оказать
влияние на работу на высокой пропускной способности
В секциях, которые следуют, мы обсуждаем известные ограничения в
текущих выпусках NDB Cluster по сравнению с особенностями, доступными,
используя NDB Cluster Cluster Direct API (NDBAPI) Cluster Disk Data Cluster Replication ClusterJ См. Previous NDB Cluster Issues Resolved in NDB Cluster 8.0
для получения списка проблем в более ранних выпусках, которые были решены в
NDB Cluster 7.5. Ограничения и другие проблемы, определенные для NDB Cluster Replication,
описаны в
разделе 8.3. Некоторые SQL-операторы, касающиеся определенных особенностей MySQL,
производят ошибки, когда используются с
Временные таблицы. Временные таблицы не поддерживаются.
Попытка составить временную таблицу, которая использует
Индексы и ключи в таблицах NDB.
Ключи и индексы на таблицах NDB Cluster
подвергаются следующим ограничениям: Ширина столбца. Попытка создать индекс на столбце таблицы
Столбцы TEXT и BLOB. Вы не можете создать индексы на столбцах
Индексы FULLTEXT.
Однако можно создать индексы на столбцах
Ключи USING HASH и NULL. Используя nullable колонки в
уникальных ключах и первичные ключи, запросы, использующие эти колонки,
обработаны как полное сканирование таблицы. Чтобы обойти эту проблему,
сделайте колонку Префиксы. Нет никаких индексов префикса,
только все колонки могут быть внесены в индекс. Размер индекса столбца
Столбцы BIT.
Столбцы Столбцы AUTO_INCREMENT. Как другие механизмы
хранения MySQL, Ограничения на внешние ключи.
Поддержка ограничений внешнего ключа в NDB 7.5 сопоставима с обеспеченной
Каждая колонка, на которую ссылаются как внешний ключ, требует
явного уникального ключа, если это не первичный ключ таблицы. Это вызвано тем, что обновление первичного ключа осуществляется как
удаление старой строки (содержащей старый первичный ключ) плюс вставка новой
строки (с новым первичным ключом). Это невидимо ядром
С NDB 7.5.14 и NDB 7.6.10: Ключевые слова В более ранних версиях NDB Cluster, составляя таблицу с внешним
ключом, ссылающимся на индекс в другой таблице, иногда казалось возможным
создать внешний ключ, даже если порядок колонок в индексах не соответствовал,
вследствие того, что соответствующая ошибка не всегда возвращалась внутренне.
Частичная фиксация для этой проблемы улучшилась, ошибка раньше внутренне
работала в большинстве случаев, однако, эта ситуация остается возможной,
если родительский индекс уникальный (Bug #18094360). До NDB 7.5.6, добавляя или удаляя использование внешнего ключа
Эта проблема устраняется в NDB 7.5.6 (Bug #82989, Bug #24666177).
NDB Cluster и типы данных геометрии.
Типы данных геометрии
( Наборы символов и двоичные файлы журнала.
Сейчас таблицы Используйте только символы Latin-1, называя двоичные файлы журнала или
устанавливая любые опции
Создание таблиц NDB с определенным пользователями разделением.
Поддержка определенного пользователями разделения в NDB Cluster
ограничивается разделением [ Возможно отвергнуть это ограничение, но выполнение этого
не поддерживается для использования в производственных параметрах настройки.
Для получения дополнительной информации посмотрите
see User-defined partitioning and the NDB storage
engine (NDB Cluster). Схема выделения разделов по умолчанию. Все таблицы NDB Cluster
по умолчанию разделены У таблицы должен быть явный первичный ключ. Все колонки, перечисленные в выражении разделения таблицы, должны быть
частью первичного ключа. Исключение. Если разделенная пользователями таблица
Максимальное количество разделов для таблиц NDBCLUSTER.
Максимальное количество разделов, которое может быть определено для таблиц
DROP PARTITION не поддерживается. Невозможно исключить раздел из
таблиц Построчная репликация.
Используя построчную
репликацию с NDB Cluster, двоичная регистрация не может быть отключена.
Таким образом, механизм хранения Тип данных JSON.
Тип данных MySQL Таблицы NDB API не имеет специального положения для работы с данными
Таблицы информации о CPU и потоках в ndbinfo.
NDB 7.5.2 добавляет несколько новых таблиц в БД
Для получения дополнительной информации об этих таблицах, посмотрите
раздел 7.10. Таблицы информации о блокировках в ndbinfo.
NDB 7.5.3 добавляет новые таблицы к БД
В этой секции мы перечисляем пределы NDB Cluster, отличающиеся
от обычного MySQL. Использование памяти и восстановление.
Память потребленная, когда данные вставляются в таблицу
A Катящийся перезапуск группы также освобождает любую память, используемую
удаленными строкими. Посмотрите
раздел 7.5. Ограничения, наложенные конфигурацией группы.
Много жестких пределов существуют, которые являются конфигурируемыми,
но ограничены доступной оперативной памятью. См. полный список параметров
конфигурации в разделе
5.3. Большинство параметров конфигурации может быть модернизировано
онлайн. Эти жесткие пределы включают: Емкость памяти базы данных и емкость памяти индекса
(
См.
раздел 5.3.6. Максимальное число операций, которые могут быть выполнены за
транзакцию, определяется, используя параметры конфигурации
Оптовая загрузка,
Различные пределы связаны с таблицами и индексами. Например,
максимальное количество заказных индексов в группе определяется
Узел и максимумы объекта данных.
Следующие пределы относятся к числам узлов группы и объектов метаданных: Максимальное количество узлов данных равняется 48. У узла данных должен быть ID узла в диапазоне 1-48 включительно.
Управление и узлы API могут использовать ID
узла в диапазоне 1-255 включительно. Полное максимальное количество узлов в NDB Cluster 255.
Это число включает все узлы SQL (MySQL Server), API,
данных и серверы управления. Максимальное количество объектов метаданных в текущих версиях NDB
Cluster 20320. Этот предел жестко закодирован. См. Previous NDB Cluster Issues Resolved in NDB Cluster 8.0.
Много ограничений существуют в NDB Cluster
относительно обработки транзакций. Они включают следующее: Уровень изоляции транзакции.
Нейтральные данные никогда не возвращаются, но когда транзакция,
изменяющая много строк, работает одновременно с транзакцией, читающей те же
самые строки, транзакция, выполняющая чтение, может наблюдать вместе
значения до и после
для различных строк среди них, вследствие того, что данный запрос чтения
может быть обработан прежде или после передачи другой транзакции. Чтобы гарантировать, что данная транзакция читает только значения прежде
или после, можно наложить использование блокировок строки
Увеличенная частота блокировки ждет ошибки из-за
тайм-аута и уменьшает параллелизм. Увеличение издержек обработки транзакций
из-за чтения, ждущего фазы передачи. Возможность истощения доступного количества параллельных
блокировок, которое ограничивается
См.
раздел 7.3.4 для получения информации о том, как уровни изоляции
транзакции в NDB Cluster могут затронуть резервную копию и восстановление
баз данных Транзакции и столбцы BLOB или TEXT.
Для любого
Для любого
Эта проблема не происходит для запросов, которые используют индекс или
сканирование таблицы, даже для таблиц
Например, рассмотрите таблицу Любой из следующих запросов на Однако, ни один из четырех запросов, показанных здесь, не вызывает
общую блокировку чтения: Это вызвано тем, что из этих четырех запросов первый применяет
просмотр индекса, второй и третий сканирование таблицы, а
четвертый, используя поиск первичного ключа, не получает значение никакого
Можно помочь минимизировать проблемы с общими блокировкими чтения,
избежав запросов, которые используют поиски уникального ключа,
которые получают Обратные перемотки. Нет никаких частичных транзакций и никаких
частичных обратных перемоток транзакций. Дублирование ключа или подобная
ошибка заставляет всю транзакцию быть отмененной до прежнего уровня. Это поведение отличается от других механизмов системы
хранения транзакций, например,
Транзакции и использование памяти.
Как отмечено в другом месте в этой главе, NDB Cluster
не обращается с большими транзакциями хорошо, лучше выполнить много маленьких
транзакций с несколькими операциями каждая, чем делать попытку единственной
большой транзакции, содержащей очень много операций. Среди других соображений
большие транзакции требуют очень больших объемов памяти. Из-за этого
транзакционное поведение многих запросов MySQL затронуто, как
описано в следующем списке: LOAD DATA.
При выполнении
ALTER TABLE и транзакции.
Копируя таблицу Транзакции и функция COUNT().
При использовании NDB Cluster Replication
невозможно гарантировать согласованность транзакций и функции
Запуская, останавливая или перезапуская узел можно дать начало
нерегулярным ошибкам, заставляющим некоторые транзакции потерпеть неудачу.
Они включают следующие случаи: Нерегулярные ошибки..
Сначала начиная узел, возможно, что можно видеть Error 1204
Temporary failure, distribution
changed и подобные нерегулярные ошибки. Ошибки из-за неудачи узла.
Остановка или неудача любого узла данных могут привести ко многим различным
ошибкам неудачи узла. Однако, не должно быть никаких прерванных транзакций,
выполняя запланированное закрытие кластера. В любом из этих случаев любые ошибки, которые произведены, должны быть
обработаны в приложении. Это должно быть сделано, повторив транзакцию. См.
раздел 3.7.2. У некоторых объектов базы данных, таких как таблицы и индексы, есть
различные ограничения, используя
Имена базы данных и имена таблиц.
Используя Количество объектов базы данных.
Максимальное количество всех
объекты базы данных
Признаки на таблицу.
Максимальное количество признаков (то есть, колонок и индексов), которое
может принадлежать данной таблице, 512. Признаки на ключ.
Максимальное количество признаков на ключ равняется 32. Размер строки.
Максимальный разрешенный размер любой строки составляет 14000 байтов. Каждый столбец Кроме того, максимальное смещение для столбца фиксированной ширины
в Столбцы BIT на таблицу.
Максимальная объединенная ширина для всех столбцов
Хранение колонки FIXED.
NDB Cluster 7.5 и более поздние поддерживают
максимум 128 TB на фрагмент данных в столбцах
Много функций, поддержанных другими механизмами хранения, не
поддерживаются для Префиксы индекса.
Префиксы на индексах не поддерживаются для
Запрос, содержащий префикс индекса, и создающий или изменяющий таблицу
Это происходит вследствие правила синтаксиса SQL, что ни у какого индекса
не может быть префикса больше, чем он сам. Точки сохранения и обратные перемотки.
Точки сохранения и обратные перемотки к точкам сохранения проигнорированы,
как в Длительность передачи.
Нет длительности передачи на диске. Передачи копируются, но нет никакой
гарантии, что журналы сбрасываются на диск при передаче. Репликация. Основанная на запросе репликация
не поддерживается. Используйте
Репликация используя глобальные идентификаторы транзакции (GTID)
несовместима с NDB Cluster 7.5 или NDB CLuster 7.6.
Не позволяйте GTID, используя Полусинхронная репликация не поддерживается в NDB Cluster. Произведенные колонки.
Как с другими механизмами хранения, можно создать индекс на сохраненной
произведенной колонке, но необходимо принять во внимание, что
NDB Cluster пишет изменения в сохраненных произведенных колонках к
двоичному журналу регистрации, но не регистрирует сделанные виртуальные
колонки. Это не должно производиться NDB Cluster Replication или
репликацией между См.
раздел 3.7.3 для получения дополнительной информации касающийся
ограничений на операционную обработку в
Следующие исполнительные проблемы определены для NDB Cluster: Просмотры диапазона.
Есть проблемы производительности запросов из-за последовательного доступа к
Надежность записей в диапазоне.
Статистика Уникальные индексы хэша. Уникальные индексы хэша, созданные
Следующее ограничения, определенные для механизма хранения
Машинная архитектура.
У всех машин, используемых в группе, должна быть та же самая архитектура.
Таким образом, все машины, принимающие узлы, должны быть с одним и тем же
порядком байтов, вы не можете использовать их смесь.
Например, у вас не может быть узла управления на PowerPC,
который направляет узел данных на x86. Это ограничение не относится к
машинам, выполняющим mysql
или другим клиентам, которые могут получать доступ к узлам SQL. Двоичный журнал.
NDB Cluster имеет следующие ограничения относительно двоичной регистрации:
NDB Cluster не может произвести двоичную регистрацию для таблиц с
Только следующие операции по схеме вошли в двоичную регистрацию
группы, которая не выполняет запросы
mysqld: Операции по схеме. Операции по схеме (запросы DDL) отклонены в
то время, как любой узел данных перезапускается. Операции по схеме также не
поддерживаются, выполняя модернизацию онлайн или удаление. Количество точных копий. Количество точных копий, как
определено параметром конфигурации узла данных
Урегулирование
См.
раздел 3.7.10. Дисковые максимумы и минимумы объекта данных.
Дисковые объекты данных подвергаются следующим максимумам и минимумам: Максимальное количество табличных пространств:
232 (4294967296). Максимальное количество файлов данных на табличное пространство:
216 (65536). Минимальные и максимальные возможные размеры экстентов для файлов
данных табличного пространства 32K и 2G, соответственно. Посмотрите
CREATE TABLESPACE Statement. Кроме того, работая с таблицами NDB Disk Data,
необходимо знать следующие проблемы файлов данных и экстентов: Файлы данных используют
Файлы данных используют дескрипторы файлов. Важно иметь в виду, что
файлы данных всегда открыты, что означает, что дескрипторы файлов всегда
используются и не могут быть снова использованы для
других системных задач. Экстенты требуют достаточной
Таблицы Disk Data и бездисковый режим.
Использование таблиц Disk Data не поддерживается в бездисковом режиме. Много узлов SQL.
Следующее это проблемы, касающиеся использования многократных серверов MySQL
как узлов SQL NDB Cluster для
Никаких распределенных блокировок таблицы.
Операции ALTER TABLE.
Многократные узлы управления.
Используя многократные серверы управления: Если какой-либо из серверов управления работает на том же самом
хосте, необходимо дать узлам явные ID в строках подключения, потому что
автоматическое распределение ID узла не работает через многократные серверы
управления с тем же самым хостом. Это не требуется, если каждый сервер
управления работает на своем хосте. Когда сервер управления запускается, он сначала проверяет на любой
другой сервер управления в том же самом NDB Cluster
и после успешной связи с другим сервером управления использует его данные
конфигурации. Это означает, что опции запуска сервера управления
Многократные сетевые адреса. Многократные сетевые адреса на
узел данных не поддерживаются. Использование их склонно вызвать проблемы: в
случае неудачи узла данных узел SQL ждет подтверждения, что узел данных
отвалился, но никогда не получает его, потому что другой маршрут к тому узлу
данных остается открытым. Это может эффективно сделать кластер нерабочим. Возможно использовать многократные сетевые
аппаратные интерфейсы (например,
карты Ethernet) для единственного узла данных, но они должны быть связаны с
тем же самым адресом. Это также означает, что невозможно использовать больше
одного раздела
Глава 3. Обзор NDB Cluster
NDB (сокращение от
Network
Data
Base). В нашей документации термин
NDB
относится к части установки, которая является определенной для
хранения, тогда как MySQL NDB Cluster
относится к комбинации одного или более серверов MySQL с механизмом
хранения NDB.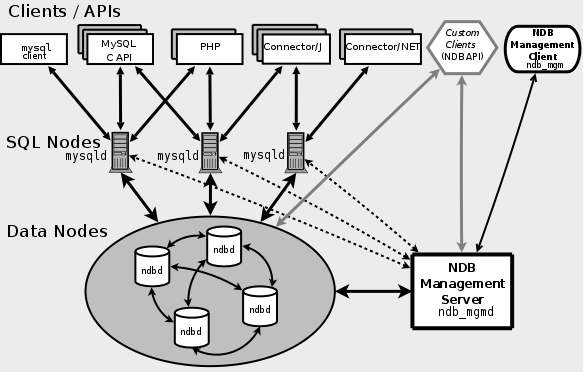
NDB,
таблицы (и данные о таблице) сохранены в узлах данных. Такие таблицы
непосредственно доступны от всех других серверов MySQL (узлы SQL) в группе.
Таким образом, в запросе на платежную ведомость, хранящем данные в группе,
если приложение обновило зарплату сотрудника, все другие серверы MySQL,
которые запрашивают эти данные, немедленно видят это изменение.NDB
и не может получить доступ ни к каким данным NDB Cluster.NDB
в клиенте управления NDB Cluster, программа
ndb_restore включена в
пакет NDB Cluster. См. разделы 7.3
и раздел 6.24
. Можно также использовать стандартную функциональность MySQL,
обеспеченную с этой целью в
mysqldump и сервер MySQL.
См. mysqldump.3.1. Понятия ядра NDB Cluster
NDBCLUSTER
(также NDB) это
механизм памяти, предлагающий особенности постоянства
данных и высокую доступность.NDBCLUSTER
может формироваться с диапазоном отказоустойчивости и вариантов выравнивания
нагрузки, но является самым легким начать с механизмом
хранения на уровне группы. В NDB Cluster механизм
NDB
содержит полный набор данных, зависящий только от других
данных в самой группе.NDBCLUSTER.
Узел SQL это процесс mysqld,
начатый с опциями
--ndbcluster и
--ndb-connectstring,
которые объяснены в другом месте в этой главе, возможно также с
дополнительными вариантами сервера MySQL.NDB API и клиенты управления.
Они описаны в следующих нескольких параграфах.jdbc:mysql:loadbalance:// (улучшено в
Connector/J 5.1.7), чтобы достигнуть выравнивания нагрузки прозрачно, для
получения дополнительной информации об использовании Connector/J с NDB
Cluster см. Using Connector/J with NDB Cluster.NDBCLUSTER, обходя любые MySQL Server, которые
могут быть связаны с группой, используя NDB
API, высокоуровневый C++ API. Такие запросы могут быть полезны для
специализированных целей, где интерфейс SQL к данным не необходим. Для
получения дополнительной информации посмотрите
The NDB API.NDB-Java приложения
могут также быть написаны для NDB Cluster с NDB
Cluster Connector for Java. NDB Cluster Connector включает
ClusterJ,
API высокого уровня, подобный структурам постоянства отображения
Hibernate и JPA, которые соединяются непосредственно с
NDBCLUSTER и не требует доступа к MySQL Server.
Поддержка также оказывается в NDB Cluster для
ClusterJPA, реализации OpenJPA для NDB
Cluster, которая усиливает преимущества ClusterJ и JDBC,
поиски ID и другие быстрые операции выполняются, используя ClusterJ
(обходя MySQL Server) в то время, как более сложные запросы, которые могут
извлечь выгоду из оптимизатора запросов MySQL, посылают через MySQL Server,
применяя JDBC. См.
Java and NDB Cluster и
The ClusterJ API and Data Object Model.NDB, а также для MySQL Server.
Запросы используя этот соединитель типично управляемы событиями и используют
модель объекта области, подобную во многих отношениях используемой ClusterJ.
См. MySQL NoSQL Connector for JavaScript.NDB
есть два типа контрольных точек, которые сотрудничают, чтобы
гарантировать, что сохраняется последовательное представление данных.
Их показывают в следующем списке:EnablePartialLcp и
RecoveryWork, которые позволяют частичный
LCP и управляют объемом хранения, который они используют.
3.2. Узлы NDB Cluster, группы узлов, точные копии и разделение
NoOfReplicas):
[число групп узлов] = [число узлов данных] /
NoOfReplicas
NoOfReplicas = 1 в
config.ini, 2 группы узлов, если
NoOfReplicas = 2 или 1 группа узлов, если
NoOfReplicas = 4. Точные копии обсуждены позже в этой секции,
для получения дополнительной информации о
NoOfReplicas см.
раздел 5.3.6.
[число разделов] = [число узлов данных] * [число потоков LDM]
MaxNoOfExecutionThreads.
При использовании
ndbd
есть единственный поток LDM, что означает, что есть столько же разделов,
сколько узлов в кластере. Это также имеет место, используя
ndbmtd с
MaxNoOfExecutionThreads = 3 или меньше
(необходимо знать, что количество потоков LDM растет с увеличением
этого параметра, но не строго линейным способом, и что есть дополнительные
ограничения, см. описание
MaxNoOfExecutionThreads).NDBCLUSTER сам.
Однако также возможно использовать определенное пользователями разделение с
таблицами NDBCLUSTER.
Это подвергается следующим ограничениям:KEY и
LINEAR KEY поддерживаются в производстве с
таблицами NDB.NDB,
8 * [, число групп узлов в NDB Cluster
определяется как обсуждено ранее в этой секции. При работе с
ndbd для процессов узла данных, определение числа
потоков LDM не имеют никакого эффекта (так как
число потоков LDM
] * [число групп узлов
]
ThreadConfig применяется только к
only to
ndbmtd),
в таких случаях можно рассматривать это значение
как будто это было равно 1 в целях выполнить это вычисление.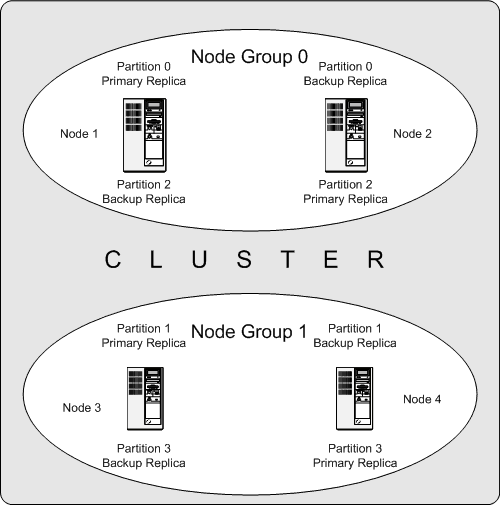
3.3. Требования NDB Cluster
HeartbeatIntervalDbDb и
HeartbeatIntervalDbApi для NDB Cluster,
можно достигнуть быстрого обнаружения, отказоустойчивости и возвратиться к
работе, избегая потенциально дорогих ложных сбоев.
3.4. Новое в NDB Cluster
3.4.1. Новое в NDB Cluster 7.5
ndbinfo, она теперь предоставляет подробную информацию о
параметрах конфигурации узла NDB Cluster.config_params
была сделана только для чтения и увеличена с дополнительными колонками,
предоставляющими информацию о каждом параметре конфигурации, включая тип
параметра, значение по умолчанию, максимальные и минимальные значения (где
применимы), краткое описание параметра и требуется ли параметр.
Эта таблица также предоставляет каждому параметру уникальный
param_number.config_values
показывает текущее значение данного параметра на узле, имеющем указанный ID.
Параметр определяется столбцом config_param,
который отображается к config_params
для param_number таблицы.
SELECT p.param_name AS Name, v.node_id AS Node, p.param_type AS Type,
p.param_default AS 'Default', p.param_min AS Minimum,
p.param_max AS Maximum,
CASE p.param_mandatory WHEN 1 THEN 'Y' ELSE 'N' END AS 'Required',
v.config_value AS Current FROM config_params p
JOIN config_values v ON p.param_number = v.config_param
WHERE p.param_name IN ('NodeId','HostName','DataMemory','IndexMemory');
ndbinfo
больше не зависит от механизма хранения MyISAM.
Все таблицы и представления ndbinfo
теперь используют NDB (показано как
NDBINFO).ndbinfo
были введены в NDB 7.5.4. Эти таблицы перечисляются
здесь с краткими описаниями:dict_obj_info
обеспечивает имена и типы объектов базы данных в
NDB, а также информацию о родительском объекте,
когда это применимо.table_distribution_status
обеспечивает информацию о статусе распределения таблицы
NDB.table_fragments
предоставляет информацию о распределении фрагментов таблицы
NDB.table_info
предоставляет информацию о регистрации, контрольных точках, хранении и
других параметрах для каждой таблицы NDB
.table_replicas
предоставляет информацию о точных копиях фрагмента.ROW_FORMAT и
COLUMN_FORMAT в
CREATE TABLE
могут быть установлены в DYNAMIC вместо
FIXED использованием новой серверной
переменной MySQL
ndb_default_column_format,
установите это в FIXED или
DYNAMIC (или начните
mysqld с эквивалентной опцией
--ndb-default-column-format=FIXED),
чтобы вынудить это значение использоваться для
COLUMN_FORMAT и
ROW_FORMAT. До NDB 7.5.4 умолчанием для этой
переменной было DYNAMIC,
в этой и более поздних версиях умолчание
FIXED, что
обеспечивает совместимость с предшествующими выпусками (Bug #24487363).ndb_default_column_format),
существующие столбцы изменяются, чтобы использовать их также, при условии,
что запрос ALTER TABLE, выполняющий эту
операцию, определяет ALGORITHM=COPY.ALTER TABLE
не может быть сделано неявно, если
mysqld работает с
--ndb-allow-copying-alter-table=FALSE
.ndb_binlog_index,
используемая в NDB Cluster Replication, применяет механизм хранения
InnoDB вместо
MyISAM. Модернизируя, можно управлять
mysql_upgrade с
--force
--upgrade-system-tables,
чтобы заставить его выполнить
ALTER TABLE ... ENGINE=INNODB
на этой таблице. Использование MyISAM
остается поддержанным для обратной совместимости.ALTER TABLE.
Это больше не поддерживается в NDB Cluster 7.5,
что делает исключительное использование
ALGORITHM = DEFAULT|COPY|INPLACE
для таблицы DDL, как в стандартном MySQL Server.ALTER TABLE ... ALGORITHM=INPLACE RENAME
теперь содержит операции DDL в дополнение к переименованию.ExecuteOnComputer для
узлов управления,
данных и
API
устарел и теперь подвергается удалению в будущем выпуске NDB Cluster.
Необходимо использовать эквивалент HostName
для всех трех типов узлов.EXPLAIN более точны.SHOW INDEX улучшены.
--ndb-cluster-connection-pool-nodeids,
которая позволяет некоторым ID узлов быть установленными для пула соединений.
Это урегулирование отвергает
--ndb-nodeid, что означает, что это также отвергает опцию
--ndb-connectstring и переменную окружения
NDB_CONNECTSTRING.--ndb-cluster-connection-pool для
mysqld.create_old_temporals устарела еще в
NDB Cluster 7.4 и наконец удалена.PROMPT
:
ndb_mgm>
PROMPT mgm#1:
mgm#1: SHOW
Cluster Configuration
---------------------
[ndbd(NDB)] 4 node(s)
id=5@10.100.1.1(mysql-5.7.29-ndb-7.5.17, Nodegroup: 0, *)
id=6@10.100.1.3(mysql-5.7.29-ndb-7.5.17, Nodegroup: 0)
id=7@10.100.1.9(mysql-5.7.29-ndb-7.5.17, Nodegroup: 1)
id=8@10.100.1.11(mysql-5.7.29-ndb-7.5.17, Nodegroup: 1)
[ndb_mgmd(MGM)] 1 node(s)
id=50 @10.100.1.8(mysql-5.7.29-ndb-7.5.17)
[mysqld(API)] 2 node(s)
id=100@10.100.1.8(5.7.29-ndb-7.5.17)
id=101@10.100.1.10(5.7.29-ndb-7.5.17)
mgm#1: PROMPT
ndb_mgm> EXIT
jon@valhaj:/usr/local/mysql/bin>
FIXED. В
NDB Cluster 7.4 и ранее это было 16 GB.Id: устарел в NDB 7.1.9, заменен
NodeId.NoOfDiskPagesToDiskDuringRestartTUP,
NoOfDiskPagesToDiskDuringRestartACC:
устарели, не имели никакого эффекта, заменены в MySQL 5.1.6 на
DiskCheckpointSpeedInRestart,
который самостоятельно позже устарел (в NDB 7.4.1) и теперь удален.NoOfDiskPagesToDiskAfterRestartACC,
NoOfDiskPagesToDiskAfterRestartTUP:
устарели, не имели никакого эффекта, заменены в MySQL 5.1.6 на
DiskCheckpointSpeed,
который самостоятельно позже устарел (в NDB 7.4.1) и теперь удален.ReservedSendBufferMemory: устарел в
NDB 7.2.5, больше не действует.MaxNoOfIndexes: старый (до MySQL
4.1), не работает, давно заменен
MaxNoOfOrderedIndexes или
MaxNoOfUniqueHashIndexes.Discless: старый (до MySQL 4.1)
давно заменен
Diskless.ByteOrder
был также удален в NDB 7.5.0.DBTC и
DBDIH в
NDB,
предоставляя возможность более высокой масштабируемости узлов данных, когда
используется для операций по просмотру, уменьшая использование ресурсов CPU
для операций по просмотру, в некоторых случаях приблизительно
на пять процентов.BACKUP были также улучшены и сделаны более
эффективными, чем в предыдущих выпусках.JSON для таблиц
NDB и функции JSON в MySQL Server,
согласно ограничению, что таблица
NDB может иметь самое большее 3 столбца
JSON.
ndb_read_backup.PARTITION_BALANCE
(FRAGMENT_COUNT_TYPE в NDB
7.5.4), включенной в комментарий NDB_TABLE в
CREATE TABLE или
ALTER TABLE.
Параметры настройки для уровня таблицы
READ_BACKUP также поддерживаются, используя этот
синтаксис. Для получения дополнительной информации и примеров посмотрите
Setting NDB_TABLE Options.ndb_data_node_neighbour.
Это предназначается для использования в операционных советах, чтобы
предоставить соседний
узел данных этому узлу SQL.--restore-meta
теперь использует разделение целевой группы по умолчанию вместо того, чтобы
использовать то же самое разделение, как оригинальная группа, от которой была
взята резервная копия. Посмотрите
раздел 6.24.1.2.READ_BACKUP: в
этой и более поздних версиях возможно установить
READ_BACKUP для данной таблицы онлайн как часть
ALTER TABLE ... ALGORITHM=INPLACE ...
.ThreadConfig, параметра конфигурации
многопоточного узла данных
(
ndbmtd),
включая поддержку увеличенного числа платформ. Эти изменения описаны
в следующих нескольких параграфах.cpubind и
cpuset. Исключительный захват CPU теперь
поддерживается только на Solaris через параметры
cpubind_exclusive и
cpuset_exclusive.thread_prio.
thread_prio поддерживается в Linux,
FreeBSD, Windows и Solaris. Для получения дополнительной информации см.
описание
ThreadConfig.realtime
теперь поддерживается на платформах Windows.NDB
могут теперь содержать больше 16 ГБ данных для фиксированных колонок, и
максимальный размер разделения для фиксированных колонок теперь поднят до
128 TB. Предыдущее ограничение было вследствие того, что блок
DBACC в ядре NDB
использовал только 32-битные ссылки на часть фиксированного размера строки в
блоке DBTUP, хотя 45-битные ссылки на эти данные
используются в DBTUP самостоятельно и в другом
месте в ядре вне DBACC,
все такие ссылки к данным, обработанным в блоке
DBACC, теперь используют 45 бит.--print-sql-log в утилиту
for the
ndb_restore.
Этот выбор позволяет регистрацию SQL в stdout.
ВАЖНО:
у каждой таблицы, которая будет восстановлена, используя этот выбор, должен
быть явно определенный первичный ключ.mysql-cluster.
Узлы данных теперь устанавливаются, используя пакет
data-node,
узлы управления теперь устанавливаются из
management-server, узлы SQL
требуют пакеты server и
common. Клиенты MySQL и
NDB, включая
mysql и
ndb_mgm,
теперь находятся в client RPM.ndbinfo, чтобы предоставить информацию
об узлах группы. Эти таблицы перечисляются здесь:config_nodes:
Эта таблица предоставляет ID узла, тип процесса и имя хоста для каждого узла,
перечисленного в конфигурационном файле кластера NDB.processes показывает информацию
об узлах, в настоящее время связываемых с кластером. Эта информация включает
имя процесса и системный ID процесса. Для каждого узла данных и узла SQL это
также показывает ID процесса ангела узла. Кроме того, таблица показывает
сервисный адрес для каждого связанного узла,
этот адрес может быть установлен в приложениях API NDB, используя метод
Ndb_cluster_connection::set_service_uri()
, добавленный в NDB 7.5.7.Ndb_system_name.
Приложения NDB API могут использовать метод
Ndb_cluster_connection::get_system_name()
.[system] к конфигурационному файлу и установив
параметр Name к значению по Вашему выбору в этой
секции до старта сервера управления.--nodeid и
--backupid обе требуются, вызывая
ndb_restore.--check-missing.
Чтобы заменить любую недостающую часть заполнителями, используйте опцию
--add-missing.
3.4.2. Новое в NDB Cluster 7.6
--initial)
как часть процесса модернизации. Можно ожидать, что этот шаг будет сделан
обязательным как часть модернизации от NDB 7.5 или более раннего
до NDB 7.6 или позже.
--initial как часть процесса.
Это вызвано тем, что NDB 7.5 и более ранний ряд выпусков не в
состоянии прочитать новый формат данных.NDB, теперь ассигнуются динамично от
ассигнованной для
DataMemory. Поэтому параметр
IndexMemory устарел и будет удален.IndexMemory
задан в файле config.ini,
сервер управления выпускает предупреждение
IndexMemory is deprecated, use Number bytes on
each ndbd(DB) node allocated for storing indexes instead
при запуске, и любая память, назначенная на этот параметр, автоматически
добавляется к DataMemory.DataMemory было увеличено до 98M, умолчание для
IndexMemory теперь 0.NDB, дальнейшая выгода этих изменений в том,
что увеличение масштаба, увеличивая число потоков LDM больше не
ограничивается тем, что установлено недостаточно большое значение для
IndexMemory.
Это потому что память индекса больше не статическое количество, которое
ассигнуется только однажды (когда кластер стартует), но может теперь быть
ассигнована и освобождена как требуется. Ранее, иногда имело место то, что
увеличение числа потоков LDM могло привести к истощению памяти индекса в то
время, как большие объемы DataMemory
были доступны.DataMemory,
не связанных непосредственно с хранением данных таблицы, теперь используют
операционную память вместо этого.SharedGlobalMemory,
чтобы позволить операционной памяти увеличиваться при необходимости,
используя NDB Cluster Replication, что требует большого буферизования на
узлах данных. На системах, выполняющих начальную инициализацию,
может быть необходимо разбить очень большие транзакции на меньшие части.MemoryUsage (см.
раздел 7.6.2)
и пишут соответствующие сообщения в журнал кластера, когда
использование ресурсов достигает 99%, а также когда это достигает 80%, 90%
или 100%, как прежде.IndexMemory
больше не одно из значений, показанных в
столбце memory_type таблицы
ndbinfo.memoryusage,
это также больше не показывается в
ndb_config.
REPORT MEMORYUSAGE и другие команды, которые выставляют
потребление памяти теперь, показывают потребление памяти индекса, используя
32K страницы (ранее, они были 8K страницами).ndbinfo.resources теперь показывает
ресурс DISK_OPERATIONS как
TRANSACTION_MEMORY, ресурс
RESERVED удален.
ndbinfo, чтобы предоставить информацию об узлах,
эти таблицы перечисляются здесь:config_nodes:
Эта таблица ID узла, типа процесса и имени хоста для каждого узла,
перечисленного в конфигурационном файле NDB cluster.processes показывает информацию
об узлах, в настоящее время связываемых с кластером,
эта информация включает имя процесса и системный процесс ID, для каждого узла
данных и узла SQL, это также показывает ID процесса ангела узла.
Кроме того, таблица показывает сервисный адрес для каждого связанного узла,
этот адрес может быть установлен в приложениях API NDB, используя метод
Ndb_cluster_connection::set_service_uri()
, добавленный в NDB 7.6.2.Ndb_system_name, приложения
NDB API могут использовать метод
Ndb_cluster_connection::get_system_name()
, который добавляется в том же самом выпуске.[system] к конфигурационному файлу и задав
параметр Name
в этой секции до старта сервера управления..mcc
как альтернативу основанному на cookie.
Постоянное хранение теперь используется по умолчанию.NDB
, используя API NDB (сервер MySQL необходим только, чтобы
составить таблицу и базу данных, в которой это расположено).
ndb_import
может рассматриваться как аналог
mysqlimport или SQL-запроса
LOAD DATA
и поддерживает многие из тех или подобных возможностей
для форматирования данных.NDB существуют,
ndb_import
нужна только связь с сервером управления
(
ndb_mgmd),
чтобы выполнить импорт, поэтому, должен быть доступный слот
[api] в файле
config.ini.NDB
в режиме реального времени. Эта информация может быть показана в текстовом
формате, как граф ASCII или обоими способами. Граф можно показать в цвете
или шкале полутонов.SELECT
на таблицах в базе данных
ndbinfo.NDB. Это удаление издержек
должно привести к значимому улучшению исполнения LDM и потоков TC примерно на
10% во многих случаях.NDB теперь отслеживает задержки I/O глобально,
чтобы об этом сообщили, как только по крайней мере один поток пишет с
задержкой I/O, это тогда удостоверяется в том,
что скорость для этого LCP проведена в жизнь для всех потоков LDM на время
замедления. Поскольку замедление записи теперь наблюдается другими копиями
LDM, общая пропускная способность увеличена.
Это позволяет преодолеть дисковую перегрузку (или другое условие, вызывающее
задержку I/O) быстрее в таких случаях, чем это было ранее.error_messages в
БД
ndbinfo. Кроме того, 7.6.4 представляет клиента командной строки
ndb_perror
для получения информации от кодов ошибок NDB, это заменяет использование
perror с опцией
--ndb,
которая теперь устарела и будет удалена.DBTC
отправляет запрос SPJ к DBSPJ
на том же самом узле, где фрагмент, который будет просмотрен.
Раньше, один такой запрос был отправлен для каждого из фрагментов узла.
Так как количество
DBTC и DBSPJ
обычно определяются меньше, чем количество LDM, это означает, что все
экземпляры SPJ были вовлечены в выполнение единого запроса и на самом деле
некоторые экземпляры SPJ могли получать многократные обращения от того же
самого запроса. В NDB 7.6.4 это становится возможным для единственного
вызова SPJ для обработки набора корневых фрагментов, которые будут
просмотрены так, чтобы только единственный вызов SPJ
(SCAN_FRAGREQ) требовался для отправки
любому данному экземпляру SPJ (блок DBSPJ)
на каждом узле.DBSPJ потребляет относительно
небольшое количество CPU, используемого, оценивая выдвинутое соединение, в
отличие от блока LDM (который ответственен за большинство использования CPU),
представление многократных блоков SPJ добавляет некоторый параллелизм, но
дополнительные издержки также увеличиваются. Позволяя единственному вызову
SPJ обращаться с рядом корневых фрагментов, которые будут просмотрены так,
что только единственный запрос SPJ отправлен каждому экземпляру
DBSPJ на каждом узле и
пакетные размеры ассигнуются на фрагмент, поэтому просмотр мультифрагмента
может получить больший полный пакетный размер, позволив, чтобы некоторая
оптимизация планирования была сделана в блоке SPJ, который может просмотреть
единственный фрагмент за один раз
(предоставляя его полное пакетное распределение размера), просмотреть все
фрагменты в параллельных использующих меньших подпартиях или выполнить
некоторую комбинацию этих вариантов.ODirectSyncFlag,
который вызывает завершение записи журнала отката использованием
O_DIRECT, чтобы обработать вызов
fsync.
ODirectSyncFlag по умолчанию выключен, чтобы
включить установите в true.
ODirect выключен.InitFragmentLogFiles
= SPARSE.--rebuild-indexes.BuildIndexThreads
(с 0 на 128), это предписывает построение оффлайнового индекса по умолчанию
в многопоточном режиме. Значение по умолчанию для
TwoPassInitialNodeRestartCopy
также изменено (с false на
true), чтобы начальный перезапуск узла сначала
скопировал все данные без любого создания индексов с
живого узла на узел, который стартует, построил
оффлайновые индексы после того, как данные были скопированы,
синхронизировался с живым узлом. Это может значительно уменьшить время,
требуемое для создания индексов. Кроме того, чтобы облегчить явный захват
потоками построения оффлайнового индекса определенных CPU, определяется
тип нового потока (idxbld) для параметра
ThreadConfig.NDB
может теперь различать типы потоков выполнения и другие типы потоков, а
также отличать типы потоков, которые постоянно назначены на определенные
задачи, и те, назначения которых просто временные.nosend для
ThreadCOnfig. Устанавливая это в 1, можно удержать потоки
main,
ldm, rep или
tc от помощи потокам передачи.
Этот параметр 0 по умолчанию и не может использоваться с потоками I/O,
передачи, построения индексов или наблюдения.MaxUIBuildBatchSize:
Максимальный пакетный размер просмотра,
используется для создания уникальных ключей.MaxFKBuildBatchSize:
Максимальный пакетный размер просмотра, используется для
создания внешних ключей.MaxReorgBuildBatchSize:
Максимальный пакетный размер просмотра, используется для
перестройки разделения таблицы.EnablePartialLcp
(по умолчанию true, включено)
позволяет частичный LCP.
RecoveryWork управляет процентом пространства LCP.
Это увеличивается с объемом работы, который должен быть выполнен на LCP
во время перезапусков в противоположность выполненному во время
нормального функционирования. Повышение этого значения заставляет
LCP во время нормального функционирования требовать написания меньшего
количества записей и уменьшает обычную рабочую нагрузку.
Повышение этого значения также означает, что перезапуски могут
занять больше времени.EnablePartialLcp=false.
Это использует наименьшее количество места на диске, но также имеет
тенденцию максимизировать нагрузку по записи для LCP. Чтобы оптимизировать
для самой низкой рабочей нагрузки на LCP во время нормального
функционирования, надо использовать
EnablePartialLcp=true и
RecoveryWork=100.
Чтобы использовать наименьшее количество дискового пространства для
частичного LCPs, но с ограниченными записями, надлежит использовать
EnablePartialLcp=true и
RecoveryWork=25,
что является минимумом для
RecoveryWork. По умолчанию
EnablePartialLcp=true и
RecoveryWork=50,
что означает, что файлы LCP требуют приблизительно 1.5 раза
DataMemory, использованием
CompressedLcp=1 это может быть далее уменьшено наполовину.
Времена восстановления, используя настройки по умолчанию должны также
быть намного быстрее, чем когда
EnablePartialLcp =
false.RecoveryWork
увеличено с 50 до 60 в NDB 7.6.5.BackupDataBufferSize,
BackupWriteSize и
BackupMaxWriteSize
теперь устарели и будут удалены.--initial.LGMAN узла данных
обрабатывал записи журнала отмен последовательно,
теперь это сделано параллельно. Поток rep, который готовит записи для потоков
LDM, ждал, пока LDM закончит применять запись теперь поток rep
больше не ждет, а немедленно переходит к следующей записи и LDM.LGMAN сохранено и уменьшено
каждый раз, когда LDM закончил выполнение.
Все записи, принадлежащие странице, посылают в тот же самый LDM,
но не факт, что они будут обработаны в этом порядке, таким образом, карта
хэша страниц, у которых есть отчеты, поддерживает очередь для каждой из этих
страниц. Когда страница доступна в кэше
страницы, все записи в очереди применяются в правильном порядке.UNDO_LCP,
UNDO_LCP_FIRST,
UNDO_LOCAL_LCP,
UNDO_LOCAL_LCP_FIRST,
UNDO_DROP и
UNDO_END.PGMAN,
используя дополнительный рабочий поток
PGMAN,
но применяя журнал отмен было необходимо прочитать страницу снова.O_DIRECT,
это было очень неэффективно, так как страница не кэшировалась
в ядре OS. Чтобы исправить эту проблему, отображение ID страницы на ID
таблицы и ID фрагмента теперь сделано, используя информацию от заголовка
экстента ID таблицы и фрагменты для страниц, используемых в данном экстенте.
Страницы экстента всегда присутствуют в кэше страницы, таким образом, не
надо дополнительно читать их с диска для выполнения отображения. Кроме того,
информация может уже быть прочитана, используя существующий ядерный блок
TSMAN.ODirect.
Arbitration должен теперь быть установлен в одно из его
позволенных значений Default,
Disabled или
WaitExternal.DiskFree),
используя эту информацию, чтобы получить реалистические значения
для параметров конфигурации, которые зависят от него.Password=None.
UseShm = 1 для соответствующего узла
данных. Явно определяя общую память как метод связи, также необходимо, чтобы
узел данных и узел API были определены по
HostName.ShmSize,
ShmSpintime и
SendBufferMemory в разделах
an [shm] или
[shm default] файла
config.ini.
Конфигурация SHM в других отношениях подобна настройке транспортера TCP.
SigNum не используется в новом внедрении SHM, любые параметры
настройки, сделанные для него, теперь проигнорированы.
Раздел 5.3.12
предоставляет больше информации об этих параметрах. Кроме того, как часть
этой работы, код NDB, касающийся старого
транспортера SCI, был удален.SPJ
может принять во внимание, когда он оценивает запрос соединения, в котором
INNER-join по крайней мере, некоторые таблицы. Это означает, что можно
устранить запросы о строке, диапазонах или обоих, как только становится
известным, что один или больше предыдущих запросов не возвратил результатов
для родительской строки. Это экономит узлам данных и блоку
SPJ обработку запроса и строки
результата, которые никогда не принимают участие в строке результата.pk
это первичный ключ на таблицах t2, t3, и t4, а колонки x, y, и z
не внесены в указатель:
SELECT * FROM t1 JOIN t2 ON t2.pk = t1.x JOIN t3 ON t3.pk = t1.y
JOIN t4 ON t4.pk = t1.z;
SPJ,
включая просмотр на таблице t1 и
поиск в каждой из таблиц t2,
t3 и t4,
они были оценены для каждой строки, возвращенной из
t1. Для них SPJ
создает запрос LQHKEYREQ к таблицам
t2, t3 и
t4. Теперь SPJ
учитывает требование, чтобы произвести любые строки результата, внутреннее
объединение должно найти соответствие
во всех присоединяемых таблицах, как только никакие соответствия
не найдены для одной из таблиц, дальнейшие запросы к таблицам, имеющим того
же самого родителя или таблицы, теперь пропускаются.NDB использует приемник опроса, чтобы читать от
сокетов, выполнить сообщения от сокетов и разбудить другие потоки.
При использовании потоков получения время от времени владелец опроса активен
прежде, чем начать будить другие потоки, что обеспечивает определенную
степень параллелизма в потоках получения, но постоянно употребляя потоки
получения, поток может быть перегружен задачами, включая
пробуждение других потоков.NDB:RecoveryWork
узла данных увеличено от 50 до 60, то есть, NDB
теперь использует 1.6 размера данных для хранения LCP.InsertRecoveryWork
обеспечивает дополнительные возможности тюнинга посредством управления
процентом RecoveryWork,
это резервируется для операций по вставке. Значение по умолчанию равняется 40
(то есть, 40% пространства памяти, уже зарезервированного
RecoveryWork),
минимум и максимум 0 и 70, соответственно. Увеличение этого значения
допускает больше записей во время LCP, ограничивая полный размер LCP.
Уменьшение InsertRecoveryWork
ограничивает количество записей во время LCP, но приводит к большему
количеству пространства, используемого для LCP, что означает, что
восстановление занимает больше времени.MaxDiskWriteSpeed увеличен до
MaxDiskWriteSpeedOtherNodeRestart.
Кроме того, минимальная скорость удвоена, и приоритет просмотров LCP и то,
что может быть написано за разрыв в реальном
времени, увеличены далее.MaxDiskWriteSpeed увеличен до
MaxDiskWriteSpeedOwnRestart,
MinDiskWriteSpeed
также установлен в это значение. Приоритет просмотров LCP и объема данных,
который может быть написан за разрыв в реальном времени, увеличен далее, и
буфер данных LCP доступен во время просмотра LCP.NDB:NDB
работать достоверно на системах, где доступное дисковое пространство
(в грубом минимуме) 2.1 объема памяти, ассигнованной
DataMemory.
Необходимо отметить, что это число НЕ
включает дисковое пространство, используемое для таблиц Disk Data.
--nodeid и
--backupid требуются, вызывая
ndb_restore.--num-slices
определяет количество частей, на которые должна быть
разделена резервная копия.--slice-id
обеспечивает ID части, которая будет восстановлена текущим экземпляром
ndb_restore.--num-slices.--check-missing.
Чтобы заменить любую недостающую часть заполнителями, используйте
--add-missing.
3.5. NDB: добавленные и удаленные опции, переменные и параметры
3.5.1. NDB 7.5
NDB и
mysqld, которые были добавлены
или удалены в NDB 7.5.
Параметры конфигурации узла, введенные в NDB 7.5
ApiVerbose: Позвольте отладку API NDB для развития NDB.
Добавлен в NDB 7.5.2.
Параметры конфигурации узла, устаревшие в NDB 7.5
ExecuteOnComputer
: Последовательность, ссылающаяся на более ранний определенный
COMPUTER. Устарела в NDB 7.5.0.
ExecuteOnComputer
: Последовательность, ссылающаяся на более ранний определенный
COMPUTER. Устарела в NDB 7.5.0.
ExecuteOnComputer
: Последовательность, ссылающаяся на более ранний определенный
COMPUTER. Устарела в NDB 7.5.0.
Параметры конфигурации узла, удаленные в NDB 7.5
DiskCheckpointSpeed:
Байты для записи контрольной точкой в секунду. Удален в NDB 7.5.0.
DiskCheckpointSpeedInRestart:
Байты для записи контрольной точкой в секунду во время перезапуска.
Удален в NDB 7.5.0.
Id:
Число, определяющее узел данных. Теперь устарело, используйте NodeId.
Удалено в NDB 7.5.0.MaxNoOfSavedEvents:
Удалено в NDB 7.5.0. Не использовалось.PortNumber: Порт для устаревшего
транспортера SCI. Удален в NDB 7.5.1.PortNumber: Порт для транспортера SHM.
Удален в NDB 7.5.1.
PortNumber: Порт для транспортера TCP. Удален в NDB 7.5.1.
ReservedSendBufferMemory:
Этот параметр присутствует в коде NDB, но не позволен и теперь устарел.
Удален в NDB 7.5.0.
Опции MySQL, добавленные в NDB 7.5
Ndb_system_name:
Формируемое имя кластерной системы, пустое, если сервер, не связан с NDB.
Добавлено в NDB 7.5.7.
ndb-allow-copying-alter-table: Установите в OFF, чтобы помешать
ALTER TABLE использовать копирование операций на таблицах NDB.
Добавлено в NDB 7.5.0.
ndb-cluster-connection-pool-nodeids:
Список разделенных запятой значений ID узла для связей с кластером,
используется MySQL, количество узлов в списке должно совпасть с набором
значений для --ndb-cluster-connection-pool. Добавлено в NDB 7.5.0.
ndb-default-column-format:
Используйте это значение (FIXED или DYNAMIC) по умолчанию для опций
COLUMN_FORMAT и ROW_FORMAT, создавая или добавляя колонки к таблице.
Добавлено в NDB 7.5.1.
ndb-log-update-minimal:
Писать обновления в минимальном формате. Добавлено в NDB 7.5.7.
ndb_data_node_neighbour:
Определяет узел данных о группе, "самый близкий" к этому MySQL
Server для операционного совета и полностью копируемых таблиц.
Добавлено в NDB 7.5.2.
ndb_default_column_format:
Формат строки по умолчанию и формат столбца (FIXED или DYNAMIC) для новых
таблиц NDB. Добавлено в NDB 7.5.1.
ndb_read_backup:
Позволить чтение из любой точной копии для всех таблиц NDB, используйте
NDB_TABLE=READ_BACKUP={0|1} с CREATE TABLE или ALTER TABLE,
чтобы позволить или отключить для отдельных таблиц NDB.
Добавлено в NDB 7.5.2.
Устаревшие опции MySQL Server в NDB 7.5
Удаленные опции MySQL Server в NDB 7.5
3.5.2. Опции, переменные и параметры добавленные, устаревшие или
удаленные в NDB 7.6
Параметры конфигурации узла, введенные в NDB 7.6
EnablePartialLcp:
Включить частичный LCP (true). Если выключено (false),
все LCP пишут полные контрольные точки. Добавлено в NDB 7.6.4.
EnableRedoControl:
Позвольте адаптивную скорость контрольных точек для управления использованием
журнала отката. Добавлено в NDB 7.6.7.
InsertRecoveryWork: Процент RecoveryWork
для вставленных строк, не имеет никакого эффекта, если частичные местные
контрольные точки не используются. Добавлено в NDB 7.6.5.
LocationDomainId:
Назначьте этот узел API на определенную область доступности или зону.
0 (умолчание) сбрасывает привязку. Добавлено в NDB 7.6.4.
LocationDomainId:
Назначьте этот узел управления на определенную область доступности или зону.
0 (умолчание) сбрасывает привязку. Добавлено в NDB 7.6.4.
LocationDomainId:
Назначьте этот узел данных на определенную область доступности или зону.
0 (умолчание) сбрасывает привязку. Добавлено в NDB 7.6.4.
MaxFKBuildBatchSize:
Максимальный пакетный размер просмотра, чтобы использовать для создания
внешних ключей. Увеличивание этого значения может ускорить создание
внешних ключей, но влияет на трафик. Добавлено в NDB 7.6.4.
MaxReorgBuildBatchSize:
Максимальный пакетный размер просмотра, чтобы использовать для перестройки
разделения таблицы. Увеличивание этого значения может ускорить перестройку
разделения таблицы, но влияет на трафик. Добавлено в NDB 7.6.4.
MaxUIBuildBatchSize:
Максимальный пакетный размер просмотра, чтобы использовать для создания
уникальных ключей. Увеличивание этого значения может ускорить создание
уникальных ключей, но влияет на трафик. Добавлено в NDB 7.6.4.
ODirectSyncFlag: Записи O_DIRECT рассматриваются как
синхронные, проигнорировано, когда ODirect не позволен, InitFragmentLogFiles
установлен в SPARSE или то и другое. Добавлено в NDB 7.6.4.
PreSendChecksum:
Если этот параметр и Checksum позволены,
предварительно посылают проверки контрольной суммы и проверяют все сигналы
SHM между узлами на ошибки. Добавлено в NDB 7.6.6.
PreSendChecksum:
Если этот параметр и Checksum позволены,
предварительно посылают проверки контрольной суммы и проверяют все сигналы
TCP между узлами на ошибки. Добавлено в NDB 7.6.6.
RecoveryWork: Процент издержек хранения для файлов LCP: большее
значение означает меньше работы в нормальном функционировании, но больше
работы во время восстановления. Добавлено в NDB 7.6.4.
SendBufferMemory
: Байты в общей памяти буфера
для сигналов, посланных из этого узла. Добавлено в NDB 7.6.6.
ShmSpinTime: При получении сколько секунд ждать перед сном.
Добавлено в NDB 7.6.6.
UseShm: Используйте сопряжения с общей памятью между этим узлом
данных и узлом API на этом хосте. Добавлено в NDB 7.6.6.
WatchDogImmediateKill:
Когда true, потоки немедленно убиты каждый раз, когда охранительные проблемы
происходят, используемый для тестирования и отладки.
Добавлено в NDB 7.6.7.
Параметры конфигурации узла, устаревшие в NDB 7.6
BackupDataBufferSize:
Размер по умолчанию буфера данных для резервной копии (в байтах).
Устарел в NDB 7.6.4.
BackupMaxWriteSize
: Максимальный размер записей файловой системы,
сделанный резервной копией (в байтах). Устарел в NDB 7.6.4.
BackupWriteSize
: Размер по умолчанию записей файловой системы, сделанный резервной
копией (в байтах). Устарел в NDB 7.6.4.
IndexMemory:
Число байтов на каждом узле данных ассигнуется для хранения индексов,
зависит от доступной системе RAM и размера DataMemory.
Устарел в NDB 7.6.2.
Signum: Номер сигнала, которое будет использоваться для передачи
сигналов. Устарел в NDB 7.6.6.
Параметры конфигурации узла, удаленные в NDB 7.6
Опции и переменные MySQL Server,
добавленные в NDB 7.6
Ndb_system_name:
Формируемое имя кластерной системы, пусто, если сервер, не связан с
NDB. Добавлено в NDB 7.6.2.
ndb-log-update-minimal:
Писать обновления в минимальном формате. Добавлено в NDB 7.6.3.
ndb_row_checksum:
Когда позволено (по умолчанию), установить контрольные суммы строки.
Добавлено в NDB 7.6.8.
Опции и переменные MySQL Server, устаревшие в NDB 7.6
Опции и переменные MySQL Server, удаленные в NDB 7.6
3.6. MySQL Server, использующий InnoDB по сравнению с NDB Cluster
NDB и
InnoDB
могут служить транзакционными механизмами хранения MySQL пользователям
MySQL Server в NDB Cluster. Они видят
NDB
как возможную альтернативу или модернизацию механизма хранения по умолчанию
InnoDB
в MySQL 5.7. В то время, как NDB
и InnoDB
разделяют общие характеристики, есть различия в архитектуре и внедрении,
чтобы некоторые существующие приложения MySQL Server
и сценарии использования могли быть подходящим вариантом для NDB Cluster.NDB в NDB 7.5 и
InnoDB в MySQL 5.7.
Следующие несколько секций обеспечивают техническое сравнение. Во многих
случаях решение о том, когда и где использовать NDB Cluster, должно быть
сделано в зависимости от конкретного случая, приняв все факторы во внимание.
В то время, как это выходит за рамки этой документации, чтобы обеспечить
специфические особенности для каждого мыслимого сценария использования, мы
также пытаемся предложить некоторое очень общее руководство по относительной
пригодности некоторых общих типов приложений для
NDB в противоположность
InnoDB.InnoDB 1.1.
В то время как возможно использовать таблицы
InnoDB с NDB Cluster,
такие таблицы не сгруппированы. Также невозможно использовать программы или
библиотеки от NDB Cluster 7.5 с MySQL Server 5.7 или наоборот.InnoDB), но
есть некоторые важные различия, архитектурные и во внедрении.
Раздел 3.6.1
предоставляет резюме этих различий. Из-за различий, некоторые сценарии
использования явно более подходят для одного или другого механизма,
посмотрите
раздел 3.6.2. Это в свою очередь оказывает влияние на типы
запросов, которые лучше подошли для использования с
NDB или
InnoDB. См.
раздел 3.6.3
для сравнения относительной пригодности каждого для использования в общих
типах приложений базы данных.NDB и
MEMORY см.
When to Use MEMORY or NDB Cluster.
3.6.1. Разница между NDB и InnoDB
NDB
осуществляется, используя распределенную и разделенную
архитектуру, которая заставляет его вести себя по-другому по сравнению с
InnoDB.
Для непривычных к работе с
NDB,
неожиданные поведения могут возникнуть из-за его распределенного характера
относительно транзакций, внешних ключей, пределов таблицы и других
особенностей. Их показывают в следующей таблице:Фишка
InnoDB (MySQL 5.7)NDB 7.5/7.6Версия MySQL Server
5.7 5.7 Версия
InnoDBInnoDB 5.7.30InnoDB 5.7.30Версия NDB Cluster
N/A
NDB
7.5.17/7.6.13Пределы хранения
64 TB 128 TB (с NDB 7.5.2) Внешние ключи
Да Да Транзакции
Все стандартные типы
READ COMMITTEDMVCC
Да Нет Сжатие данных
Да Нет (но файлы контрольной точки NDB и резервные файлы
могут быть сжаты)
Поддержка больших строк (> 14K)
Да для столбцов типов
VARBINARY,
VARCHAR,
BLOB и
TEXTДа для столбцов типов
BLOB и
TEXT.
Используя эти типы, чтобы сохранить очень большие объемы данных, можно
понизить производительность NDB.Репликация
Использование асинхронной и полусинхронной репликации MySQL,
MySQL Group Replication
Автоматическая синхронная репликация в NDB Cluster,
асинхронная репликация между NDB Cluster, используя MySQL Replication
(полусинхронная репликация не поддерживается)
Scaleout для операций чтения
Да (MySQL Replication)
Да (автоматическое разделение в NDB Cluster,
NDB Cluster Replication) Scaleout для операций записи
Требует разделения уровня приложения.
Да (автоматическое разделение в NDB Cluster). High Availability (HA)
Встроено от InnoDB cluster.
Да (разработано для продолжительности работы на 99.999%).
Восстановление после сбоя узла и отказоустойчивость
Из MySQL Group Replication.
Автоматически (основной элемент в архитектуре NDB).
Время для восстановления после сбоя узла
30 секунд или дольше Обычно < 1 секунды
Работа в реальном времени
Нет Да Таблицы In-Memory
Нет
Да (некоторые данные могут произвольно храниться на диске,
хранение данных в памяти и дисковое хранение данных совместимы)
Доступ NoSQL к механизму хранения Да
Да (много API, включая Memcached, Node.js/JavaScript, Java, JPA,
C++ и HTTP/REST)
Параллельные записи и доступ Да
До 48 параллельных записей
Обнаружение конфликта и решение (многократные ведущие репликации)
Да (MySQL Group Replication) Да Хэш-индексы
Нет Да Добавление узлов онлайн
Использование точных копий чтения-записи MySQL Group Replication
Да (все типы узлов) Модернизации онлайн
Да (с использованием репликации)
Да Модификации схемы онлайн
Да, как часть MySQL 5.7
Да
3.6.2. NDB и рабочая нагрузка InnoDB
NDB и
InnoDB
относительно некоторых общих типов управляемых базой данных рабочих нагрузок
приложений показывают в следующей таблице:
Нагрузка
InnoDBNDB Cluster ( NDB
)
High-Volume OLTP Applications
Да Да DSS Applications
(data marts, analytics)
Да
Ограничено (операции по соединению через наборы данных OLTP не
больше 3 TB в размере)
Пользовательские приложения
Да Да Пакетные приложения
Да
Ограничено (должен быть доступ главным образом первичного ключа).
NDB Cluster 7.5 понимает внешние ключи
In-Network Telecoms Applications (HLR, HSS, SDP)
Нет Да
Управление сеансами и кэширование
Да Да E-Commerce
Да Да
Управление профилем пользователя, протокол AAA
Да Да
3.6.3. Резюме использования особенностей NDB и InnoDB
InnoDB и
NDB, некоторые задачи
явно более совместимы с одним механизмом хранения, чем с другим.
Требования предпочтительного приложения для
InnoDBТребования предпочтительного приложения для
NDBREAD COMMITTED
BLOB
3.7. Известные ограничения NDB Cluster
MyISAM и
InnoDB. Если вы проверяете категорию
Cluster в базе данных глюков MySQL на
http://bugs.mysql.com,
можно найти известные ошибки в следующих категориях под
MySQL Server: в базе данных ошибок MySQL на
http://bugs.mysql.com,
которые мы намереваемся исправить в предстоящих выпусках NDB Cluster:
3.7.1. Несоблюдение синтаксиса SQL в NDB Cluster
NDB,
как описано в следующем списке:NDB
или изменить существующую временную таблицу, чтобы использовать
NDB
терпит неудачу с ошибкой
Table storage engine 'ndbcluster' does not
support the create option 'TEMPORARY'.NDB, ширина которого больше 3072 байт, достигает
цели, но только первые 3072 байта на самом деле используются для индекса.
В таких случаях предупреждение Specified key was too
long; max key length is 3072 bytes выпущено и
SHOW CREATE TABLE
показывает длину индекса как 3072.NDB, которые используют
любой из типов TEXT или
BLOB.NDB не поддерживает
индексы FULLTEXT, которые возможны для
MyISAM и
InnoDB.VARCHAR таблиц
NDB.NOT NULL или пересоздайте
индекс без опции USING HASH.NDB всегда то же самое, как ширина колонки в
байтах, но максимум 3072 байта, как описано ранее в этой секции.
Также посмотрите
раздел 3.7.6.BIT не могут быть первичным
ключом, уникальным ключом или индексом, при этом это не может быть частью
сложного первичного ключа, уникального ключа или индекса.NDB
может обращаться максимум с одним столбцом
AUTO_INCREMENT на таблицу. Однако в случае
таблицы NDB без явного первичного ключа столбец
AUTO_INCREMENT
автоматически определяется и используется в качестве
скрытого первичного ключа. Поэтому вы не можете
определить таблицу, у которой есть явное столбец
AUTO_INCREMENT, если эта колонка не объявлена,
используя PRIMARY KEY.
Попытка составить таблицу с AUTO_INCREMENT,
который не является первичным ключом таблицы и использованием
NDB
терпит неудачу с ошибкой.InnoDB:ON UPDATE CASCADE
не поддерживается, когда ссылка к первичному ключу родительской таблицы.NDB, которое рассматривает эти две строки
как одну и таким образом не имеет никакого способа знать, что это обновление
должно быть каскадом.ON DELETE
CASCADE не поддерживается, где дочерняя таблица содержит одну или
более колонок любого из типов
TEXT или
BLOB
(Bug #89511, Bug #27484882).SET DEFAULT не поддерживается.
Также не поддержано
InnoDB.NO ACTION
принимаются, но рассматривают как RESTRICT.
Также, как и в InnoDB.ALTER TABLE,
метаданные родительской таблицы не обновляются, что позволяет впоследствии
выполнить ALTER TABLE для родителя, что должно
быть недействительным. Чтобы обойти эту проблему, надо выполнить
SHOW CREATE TABLE
на родительской таблице немедленно после добавления или удаления
внешнего ключа, это вынуждает метаданные родителя быть перезагруженными.WKT и
WKB) поддерживаются для таблиц
NDB.
Однако, пространственные индексы не поддерживаются.ndb_apply_status и
ndb_binlog_index составлены, используя
набор символов latin1 (ASCII).
Поскольку названия журналов зарегистрированы в этой таблице, на двоичные
файлы журнала, названные, используя нелатинские символы, не ссылаются
правильно в этих таблицах. Это известная проблема,
которую мы решаем (Bug #50226).--basedir,
--log-bin или
--log-bin-index.LINEAR]
KEY. Используя любое другое разделение с
ENGINE=NDB или
ENGINE=NDBCLUSTER в
CREATE TABLE,
получите ошибку.KEY,
с использованием первичного ключа таблицы как ключа разделения.
Если никакой первичный ключ явно не установлен для таблицы,
скрытый первичный ключ, автоматически создан
NDB.
Для дополнительного обсуждения этих и связанных проблем посмотрите
KEY Partitioning.CREATE TABLE и
ALTER TABLE, которые создали
бы разделенную пользователями таблицу
NDBCLUSTER,
не разрешены и терпят неудачу с ошибкой, кроме как в следующих случаях:NDBCLUSTER
составлена, используя пустой список столбцов (то есть, используя
PARTITION BY [LINEAR] KEY()),
тогда никакой явный первичный ключ не требуется.NDBCLUSTER, используя
определенное пользователями разделение, 8 на группу узлов.
См. раздел 3.2.NDB через
ALTER TABLE ... DROP PARTITION.
Другие расширения разделения для
ALTER
TABLE ADD PARTITION,
REORGANIZE PARTITION и
COALESCE PARTITION
поддерживаются для таблиц NDB, но используют копирование и не оптимизированы.
См. Management of RANGE and LIST Partitions и
ALTER TABLE Statement.
NDB игнорирует значение
sql_log_bin.JSON поддерживается для таблиц
supported for NDB в
mysqld с NDB 7.5.2 и позже.NDB может иметь максимум 3
столбца JSON.JSON, которые это рассматривает просто как
данные BLOB. Обработка данных как
JSON должна быть выполнена приложением.ndbinfo, предоставляя сведения о CPU и
активных потоках узла, ID и типе потока.cpustat: Обеспечивает посекундную статистику
CPU на поток.cpustat_50ms:
Сырые данные о статистике CPU на поток, собранные каждые 50 мс.cpustat_1sec:
Сырые данные о статистике CPU на поток, собираемые каждую секунду.cpustat_20sec:
Сырые данные о статистике CPU на поток, собираемые каждые 20 секунд.threads:
Имена и описания типов потока.ndbinfo о блокировках в NDB Cluster:cluster_locks:
Текущие запросы блокировки, которые ждут или держат блокировку.
Эта информация может быть полезной, исследуя
мертвые блокировки. Аналогично
cluster_operations.locks_per_fragment:
Графы запросов требования блокировки и их результаты на фрагмент, а также
полное время на ожидание блокировок успешно и неудачно. Аналогично
operations_per_fragment и
memory_per_fragment.server_locks:
Подмножество транзакций, которые работают на местном
mysqld,
показывая id связи на транзакцию. Аналогично
server_operations.
3.7.2. Пределы и различия NDB Cluster от стандартного MySQL
NDB,
автоматически не восстановлена при удалении, как с другими механизмами
хранения. Вместо этого следующие правила сохраняются:DELETE на
NDB
делает память, используемую ранее удаленными строкими, доступной для
повторного использования вставками только на той же самой таблице.
Однако, эта память может быть сделана доступной для общего
повторного использования командой
OPTIMIZE TABLE.DROP TABLE или
TRUNCATE TABLE на
NDB
освобождает память, которая использовалась этой таблицей,
для повторного использования любой таблицей
NDB.TRUNCATE TABLE
удаляет и пересоздает таблицу, см.
TRUNCATE TABLE Statement.DataMemory и
IndexMemory).DataMemory
ассигнуется как страницы по 32 КБ. Когда страница
DataMemory используется,
она назначена на определенную таблицу. После того, как ассигнована, эта
память не может быть освобождена, кроме как удалив таблицу.MaxNoOfConcurrentOperations и
MaxNoOfLocalOperations.TRUNCATE TABLE и
ALTER TABLE
обработаны как особые случаи, управляя многократными транзакциями
и не подвергаются этому ограничению.MaxNoOfOrderedIndexes,
максимальное количество заказных индексов на таблицу равняется 16.
3.7.3. Пределы, касающиеся операционной обработки в NDB Cluster
NDBCLUSTER поддерживает
только уровень изоляции
READ COMMITTED.
InnoDB, например, поддерживает
READ COMMITTED,
READ UNCOMMITTED,
REPEATABLE READ и
SERIALIZABLE.
Необходимо иметь в виду, что NDB реализует
READ COMMITTED на основе строки.
Когда прочитанный запрос прибывает в узел данных, хранящий строку, то
что возвращено, является последней переданной версией строки в то время.SELECT ... LOCK IN SHARE MODE.
В таких случаях проводится блокировка, пока транзакция не передается.
Использование блокировки строки может также вызвать следующие проблемы:MaxNoOfConcurrentOperations.NDB применяет READ
COMMITTED поскольку все читают, если применен такой модификатор, как
LOCK IN SHARE MODE или
FOR UPDATE.
LOCK IN SHARE MODE
предписывает разделить блокировки строки, которые будут использоваться.
FOR UPDATE
заставляет исключительные блокировки строки использоваться. Чтения
уникального ключа обновляют блокировки автоматически, чтобы
гарантировать последовательное чтение. Чтение
BLOB также использует дополнительные
блокировки для последовательности.NDB.NDBCLUSTER
хранит только часть значения столбца, которое использует любой из MySQL-типов
BLOB или
TEXT
в таблице, видимой MySQL, остаток от
BLOB или
TEXT хранится
в отдельной внутренней таблице, которая недоступна для MySQL. Это дает начало
двум связанным проблемам, о которых необходимо знать, выполняя
SELECT
на таблицах, которые содержат колонки этих типов:SELECT из таблицы
NDB Cluster: если
SELECT включает
BLOB или
TEXT, уровень изоляции
READ COMMITTED
преобразовывается в read с read lock.
Это сделано, чтобы гарантировать последовательность.SELECT,
который использует поиск уникального ключа, чтобы получить любые колонки,
которые используют любой из типов
BLOB или
TEXT
и это выполняются в транзакции, разделяемая блокировка чтения
проводится в таблице на время транзакции то есть, пока транзакция не
передается или прерывается.NDB со столбцами
BLOB или
TEXT.t, определенную
CREATE TABLE:
CREATE TABLE t (a INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
b INT NOT NULL, c INT NOT NULL, d TEXT,
INDEX i(b), UNIQUE KEY u(c)) ENGINE = NDB,
t
вызывает общую блокировку чтения, потому что первый запрос использует поиск
первичного ключа, а второй использует поиск уникального ключа:
SELECT * FROM t WHERE a = 1;
SELECT * FROM t WHERE c = 1;
SELECT * FROM t WHERE b = 1;
SELECT * FROM t WHERE d = '1';
SELECT * FROM t;
SELECT b, c WHERE a = 1;
BLOB или
TEXT.BLOB или
TEXT или в случаях, где такие
запросы непреодолимы, передавая транзакции как можно скорее.
InnoDB.TRUNCATE TABLE
не транзакционное, когда используется на таблицах
NDB. Если
TRUNCATE TABLE
не освобождает таблицу, тогда он должен быть запущен повторно, пока это
не выполнится успешно.DELETE FROM (даже без
WHERE)
транзакционно.
Для таблиц, содержащих очень много строк, можно найти, что работа улучшена
при помощи нескольких DELETE FROM ... LIMIT ...,
чтобы удалять по кускам. Если ваша цель состоит в том, чтобы освободить
таблицу, то можно хотеть использовать
TRUNCATE TABLE.LOAD DATA
не транзакционное, когда используется на
NDB.LOAD DATA механизм
NDB
передает в нерегулярных интервалах, которые позволяют лучшее использование
коммуникационной сети. Невозможно знать заранее,
когда передача происходит.NDB
как часть ALTER TABLE,
создание копии нетранзакционное. В любом случае эта операция отменена до
прежнего уровня, когда копия удалена.COUNT() на ведомом.
Другими словами, выполняя на ведущем ряд запросов
(INSERT,
DELETE или вместе),
которые изменяят количество строк в таблице в единственной транзакции,
запросы SELECT COUNT(*) FROM
на ведомом могут привести к промежуточным результатам. Это вследствие того,
что tableSELECT COUNT(...)
может выполнить грязные чтения, а не ошибки в
NDB
(см. Bug #31321).
3.7.4. Обработка ошибок NDB Cluster
3.7.5. Пределы, связанные с объектами базы данных в NDB Cluster
NDBCLUSTER:NDB,
максимальная позволенная длина для имен базы данных и для имен таблиц
является 63 знаками. Запрос, используя имя базы данных или имя таблицы
больше, чем этот предел, терпит неудачу с соответствующей ошибкой.NDB в NDB Cluster,
включая базы данных, таблицы и индексы ограничивается 20320.BLOB или
TEXT
добавляет 256 + 8 = 264 байта к этому общему количеству, это включает столбцы
JSON. См.
String Type Storage Requirements, а также
as JSON Storage Requirements.NDB 8188 байт,
попытка составить таблицу, которая нарушает это ограничение, терпит неудачу с
ошибкой NDB error 851 Maximum offset for fixed-size
columns exceeded. Для основанных на памяти колонок можно обойти это
при помощи типа столбца переменной ширины, например,
VARCHAR
или определение колонки как
COLUMN_FORMAT=DYNAMIC. Это не работает с
колонками, сохраненными на диске. Для находящихся на диске колонок можно
сделать так, переупорядочивая один или больше находящихся на диске колонок
таблицы, таким образом что объединенная ширина всех, кроме находящейся на
диске колонки, определенной в последний раз в
CREATE TABLE,
используемом, чтобы составить таблицу, не превышает 8188 байтов, меньше
возможного округления, выполненного для некоторых типов данных, например,
CHAR или
VARCHAR. Иначе необходимо использовать
основанное на памяти хранение для одной или больше
колонок вместо этого.BIT в таблице
NDB 4096.FIXED. Раньше было 16 GB.
3.7.6. Неподдержанные или недостающие возможности NDB Cluster
NDB.
Попытка использовать любую из этих функций в NDB Cluster
не вызывает ошибки, однако, ошибки могут произойти в запросе, который
ожидает, что особенности будут поддержаны или проведены в жизнь. Запросы,
ссылающиеся на такие особенности, даже если эффективно проигнорированы
NDB, должны быть синтаксически и в
других отношениях действительны.NDB. Если префикс используется в качестве части
спецификации индекса в запросе типа
CREATE TABLE,
ALTER TABLE или
CREATE INDEX,
префикс не создается NDB.NDB, должен быть синтаксически действительным.
Например, следующий запрос всегда вернет ошибку Error 1089
Incorrect prefix
key; the used key part isn't a string, the used length is
longer than the key part, or the storage engine doesn't
support unique prefix keys, независимо от механизма хранения:
CREATE TABLE t1 (c1 INT NOT NULL, c2 VARCHAR(100), INDEX i1 (c2(500)));
MyISAM.--binlog-format=ROW (или
--binlog-format=MIXED),
настраивая репликация группы. См. главу 8.NDB,
поскольку это, очень вероятно, вызовет проблемы, включая неудачу
NDB Cluster Replication.NDB не поддерживает индексы на
виртуальных произведенных колонках.NDB применяет
DataMemory для хранения произведенной колонки, а также
IndexMemory для индекса. См.
JSON columns and indirect indexing in NDB Cluster.NDB
и другими механизмами хранения MySQL.NDB.
3.7.7. Ограничения, касающиеся работы в NDB Cluster
NDB,
также относительно более дорого сделать много просмотров диапазона, чем
это с MyISAM или
InnoDB.Records in range
доступна, но не полностью проверена или официально поддержана.
Это может привести к неоптимальным планам запросов в некоторых случаях.
Если необходимо, можно использовать USE
INDEX или FORCE INDEX, чтобы
изменить план выполнения. Посмотрите
Index Hints.USING HASH,
не могут использоваться для доступа к таблице, если
NULL дан как часть ключа.
3.7.8. Проблемы именно с NDB Cluster
NDB:sql_log_bin
не имеет никакого эффекта на операции по данным,
однако, это поддерживается для операций по схеме.BLOB,
но без первичного ключа.NoOfReplicas, это
количество копий всех данных, хранимых NDB Cluster.
Устанавливая этот параметр в 1 есть только единственная копия,
в этом случае никакая избыточность не обеспечивается, и потеря узла данных
влечет за собой потерю данных. Чтобы гарантировать избыточность и таким
образом сохранение данных, даже если узел данных терпит неудачу, установите
этот параметр в 2, что является умолчанием
и рекомендуемым значением в производстве.NoOfReplicas
к значению, больше 2 возможно (максимум к 4), но излишни,
чтобы принять меры против потери данных. Кроме того,
значения больше 2 для этого параметра
не поддерживаются в производстве.
3.7.9. Ограничения, касающиеся хранения данных NDB Cluster на диске
DataMemory. Использование совпадает с местом
для данных в оперативной памяти.DiskPageBufferMemory;
необходимо зарезервировать достаточно для этого параметра, чтобы составлять
всю память, используемую всеми экстентами
(количество экстентов*размер экстента).
3.7.10. Ограничения, касающиеся многократных узлов NDB Cluster
NDBCLUSTER:LOCK TABLES
работает только для узла SQL, на котором выпущена блокировка, никакой другой
узел SQL в кластере не видит
блокировку. Это также верно для блокировки, выпущенной любым запросом,
который блокирует таблицу как часть его действий.ALTER TABLE
не полностью блокирует, управляя многократными серверами MySQL (узлы SQL).
Как обсуждено в предыдущем пункте, NDB Cluster
не поддерживает распределенные блокировки таблицы.--reload и
--initial
проигнорированы, если сервер управления не единственный.
Это также означает, что, выполняя катящийся перезапуск NDB Cluster
с многократными узлами управления, сервер управления читает свой собственный
конфигурационный файл, если (и только если) это единственный сервер
управления, работающий в этом NDB Cluster. См.
раздел 7.5.
[tcp] для каждого подключения в
config.ini. См.
раздел 5.3.10.
| Найди своих коллег! |
Вы можете
направить письмо администратору этой странички, Алексею Паутову.
![]()